
Fig. 2.
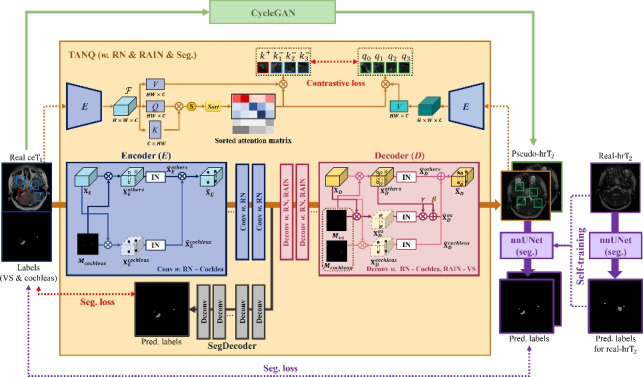
Our proposed framework consists of three main parts: 1) TANQ-based image translation from to images, 2) Multi-view pseudo- representation via CycleGAN, 3) Construction of a VS/cochlea segmentation model using multi-view pseudo- images and self-training with real- images. Specifically, TANQ divides the features based on the labels in both the encoder and decoder, applying target-aware normalization. Furthermore, it includes an additional decoder called SegDecoder. The Encoder E extracts features from both the real images and pseudo- images and then calculates the contrastive loss between selected features using a sorted attention matrix.