
FIGURE 2.
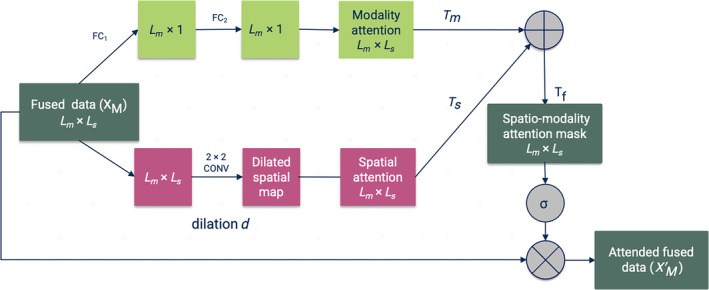
Our proposed spatio‐modality attention module for multimodal fusion. The concatenated embeddings are sent through two different branches. (i) The modality branch that learns the cross‐modality interactions and mounts it into attention mask and (ii) the spatial branch () captures the relevant context from each biological site. These two masks are merged into a final attention mask The spatial branch uses dilated convolution for learning the contextual understanding of the multimodal tensor and fully connected layer for modality attention.