

ABSTRACT
Response-adaptive randomization (RAR) has been studied extensively in conventional, single-stage clinical trials, where it has been shown to yield ethical and statistical benefits, especially in trials with many treatment arms. However, RAR and its potential benefits are understudied in sequential multiple assignment randomized trials (SMARTs), which are the gold-standard trial design for evaluation of multi-stage treatment regimes. We propose a suite of RAR algorithms for SMARTs based on Thompson Sampling (TS), a widely used RAR method in single-stage trials in which treatment randomization probabilities are aligned with the estimated probability that the treatment is optimal. We focus on two common objectives in SMARTs: (1) comparison of the regimes embedded in the trial and (2) estimation of an optimal embedded regime. We develop valid post-study inferential procedures for treatment regimes under the proposed algorithms. This is nontrivial, as even in single-stage settings standard estimators of an average treatment effect can have nonnormal asymptotic behavior under RAR. Our algorithms are the first for RAR in multi-stage trials that account for non-standard limiting behavior due to RAR. Empirical studies based on real-world SMARTs show that TS can improve in-trial subject outcomes without sacrificing efficiency for post-trial comparisons.
Keywords: inverse probability weighted estimator; precision medicine; response-adaptive randomization, treatment regime
1. INTRODUCTION
A treatment regime is a sequence of decision rules, one for each key decision point in a patient’s disease progression, that maps accumulated information on a patient to a recommended treatment (Tsiatis et al., 2020). Sequential multiple assignment randomized trials (SMARTs) are the gold standard for the study of treatment regimes (Murphy, 2005) and have been applied in a range of areas, including cancer, addiction, and HIV/prevention (eg, Bigirumurame et al., 2022; Kidwell, 2014; Lorenzoni et al., 2023). A SMART involves multiple stages of randomization, each stage corresponding to a decision point, where the sets of possible treatments may depend on baseline and interim information.
Figure 1 depicts a two-stage SMART to evaluate behavioral intervention strategies for cancer pain management (Somers et al., 2023). Subjects were randomized at baseline with equal probability to one of two first-stage interventions: Pain Coping Skills Training (PCST) with 5 sessions (PCST-Full, coded as 1) or one session (PCST-Brief, coded as 0). At the end of stage 1, subjects were classified as responders if they achieved a 30% reduction in pain score from baseline and as nonresponders otherwise. Subjects were then assigned with equal probability to one of two second-stage interventions depending on their first-stage intervention and response status. This design, like any fixed SMART design, can be represented as a single-stage trial in which subjects are randomized at baseline among a set of regimes known as the SMART’s embedded regimes (Tsiatis et al., 2020, Chapter 9). The cancer pain SMART has 8 embedded regimes determined by the stage 1 treatment and stage 2 treatments for responders and nonresponders, for example, one of these assigns PCST-Full initially followed by no further treatment if the subject responds and PCST-Plus otherwise. A key goal was to evaluate the embedded regimes based on mean percent reduction in pain from baseline at the end of stage 2 and to identify a regime yielding the greatest reduction.
FIGURE 1.

Schematic depicting the design of the SMART for evaluation of behavioral interventions for cancer pain management. The 8 embedded regimes implied by the design are of the form “Give a initially; if response, give b, otherwise if nonresponse give c,” where regimes 1,..., 8 correspond to  (0,0,1), (0,0,2), (0,1,2), (0,1,1), (1,3,4), (1,3,5), (1,4,5), and (1,4,4), respectively. At stage 2, 0 = no further intervention with PCST-Brief, 1 = PCST-Brief Maintenance, 2 = PCST-Full, 3 = no further intervention with PCST-Full, 4 = PCST-Full Maintenance, and 5 = PCST-Plus.
(0,0,1), (0,0,2), (0,1,2), (0,1,1), (1,3,4), (1,3,5), (1,4,5), and (1,4,4), respectively. At stage 2, 0 = no further intervention with PCST-Brief, 1 = PCST-Brief Maintenance, 2 = PCST-Full, 3 = no further intervention with PCST-Full, 4 = PCST-Full Maintenance, and 5 = PCST-Plus.
As in this example, most SMARTs use fixed randomization probabilities at each stage. Although fixed and balanced randomization in SMARTs yields high power for comparing treatments and treatment regimes (Murphy, 2005), updating randomization probabilities based on accruing information can improve outcomes for trial subjects, increase enrollment, and decrease dropout (Food and Drug Administration, 2019). Response-adaptive randomization (RAR) uses accumulating information to skew randomization probabilities toward promising treatments and has long been used in single-stage randomized clinical trials (RCTs, Berry, 2015; Kim et al., 2011; Wang and Yee, 2019); the large literature on RAR is reviewed for single-stage RCTs by Hu and Rosenberger (2006), Berry et al. (2010), and Atkinson and Biswas (2013). RAR procedures are typically formalized as a multi-arm bandit in which each treatment option is a bandit “arm” (Berry and Fristedt, 1985; Lattimore and Szepesvári, 2020; Villar et al., 2015a). The advantages of RAR are most pronounced in single-stage RCTs with a large number of treatments, as RAR algorithms oversample more favorable treatments and undersample less favorable ones (Berry, 2011). RAR also presents challenges, for example, early evidence can lead the randomization to become “stuck,” favoring suboptimal treatments (Thall et al., 2015 ), and there have been spirited debates about its potential pitfalls (Proschan and Evans, 2020; Viele et al., 2020; Villar et al., 2021).
As the number of regimes evaluated in a SMART can be large, the use of RAR in SMARTs could have great benefits, but development is limited. Cheung et al. (2014) propose SMART-AR, an RAR method based on Q-learning (eg, Tsiatis et al., 2020, Section 5.7.1) that adapts randomization probabilities to favor treatments with large estimated Q-functions. However, the approach does not account for uncertainty in the estimated Q-functions nor the potential information gain associated with each treatment, so may be inefficient. Wang et al. (2022) propose RA-SMART, an RAR method for two-stage SMARTs with the same treatments at each stage. The method does not incorporate delayed effects, that is, it does not account for treatment effects at stage 2 that depend on stage 1 treatment. Because interactions among treatments at different stages are key to development of treatment regimes, RAR schemes that acknowledge delayed effects are desirable.
We propose RAR approaches for SMARTs based on Thompson sampling (TS, Thompson, 1933), a bandit algorithm also known as probability matching (Russo et al., 2018) that is a popular basis for RAR in single-stage RCTs (Villar et al., 2015b; Wang, 2021; Williamson and Villar, 2020). The premise of TS is that a treatment’s randomization probability should be based on confidence that the treatment is optimal. Classical TS measures confidence with a posterior probability; aligned with standard SMART methodology, we adopt a frequentist perspective in which confidence is assessed using a confidence distribution (Xie and Singh, 2013). The methods are applicable to SMARTs to evaluate a fixed set of treatment regimes and/or identify an optimal regime and account for delayed effects.
In Section 2, we present the statistical framework and a variant of TS for SMARTs, and we use the latter in Section 3 to construct the proposed RAR approaches. One class of methods randomizes subjects up-front to entire embedded regimes, while the other sequentially randomizes subjects at each decision point. We propose estimators for the marginal mean outcome under a regime in Section 3 and argue in Section 4 that they are consistent and asymptotically normal; this is nontrivial, as adaptive randomization can lead to nonnormal limits for plug-in estimators (Hadad et al., 2021; Zhang et al., 2021b). Simulations demonstrating performance are reported in Section 5.
2. BACKGROUND AND PRELIMINARIES
2.1. Notation and assumptions
We first review SMARTs with fixed (ie, nonadaptive) randomization. For a SMART with K stages, let  be the (finite) set of available treatment options at stage
be the (finite) set of available treatment options at stage  . For a given subject, let
. For a given subject, let  be the treatment assigned at stage k, and let
be the treatment assigned at stage k, and let  denote all treatments given through stage k. Let
denote all treatments given through stage k. Let  be a set of baseline variables collected on the subject prior to stage 1 treatment, and let
be a set of baseline variables collected on the subject prior to stage 1 treatment, and let  comprise variables collected between stages
comprise variables collected between stages  and k,
and k,  . Define
. Define  ,
,  ; and let
; and let  and
and  ,
,  , denote the information at the time
, denote the information at the time  is assigned, with
is assigned, with  denoting the domain of
denoting the domain of  ,
,  . Let Y be the real-valued outcome of interest, which is measured or constructed from
. Let Y be the real-valued outcome of interest, which is measured or constructed from  and information measured after stage K at a specified follow-up time, coded so that larger values are favorable. Elements of
and information measured after stage K at a specified follow-up time, coded so that larger values are favorable. Elements of  may include current and past measures of the subject’s health status, previous measures of the outcome, and response status. For a subject with history
may include current and past measures of the subject’s health status, previous measures of the outcome, and response status. For a subject with history  at stage k,
at stage k,  is the set of feasible treatment options in
is the set of feasible treatment options in  , where
, where  maps
maps  to subsets of
to subsets of  (Tsiatis et al., 2020, Section 6.2.2). For example, at stage
(Tsiatis et al., 2020, Section 6.2.2). For example, at stage  of the cancer pain SMART,
of the cancer pain SMART,  for a subject who does not respond to intervention 0 given at the first stage. At stage k, a subject is randomized to option
for a subject who does not respond to intervention 0 given at the first stage. At stage k, a subject is randomized to option  with probability
with probability  ; often,
; often,  for all k.
for all k.
A decision rule  maps an individual’s history to a recommended treatment at stage k, where
maps an individual’s history to a recommended treatment at stage k, where  for all
for all  . A treatment regime
. A treatment regime  is a sequence of decision rules, where
is a sequence of decision rules, where  is the rule for stage k,
is the rule for stage k,  . The mean outcome that would be achieved if the population were to receive treatment according to
. The mean outcome that would be achieved if the population were to receive treatment according to  can be characterized in terms of potential outcomes. For any
can be characterized in terms of potential outcomes. For any  , let
, let  denote the potential subject information that would accrue between stages
denote the potential subject information that would accrue between stages  and k, and define
and k, and define  ,
,  . The potential history at stage
. The potential history at stage  is thus
is thus  , with
, with  . For any
. For any  , let
, let  be the potential outcome that would be achieved under
be the potential outcome that would be achieved under  . For
. For  , the potential accrued information between stages
, the potential accrued information between stages  and k under regime
and k under regime  is then
is then  , and the potential outcome under
, and the potential outcome under  is
is  , where
, where  is the indicator function. The mean outcome for regime
is the indicator function. The mean outcome for regime  , known as the value of
, known as the value of  , is
, is  .
.
Define  for all
for all  to be the set of all potential outcomes. For a given regime
to be the set of all potential outcomes. For a given regime  , identification of
, identification of  is possible from the data
is possible from the data  under the following assumptions, which are discussed extensively elsewhere (eg, Tsiatis et al., 2020, Section 6.2.4) and which we adopt: (1) consistency,
under the following assumptions, which are discussed extensively elsewhere (eg, Tsiatis et al., 2020, Section 6.2.4) and which we adopt: (1) consistency,  ,
,  ,
,  ; (2) positivity,
; (2) positivity,  for all
for all  and all
and all  ,
,  ; and (3) sequential ignorability,
; and (3) sequential ignorability,  ,
,  , where “
, where “ ” denotes statistical independence. We also assume that there is no interference among individuals nor multiple versions of a treatment. In a SMART with nonadaptive randomization, (1) is true by design, and (2) is guaranteed by randomization; with RAR, (3) holds if constraints are imposed on the randomization probabilities (discussed shortly) and (4) holds because randomization probabilities are known features of the history.
” denotes statistical independence. We also assume that there is no interference among individuals nor multiple versions of a treatment. In a SMART with nonadaptive randomization, (1) is true by design, and (2) is guaranteed by randomization; with RAR, (3) holds if constraints are imposed on the randomization probabilities (discussed shortly) and (4) holds because randomization probabilities are known features of the history.
Denote the m regimes embedded in a SMART as  . A common primary analysis is the comparison of
. A common primary analysis is the comparison of  ,
,  , that is, the mean outcomes that would be achieved if the population were to receive treatments according to
, that is, the mean outcomes that would be achieved if the population were to receive treatments according to  . Another common analysis is identification of an optimal embedded regime,
. Another common analysis is identification of an optimal embedded regime,  , satisfying
, satisfying  ,
,  .
.
2.2. Subject accrual and progression processes
Ordinarily, it is assumed that subjects enroll in a clinical trial by a completely random process over a planned accrual period. Under such a process, subjects in a SMART progress through the stages in a staggered fashion. Thus, at any point during the trial, enrolled subjects will have reached different stages, with only some having the outcome Y ascertained. By reaching stage k, we mean that a subject has completed the previous stages and that  has been assigned. For example, in a SMART with
has been assigned. For example, in a SMART with  stages, at any time, there may be subjects who have received only a first-stage treatment, for whom
stages, at any time, there may be subjects who have received only a first-stage treatment, for whom  is available; subjects who have reached stage 2 but have not completed follow-up, for whom
is available; subjects who have reached stage 2 but have not completed follow-up, for whom  is available; and subjects who have completed the trial, for whom
is available; and subjects who have completed the trial, for whom  is available.
is available.
Ideally, randomization probabilities would be updated each time a new randomization is needed. However, it may be more feasible in practice to update the probabilities only periodically; see Web Appendix A of the Supplementary Material for discussion. For definiteness, we consider a SMART that will enroll N subjects over T weeks, with randomization probabilities updated weekly. We develop two RAR randomization schemes: the first, which we term up-front, randomizes subjects to an embedded regime at baseline; the second, termed sequential, randomizes subjects at each stage. While these two schemes are equivalent in a SMART with fixed randomization probabilities, the sequential scheme under RAR allows a subject’s probabilities to depend on information collected as they progress through the trial.
We assume that a group of subjects of random size enrolls at each week t and, depending on the randomization scheme, up-front or sequential, requires assignment to either an entire regime (up-front) or a stage 1 treatment (sequential) according to probabilities that are updated at t based on the accrued data from subjects previously enrolled at weeks  . Each of these subjects is assigned a regime (up-front) or
. Each of these subjects is assigned a regime (up-front) or  (sequential) using these probabilities. At each subsequent stage
(sequential) using these probabilities. At each subsequent stage  , we assume that there is a time interval, measured in weeks, between when
, we assume that there is a time interval, measured in weeks, between when  is assigned and when
is assigned and when  is ascertained and
is ascertained and  is assigned, as well as a follow-up period after
is assigned, as well as a follow-up period after  is assigned but before Y is recorded. Thus, under sequential randomization, these subjects will require randomization to
is assigned but before Y is recorded. Thus, under sequential randomization, these subjects will require randomization to  ,
,  , at a future week
, at a future week  , say, using probabilities based on the accrued data from subjects previously enrolled at or before week
, say, using probabilities based on the accrued data from subjects previously enrolled at or before week  .
.
To represent the data available on subjects who are already enrolled at any week t, let  be the indicator that a subject has enrolled in the SMART and been assigned to a regime or stage 1 treatment by week t (ie, at a week
be the indicator that a subject has enrolled in the SMART and been assigned to a regime or stage 1 treatment by week t (ie, at a week  ). For such subjects, let
). For such subjects, let  be the week of enrollment and assignment;
be the week of enrollment and assignment;  be the most recent stage reached by week t; and
be the most recent stage reached by week t; and  be the indicator that a subject has completed follow-up by week t, so that Y has been observed. The data available on a given subject at week t are then
be the indicator that a subject has completed follow-up by week t, so that Y has been observed. The data available on a given subject at week t are then  ;
;  is null if a subject has not yet enrolled by t. Indexing subjects by i, the accrued data from all previously enrolled subjects that can inform the randomization probabilities at week t are then
is null if a subject has not yet enrolled by t. Indexing subjects by i, the accrued data from all previously enrolled subjects that can inform the randomization probabilities at week t are then  .
.
2.3. Thompson sampling
The central idea of TS is to map a treatment’s randomization probability to the belief that it is optimal among the available options. This belief is represented conventionally by the posterior probability that a treatment is optimal in the sense that it optimizes expected outcome (Thompson, 1933). For example, in the up front case, let  be the estimated belief that treatment regime
be the estimated belief that treatment regime  is optimal at week t based on the accrued data
is optimal at week t based on the accrued data  from previously enrolled subjects (and similarly for treatment j in a single-stage RCT). Let
from previously enrolled subjects (and similarly for treatment j in a single-stage RCT). Let  be regime j’s randomization probability for subjects needing randomization at week t. Ordinarily,
be regime j’s randomization probability for subjects needing randomization at week t. Ordinarily,  is taken to be a monotone function of
is taken to be a monotone function of  ; a popular choice is
; a popular choice is  where
where  is a damping constant (Thall and Wathen, 2007). Smaller values of
is a damping constant (Thall and Wathen, 2007). Smaller values of  pull the probabilities toward uniform randomization; higher values pull them closer to the beliefs. The
pull the probabilities toward uniform randomization; higher values pull them closer to the beliefs. The  can be the same for all t or increase with t to impose greater adaptation as data accumulate. Because aggressive adaptation can lead to randomization probabilities approaching 0 or 1 for some regimes or treatments, limiting exploration of all options, one may impose clipping constants, that is, lower/upper bounds on the probabilities (Zhang et al., 2021a). This practice is consistent with the positivity assumption.
can be the same for all t or increase with t to impose greater adaptation as data accumulate. Because aggressive adaptation can lead to randomization probabilities approaching 0 or 1 for some regimes or treatments, limiting exploration of all options, one may impose clipping constants, that is, lower/upper bounds on the probabilities (Zhang et al., 2021a). This practice is consistent with the positivity assumption.
In a fully Bayesian formulation, beliefs  are estimated posterior probabilities based on
are estimated posterior probabilities based on  . We propose a frequentist analog based on the so-called confidence distribution (Xie and Singh, 2013). Here, we provide a basic overview of the approach; details for the up-front and sequential algorithms are in subsequent sections. Let
. We propose a frequentist analog based on the so-called confidence distribution (Xie and Singh, 2013). Here, we provide a basic overview of the approach; details for the up-front and sequential algorithms are in subsequent sections. Let  be the vector of parameters that, with a subject’s current history, determines a subject’s optimal treatment; for example, under up-front randomization,
be the vector of parameters that, with a subject’s current history, determines a subject’s optimal treatment; for example, under up-front randomization,  . Let
. Let  be the estimated confidence distribution for
be the estimated confidence distribution for  at week t based on
at week t based on  , for example, the estimated asymptotic distribution of some estimator
, for example, the estimated asymptotic distribution of some estimator  for
for  ; and let
; and let  ,
,  , be independent draws from
, be independent draws from  . Then for
. Then for  ,
,  .
.
At the onset of a SMART, a burn-in period of nonadaptive randomization may be required from which to obtain an initial estimate of  and associated confidence distribution to be used for the first update of randomization probabilities. The burn-in may be characterized in terms of numbers of subjects who have completed each stage or the calendar time elapsed since the start of the trial; examples are presented in Section 5. In what follows,
and associated confidence distribution to be used for the first update of randomization probabilities. The burn-in may be characterized in terms of numbers of subjects who have completed each stage or the calendar time elapsed since the start of the trial; examples are presented in Section 5. In what follows,  is the calendar time at which burn-in is complete, so that adaptation starts at week
is the calendar time at which burn-in is complete, so that adaptation starts at week  . See Web Appendix A for further discussion of specification of the burn-in period.
. See Web Appendix A for further discussion of specification of the burn-in period.
3. ADAPTIVE RANDOMIZATION FOR SMARTS USING THOMPSON SAMPLING
We now present the proposed up-front and sequential TS approaches to RAR for SMARTs. As above, under up-front randomization, subjects are randomized once, at enrollment, to an embedded regime, which they follow through all K stages. Thus, the path that a subject will take through the trial is determined by  . Up-front randomization is logistically simpler but does not use additional data that have accumulated as the subject progresses through the trial. Up-front randomization is preferred when simplicity of implementation is a priority or when enrollment is expected to be slow relative to the time to progress through the trial, so that the amount of new data accumulating before a subject completes all K stages is modest. Under sequential randomization, subjects are randomized at each stage, so that up-to-date information from previous subjects informs randomization probabilities as a subject progresses, but involves greater logistical complexity.
. Up-front randomization is logistically simpler but does not use additional data that have accumulated as the subject progresses through the trial. Up-front randomization is preferred when simplicity of implementation is a priority or when enrollment is expected to be slow relative to the time to progress through the trial, so that the amount of new data accumulating before a subject completes all K stages is modest. Under sequential randomization, subjects are randomized at each stage, so that up-to-date information from previous subjects informs randomization probabilities as a subject progresses, but involves greater logistical complexity.
3.1. Up-front randomization among regimes
To randomize newly enrolled subjects at week t to the embedded regimes  ,
,  , we require an estimator
, we require an estimator  for
for  based on
based on  with which to construct a confidence distribution and thus randomization probabilities
with which to construct a confidence distribution and thus randomization probabilities  . Aligned with standard methods for SMARTs, we focus on inverse probability weighted (IPW) and augmented IPW (AIPW) estimators for
. Aligned with standard methods for SMARTs, we focus on inverse probability weighted (IPW) and augmented IPW (AIPW) estimators for  (Tsiatis et al., 2020, Sections 6.4.3-6.4.4). As we discuss in Section 4, under any form of RAR, the asymptotic distribution of these estimators based on the data at the end of the trial need not be normal; thus, we adapt the approach of Zhang et al. (2021b) and propose weighted versions of these estimators, where the weights are chosen so that the weighted estimators are asymptotically normal. For stratified sampling, the formulation applies within each stratum.
(Tsiatis et al., 2020, Sections 6.4.3-6.4.4). As we discuss in Section 4, under any form of RAR, the asymptotic distribution of these estimators based on the data at the end of the trial need not be normal; thus, we adapt the approach of Zhang et al. (2021b) and propose weighted versions of these estimators, where the weights are chosen so that the weighted estimators are asymptotically normal. For stratified sampling, the formulation applies within each stratum.
For subjects who enroll at week t, define  and, for
and, for  ,
,  . For regime
. For regime  , let
, let  ,
,  ,
,  ,
,  ,
,  ,
,  . For each
. For each  , let
, let  be the indicator that a subject’s experience through all K stages is consistent with receiving treatment using
be the indicator that a subject’s experience through all K stages is consistent with receiving treatment using  . Each enrolled subject in
. Each enrolled subject in  was randomized at week
was randomized at week  based on
based on  , thus using
, thus using  ,
,  . For each, define
. For each, define  ,
,  ,
,  . The weighted IPW (WIPW) estimator for
. The weighted IPW (WIPW) estimator for  is
is
 |
(1) |
where  is a weight depending on
is a weight depending on  discussed further in Section 4. The denominator in each term in (1) can be interpreted as the propensity for receiving treatment consistent with
discussed further in Section 4. The denominator in each term in (1) can be interpreted as the propensity for receiving treatment consistent with  through all K stages and depends on
through all K stages and depends on  ,
,  . For example, in the cancer pain SMART with
. For example, in the cancer pain SMART with  , let
, let  denote a patient’s baseline pain score and
denote a patient’s baseline pain score and  their pain score at the end of stage 1, so that
their pain score at the end of stage 1, so that  , and let
, and let  denote their response status. For embedded regime
denote their response status. For embedded regime  , under which a subject will receive
, under which a subject will receive  and then
and then  if they respond to
if they respond to  and
and  otherwise,
otherwise,  . Because regimes 1–4 assign
. Because regimes 1–4 assign  ,
,  , and because regimes 1 and 2 assign
, and because regimes 1 and 2 assign  to responders and regimes 1 and 4 assign
to responders and regimes 1 and 4 assign  to nonresponders,
to nonresponders,  .
.
Usual AIPW estimators incorporate baseline and interim information (eg, Tsiatis et al., 2020, Section 6.4.4) to gain efficiency over IPW estimators. Accordingly, we consider a class of weighted AIPW (WAIPW) estimators. Let  be a weight depending on
be a weight depending on  ; and
; and  ,
,  , with
, with  . Estimators in the class are of the form
. Estimators in the class are of the form
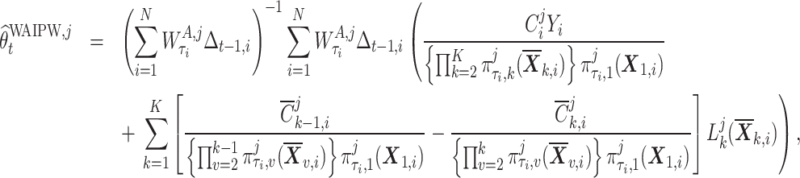 |
(2) |
where  is an arbitrary function of
is an arbitrary function of  and
and  ,
,  ; and
; and  .
.
The optimal choice is  ,
,  , which can be modeled and estimated by adapting the backward iterative scheme in Tsiatis et al. (2020, Section 6.4.2). Just as the denominators of each term in (1) and (2) depend on
, which can be modeled and estimated by adapting the backward iterative scheme in Tsiatis et al. (2020, Section 6.4.2). Just as the denominators of each term in (1) and (2) depend on  ,
,  , based on
, based on  , the fitted models used to approximate the optimal
, the fitted models used to approximate the optimal 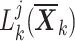 should be based on
should be based on  . At stage K, define
. At stage K, define 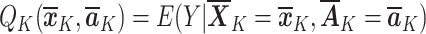 and
and  . Posit a model
. Posit a model 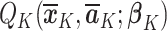 for
for 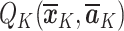 indexed by
indexed by  , for example, a linear or logistic model for continuous or binary Y, respectively. Let
, for example, a linear or logistic model for continuous or binary Y, respectively. Let 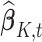 denote an estimator for
denote an estimator for  based on subjects in
based on subjects in 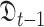 for whom
for whom 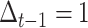 , for example, using least squares or maximum likelihood, and define
, for example, using least squares or maximum likelihood, and define  and
and  . Recursively for
. Recursively for  , define
, define 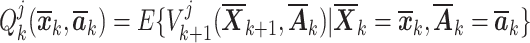 and
and  . Posit a model
. Posit a model  indexed by
indexed by  , and obtain estimator
, and obtain estimator 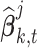 based on subjects in
based on subjects in  for whom
for whom 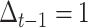 by an appropriate regression method using as the outcome the pseudo outcomes
by an appropriate regression method using as the outcome the pseudo outcomes  , and let
, and let 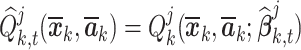 . As in Tsiatis et al. (2020, Section 6.4.2), these models may involve separate expressions for responders and nonresponders; and, if at stage k there is only one treatment option for a subject’s history, Y (if
. As in Tsiatis et al. (2020, Section 6.4.2), these models may involve separate expressions for responders and nonresponders; and, if at stage k there is only one treatment option for a subject’s history, Y (if 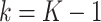 ) or
) or 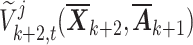 (if
(if  ) can be “carried back” in the place of
) can be “carried back” in the place of 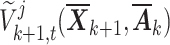 . For each i with
. For each i with 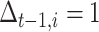 in (2), substitute
in (2), substitute  and
and 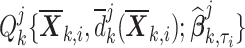 for
for 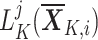 and
and 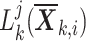 ,
,  , respectively.
, respectively.
As the basis for RAR, we propose using (1) or (2), with or without weights, to obtain estimators 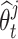 for
for 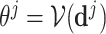 ,
,  , based on
, based on 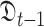 ; and take the estimated confidence distribution for
; and take the estimated confidence distribution for 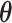 needed to obtain
needed to obtain 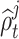 to form
to form  ,
, 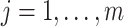 , to be the asymptotic normal distribution for
, to be the asymptotic normal distribution for  following from M-estimation theory (eg, Tsiatis et al., 2020, Section 6.4.4), with the weights treated as fixed; see Web Appendix A for discussion.
following from M-estimation theory (eg, Tsiatis et al., 2020, Section 6.4.4), with the weights treated as fixed; see Web Appendix A for discussion.
Basing confidence distributions and thus randomization probabilities at week t on (1) or (2) uses data only on subjects in 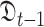 who have completed the trial, for whom
who have completed the trial, for whom 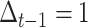 . To exploit partial information on subjects still progressing through the trial at t, with
. To exploit partial information on subjects still progressing through the trial at t, with 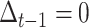 , it is possible to develop a weighted version of the interim AIPW (IAIPW) estimator of Manschot et al. (2023); see Web Appendix A. Simulations in Section 5 show negligible gains in performance over (1) or (2).
, it is possible to develop a weighted version of the interim AIPW (IAIPW) estimator of Manschot et al. (2023); see Web Appendix A. Simulations in Section 5 show negligible gains in performance over (1) or (2).
3.2. Sequential randomization based on the optimal regime
We propose methods for obtaining randomization probabilities at week t based on 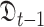 to be used to assign treatments for subjects requiring randomization at t at any stage
to be used to assign treatments for subjects requiring randomization at t at any stage  . Because the set of feasible treatments
. Because the set of feasible treatments  for a subject with history
for a subject with history 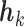 at stage k may depend on
at stage k may depend on  , as when the sets of options for responders and nonresponders to previous treatment are different, randomization probabilities may be history dependent. The approach uses Q-learning for estimation of an optimal, individualized regime (eg, Tsiatis et al., 2020, Section 7.4.1). We present the approach when Y is continuous and linear models are used; extensions to other outcomes and more flexible models are possible (Moodie et al., 2014).
, as when the sets of options for responders and nonresponders to previous treatment are different, randomization probabilities may be history dependent. The approach uses Q-learning for estimation of an optimal, individualized regime (eg, Tsiatis et al., 2020, Section 7.4.1). We present the approach when Y is continuous and linear models are used; extensions to other outcomes and more flexible models are possible (Moodie et al., 2014).
Define the Q-functions  and, for
and, for  ,
,  , where
, where  ,
,  . Posit models
. Posit models  , where
, where  is a
is a 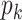 -dimensional feature function,
-dimensional feature function, 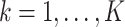 . Randomization probabilities are obtained via the following backward algorithm. At stage K, obtain
. Randomization probabilities are obtained via the following backward algorithm. At stage K, obtain 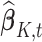 , the ordinary least squares (OLS) estimator based on subjects in
, the ordinary least squares (OLS) estimator based on subjects in 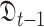 for whom
for whom 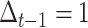 and its estimated covariance matrix
and its estimated covariance matrix  ,
,  ,
,  . Based on these results, obtain the estimated confidence distribution
. Based on these results, obtain the estimated confidence distribution  for
for  as described below. For
as described below. For  , define pseudo outcomes
, define pseudo outcomes  for subjects in
for subjects in  with
with  . If a subject’s history is such that
. If a subject’s history is such that 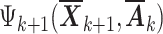 comprises a single treatment option,
comprises a single treatment option, 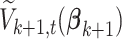 can be taken equal to the pseudo outcome at step
can be taken equal to the pseudo outcome at step 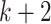 or Y if
or Y if  . Obtain an estimator for
. Obtain an estimator for  ,
,  , by OLS as
, by OLS as
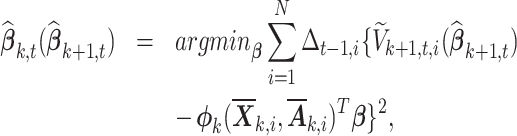 |
(3) |
and estimated covariance matrix  ,
, 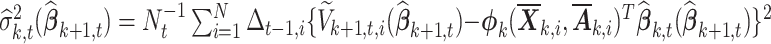 . Based on these results, obtain an estimated confidence distribution for
. Based on these results, obtain an estimated confidence distribution for 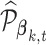 as described next. Note that, if subjects enter the SMART by a random process, basing the fitted models on subjects in
as described next. Note that, if subjects enter the SMART by a random process, basing the fitted models on subjects in  with
with 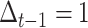 is reasonable, as these subjects are representative of the subject population.
is reasonable, as these subjects are representative of the subject population.
Because 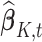 is a standard OLS estimator, it is natural to approximate the confidence distribution
is a standard OLS estimator, it is natural to approximate the confidence distribution  for
for  by
by 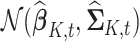 . However, because (3) is not a standard regression problem,
. However, because (3) is not a standard regression problem,  ,
, 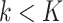 , is a nonregular estimator (Tsiatis et al., 2020, Section 10.4.1). Thus, usual large sample theory does not apply and confidence intervals based on (unadjusted) normal or bootstrap approximations need not achieve nominal coverage. Accordingly, we obtain a confidence distribution
, is a nonregular estimator (Tsiatis et al., 2020, Section 10.4.1). Thus, usual large sample theory does not apply and confidence intervals based on (unadjusted) normal or bootstrap approximations need not achieve nominal coverage. Accordingly, we obtain a confidence distribution 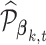 for
for 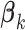 ,
,  , in the spirit of a projection interval (Laber et al.,
2014), which faithfully represents the uncertainty in
, in the spirit of a projection interval (Laber et al.,
2014), which faithfully represents the uncertainty in  .
.
We demonstrate this approach for 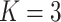 . For final stage 3, draw a sample of size
. For final stage 3, draw a sample of size 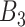 ,
, 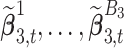 , say, from
, say, from 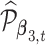 , the approximate normal sampling distribution
, the approximate normal sampling distribution  as above. At stage 2, first draw a sample
as above. At stage 2, first draw a sample 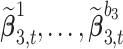 of size
of size 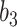 from
from  . For each
. For each 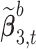 , form pseudo outcomes
, form pseudo outcomes  and obtain
and obtain  by OLS analogous to (3) with
by OLS analogous to (3) with 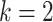 , and obtain
, and obtain  similarly. Then draw a sample
similarly. Then draw a sample 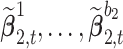 from
from 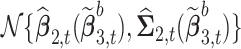 . The
. The 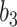 samples of size
samples of size 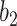 corresponding to each
corresponding to each 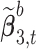 ,
,  , collectively comprise a sample of size
, collectively comprise a sample of size  from the confidence distribution
from the confidence distribution  for
for 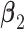 . At stage 1, again draw a sample
. At stage 1, again draw a sample 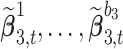 from
from  and obtain
and obtain 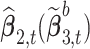 and
and  ,
,  , as above. Then draw a sample
, as above. Then draw a sample  from
from  . For each of
. For each of  ,
, 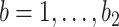 , form pseudo outcomes
, form pseudo outcomes  , and obtain
, and obtain 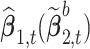 by OLS analogous to (3) with
by OLS analogous to (3) with 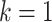 , and obtain
, and obtain 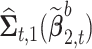 . Then draw a sample
. Then draw a sample  from
from 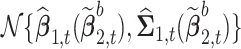 ,
, 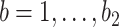 . The
. The 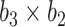 samples of size
samples of size  corresponding to each combination of draws
corresponding to each combination of draws 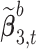 ,
,  ,
,  ,
,  , collectively comprise a sample of size
, collectively comprise a sample of size 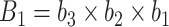 from the confidence distribution
from the confidence distribution 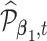 . This procedure is embarrassingly parallel, and as it involves only draws from a multivariate normal distribution, it is not computationally burdensome.
. This procedure is embarrassingly parallel, and as it involves only draws from a multivariate normal distribution, it is not computationally burdensome.
Having generated 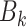 draws from
draws from  ,
, 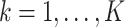 , at week t, we can obtain beliefs, that is, draws from approximate posterior distributions, which can be translated into randomization probabilities for subjects requiring treatment assignments at any stage
, at week t, we can obtain beliefs, that is, draws from approximate posterior distributions, which can be translated into randomization probabilities for subjects requiring treatment assignments at any stage  at week t. Because the Q-functions depend on patient history, the randomization probabilities under TS can vary across subjects at a given time even if their feasible treatments are the same. To see this, suppose that there are
at week t. Because the Q-functions depend on patient history, the randomization probabilities under TS can vary across subjects at a given time even if their feasible treatments are the same. To see this, suppose that there are  feasible sets of treatments at stage k, denoted by
feasible sets of treatments at stage k, denoted by  ,
,  . Further, suppose that there are
. Further, suppose that there are  subjects requiring randomization at stage k at week t and that
subjects requiring randomization at stage k at week t and that 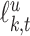 are eligible for the uth feasible set. For the uth feasible set, randomization probabilities can be obtained for each subject
are eligible for the uth feasible set. For the uth feasible set, randomization probabilities can be obtained for each subject 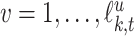 by defining the belief for
by defining the belief for  ,
, 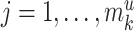 , depending on
, depending on  for subject v as
for subject v as 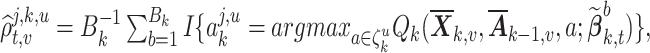 from which randomization probabilities for subject v are obtained. If the Q-function model depends on the history
from which randomization probabilities for subject v are obtained. If the Q-function model depends on the history 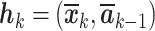 only through the components such as previous treatment and response status that dictate the feasible set, then this approach will yield the same probabilities for all
only through the components such as previous treatment and response status that dictate the feasible set, then this approach will yield the same probabilities for all 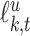 subjects. Otherwise, randomization probabilities will be individual-specific, depending on covariate and treatment information in addition to
subjects. Otherwise, randomization probabilities will be individual-specific, depending on covariate and treatment information in addition to  , which could be logistically complex. A second approach is to consider all
, which could be logistically complex. A second approach is to consider all 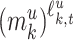 possible configurations for assigning the options in
possible configurations for assigning the options in  to the
to the 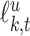 subjects and define the beliefs and thus randomization probabilities based on the configuration that maximizes the average kth Q-function across subjects. Letting
subjects and define the beliefs and thus randomization probabilities based on the configuration that maximizes the average kth Q-function across subjects. Letting 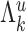 be the set of all possible configurations, writing the jth configuration as
be the set of all possible configurations, writing the jth configuration as 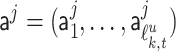 , define
, define 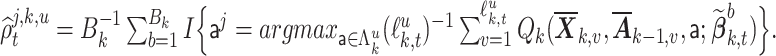 Simulation experiments (not shown here) suggest that the two approaches perform similarly.
Simulation experiments (not shown here) suggest that the two approaches perform similarly.
4. POST-TRIAL INFERENCE
Although the potential outcomes 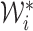 ,
,  , are independent and identically distributed (i.i.d.), under any form of RAR, the observed data are not, as the randomization probabilities are functions of the past data
, are independent and identically distributed (i.i.d.), under any form of RAR, the observed data are not, as the randomization probabilities are functions of the past data 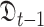 (Zhang et al., 2021b). Thus, post-trial evaluation of
(Zhang et al., 2021b). Thus, post-trial evaluation of  based on the usual unweighted IPW or AIPW estimators is potentially problematic, as standard asymptotic theory for these estimators, which assumes i.i.d. data, does not apply (eg, Bibaut et al., 2021; Zhang et al., 2021a). Thus, we adapt the approach of Zhang et al. (2021b) and choose the weights in (1) and (2) so that asymptotic normality for these estimators can be established via the martingale central limit theorem. We sketch the rationale here; details are given in Web Appendix B.
based on the usual unweighted IPW or AIPW estimators is potentially problematic, as standard asymptotic theory for these estimators, which assumes i.i.d. data, does not apply (eg, Bibaut et al., 2021; Zhang et al., 2021a). Thus, we adapt the approach of Zhang et al. (2021b) and choose the weights in (1) and (2) so that asymptotic normality for these estimators can be established via the martingale central limit theorem. We sketch the rationale here; details are given in Web Appendix B.
To emphasize the key ideas, consider a simplified setting in which a fixed number of subjects, n, enrolls at each week and 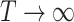 , so that the total number of subjects
, so that the total number of subjects  . To simplify notation, take
. To simplify notation, take  . At the end of the trial, with all data complete, reindexing subjects by
. At the end of the trial, with all data complete, reindexing subjects by 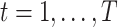 , for regime j, the estimators
, for regime j, the estimators  and
and 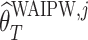 , say, are solutions in
, say, are solutions in  to an estimating equation
to an estimating equation 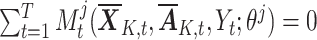 ; for example, for (1),
; for example, for (1),
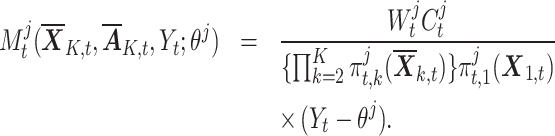 |
(4) |
Critical to the proof is that the weights  and
and  are chosen so that (1) the estimating equations remain conditionally unbiased,
are chosen so that (1) the estimating equations remain conditionally unbiased, 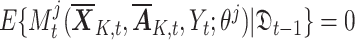 , and (2) the variance is stabilized,
, and (2) the variance is stabilized,  for all t. Writing
for all t. Writing 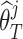 to denote either estimator and defining
to denote either estimator and defining  and
and 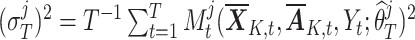 , we argue in Web Appendix B that, under standard regularity conditions,
, we argue in Web Appendix B that, under standard regularity conditions, 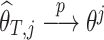 and
and
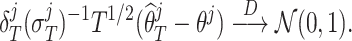 |
(5) |
In Section 5, we use (5) to construct confidence intervals and bounds for  ,
,  .
.
We sketch arguments for the WIPW estimator to show that (1) holds and how to choose the weights to guarantee (2); see Web Appendix B for details and arguments for the WAIPW estimator. Define 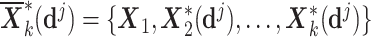 ,
,  , and write
, and write  . When
. When  ,
, 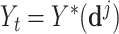 ,
, 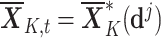 , so that (1) is
, so that (1) is
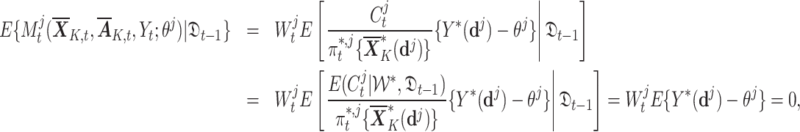 |
because, as in Tsiatis et al. (2020, Section 6.4.3),  , and
, and 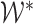 and thus
and thus  is independent of
is independent of 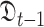 . Using similar manipulations,
. Using similar manipulations,
 |
(6) |
Thus, to ensure (2), 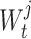 should be chosen so that (6) is a constant depending only on j.
should be chosen so that (6) is a constant depending only on j.
We demonstrate the choice of 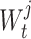 in practice for regime 1 of the cancer pain SMART,
in practice for regime 1 of the cancer pain SMART,  , and up-front randomization. From Section 3.1, letting
, and up-front randomization. From Section 3.1, letting 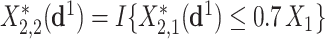 ,
, 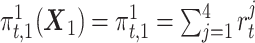 , and
, and  , where
, where 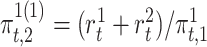 and
and 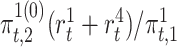 . Then, using
. Then, using  , (6) is
, (6) is
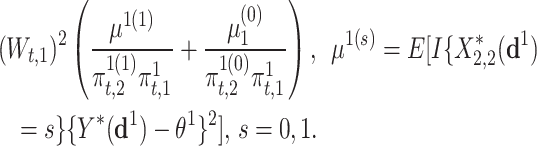 |
(7) |
Then, in the original notation, estimate 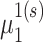 at week t by
at week t by 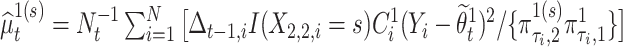 ,
,  , based on
, based on 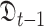 , where
, where 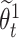 is an estimator for
is an estimator for  using
using  (we use the unweighted IPW estimator). Setting (7) equal to a constant
(we use the unweighted IPW estimator). Setting (7) equal to a constant  , say, and defining
, say, and defining 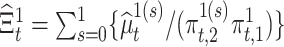 , estimate
, estimate 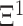 based on the burn-in data, for which
based on the burn-in data, for which  and
and  ,
,  , are fixed (nonadaptive) for
, are fixed (nonadaptive) for 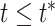 , by
, by 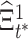 . Then for
. Then for  , take
, take 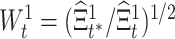 . See Web Appendix B for considerations for sequential RAR.
. See Web Appendix B for considerations for sequential RAR.
5. SIMULATION STUDIES
5.1. Up-front randomization among embedded regimes
We present results of simulation studies involving 5000 Monte Carlo trials under a scenario mimicking that of the cancer pain SMART introduced in Section 1 in which subjects are randomized using various forms of up-front RAR as in Section 3.1. From Zhang et al. (2021a,b), the extent to which standard unweighted estimators fail to be asymptotically normal under RAR likely depends on whether or not some or all of the true values of the embedded regimes are equal or at least very similar, with the null situation with all values the same particularly problematic (eg, Hadad et al., 2021). Thus, this scenario involves subsets of regime values that differ negligibly, which is common in practice and qualitatively similar to the configuration found by Somers et al. (2023). Additional studies under null and close-to-null scenarios and different designs and binary outcome are in Web Appendix C.
Each trial enrolls N subjects at times selected uniformly over integer weeks 1-24. At enrollment, we draw baseline pain score 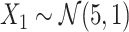 and assign stage 1 treatment
and assign stage 1 treatment  . Six weeks later, second-stage pain score is generated as
. Six weeks later, second-stage pain score is generated as  ,
, 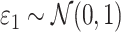 ; and response status is
; and response status is  , which, with
, which, with  , dictates the feasible subset of
, dictates the feasible subset of  from which stage 2 treatment
from which stage 2 treatment 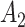 is assigned. Six weeks later, we generate outcome
is assigned. Six weeks later, we generate outcome 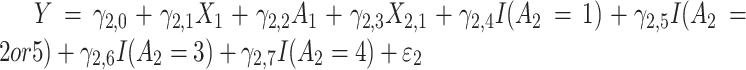 ,
, 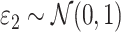 . With
. With  and
and  , for the
, for the 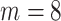 embedded regimes in Figure 1, the values
embedded regimes in Figure 1, the values  = (−0.126, −0.374, −0.500, −0.251, −2.408, −2.401, −2.494,
= (−0.126, −0.374, −0.500, −0.251, −2.408, −2.401, −2.494,  . As larger reductions in pain are favored, regimes 1-4, which assign treatment 0 at stage 1, are inferior to regimes 5-8, which assign treatment 1. Thus, we say that treatment 1 is the optimal stage 1 treatment. Regime 8 is optimal but negligibly different in value from regime 7, and the values of regimes 5 and 6 are trivially different; thus, practically speaking, either of regimes 7 or 8 is optimal. The burn-in period ends at the time
. As larger reductions in pain are favored, regimes 1-4, which assign treatment 0 at stage 1, are inferior to regimes 5-8, which assign treatment 1. Thus, we say that treatment 1 is the optimal stage 1 treatment. Regime 8 is optimal but negligibly different in value from regime 7, and the values of regimes 5 and 6 are trivially different; thus, practically speaking, either of regimes 7 or 8 is optimal. The burn-in period ends at the time  when each of the
when each of the 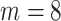 regimes has at least 25 subjects who have completed the trial with experience consistent with following the regime.
regimes has at least 25 subjects who have completed the trial with experience consistent with following the regime.
We implement up-front RAR using TS with  , and 1 for all t based on the WIPW and WAIPW estimators (1) and (2), the unweighted IAIPW estimator, and the unweighted IPW and AIPW estimators. For each, at any t we impose clipping constants of 0.05 and 0.95, so if
, and 1 for all t based on the WIPW and WAIPW estimators (1) and (2), the unweighted IAIPW estimator, and the unweighted IPW and AIPW estimators. For each, at any t we impose clipping constants of 0.05 and 0.95, so if 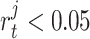 for any
for any  , set
, set  (and likewise for 0.95), and then normalize
(and likewise for 0.95), and then normalize  ,
,  , to sum to one. In the WAIPW and IAIPW estimators,
, to sum to one. In the WAIPW and IAIPW estimators, 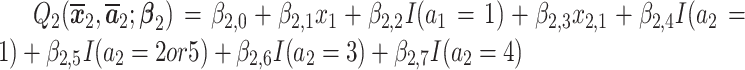 and
and  .
.
Table 1 presents results for  for up-front RAR using the WIPW, WAIPW, and unweighted IAIPW estimators with
for up-front RAR using the WIPW, WAIPW, and unweighted IAIPW estimators with  and 1, representing moderate and aggressive adaptation, and for simple, uniform randomization (SR) among the 8 embedded regimes; results for
and 1, representing moderate and aggressive adaptation, and for simple, uniform randomization (SR) among the 8 embedded regimes; results for  , similar to the sample size in the cancer pain SMART, are in Table A.1 of Web Appendix A. Additional results for
, similar to the sample size in the cancer pain SMART, are in Table A.1 of Web Appendix A. Additional results for 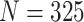 and 1000 using these estimators with
and 1000 using these estimators with 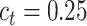 and 0.75 and for all
and 0.75 and for all 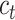 values for RAR using the unweighted IPW and AIPW estimators are in Web Appendix C. To evaluate how up-front RAR improves in-trial outcomes, we report the Monte Carlo average outcome across subjects in the trial; average proportion of subjects assigned
values for RAR using the unweighted IPW and AIPW estimators are in Web Appendix C. To evaluate how up-front RAR improves in-trial outcomes, we report the Monte Carlo average outcome across subjects in the trial; average proportion of subjects assigned  , the optimal first-stage treatment; and average proportion of subjects in the trial who had treatment experience consistent with following the optimal regime 8 and with either of regimes 7 or 8. All are improved using RAR over SR, resulting in lower average outcome and higher rates of assigning optimal stage 1 treatment and optimal regime. More aggressive adaptation,
, the optimal first-stage treatment; and average proportion of subjects in the trial who had treatment experience consistent with following the optimal regime 8 and with either of regimes 7 or 8. All are improved using RAR over SR, resulting in lower average outcome and higher rates of assigning optimal stage 1 treatment and optimal regime. More aggressive adaptation,  , yields more favorable results than
, yields more favorable results than 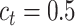 using any estimator; from Web Appendix C, results using
using any estimator; from Web Appendix C, results using  (0.75) are less favorable (intermediate). Results are more favorable for WAIPW- and IAIPW-based randomization, as those estimators exploit covariate information, with the gains mostly at stage 2. Using weighted vs. unweighted estimators yields modest in-trial gains; see Web Appendix C.
(0.75) are less favorable (intermediate). Results are more favorable for WAIPW- and IAIPW-based randomization, as those estimators exploit covariate information, with the gains mostly at stage 2. Using weighted vs. unweighted estimators yields modest in-trial gains; see Web Appendix C.
TABLE 1.
Simulation results using up-front RAR based on TS for 5000 Monte Carlo (MC) replications for the scenario in Section 5.1, 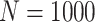 .
.
| SR | WIPW(0.5) | WIPW(1) | WAIPW(0.5) | WAIPW(1) | IAIPW(0.5) | IAIPW(1) | |
|---|---|---|---|---|---|---|---|
| In Trial | |||||||
| Mean Y | −1.380 (0.001) | −1.795 (0.001) | −1.992 (0.001) | −1.794 (0.001) | −1.996 (0.001) | −1.793 (0.001) | −1.993 (0.001) |
Proportion  Opt Opt |
0.500 (0.000) | 0.691 (0.000) | 0.782 (0.000) | 0.691 (0.000) | 0.782 (0.000) | 0.690 (0.000) | 0.782 (0.000) |
| Proportion Regime Opt | 0.250 (0.000) | 0.390 (0.001) | 0.470 (0.001) | 0.401 (0.001) | 0.498 (0.002) | 0.402 (0.001) | 0.491 (0.001) |
| Estimation | |||||||
 Est Opt (IPW)
Est Opt (IPW) |
0.433 (0.007) | 0.462 (0.007) | 0.444 (0.007) | 0.449 (0.007) | 0.409 (0.007) | 0.441 (0.007) | 0.430 (0.007) |
 Est Opt (WIPW)
Est Opt (WIPW) |
0.397 (0.007) | 0.468 (0.007) | 0.460 (0.007) | 0.463 (0.007) | 0.436 (0.007) | 0.452 (0.007) | 0.460 (0.007) |
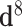 Est Opt (AIPW)
Est Opt (AIPW) |
0.529 (0.007) | 0.562 (0.007) | 0.534 (0.007) | 0.559 (0.007) | 0.523 (0.007) | 0.555 (0.007) | 0.534 (0.007) |
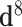 Est Opt (WAIPW)
Est Opt (WAIPW) |
0.516 (0.007) | 0.548 (0.007) | 0.540 (0.007) | 0.555 (0.007) | 0.524 (0.007) | 0.545 (0.007) | 0.539 (0.007) |
 or
or  Est Opt (IPW) Est Opt (IPW) |
0.778 (0.006) | 0.812 (0.006) | 0.782 (0.006) | 0.797 (0.006) | 0.749 (0.006) | 0.793 (0.006) | 0.757 (0.006) |
 or
or  Est Opt (WIPW) Est Opt (WIPW) |
0.736 (0.006) | 0.815 (0.005) | 0.812 (0.006) | 0.808 (0.006) | 0.796 (0.006) | 0.806 (0.006) | 0.803 (0.006) |
 or
or  Est Opt (AIPW) Est Opt (AIPW) |
0.857 (0.005) | 0.885 (0.005) | 0.856 (0.005) | 0.887 (0.004) | 0.861 (0.005) | 0.876 (0.005) | 0.859 (0.005) |
 or
or 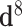 Est Opt (WAIPW) Est Opt (WAIPW) |
0.854 (0.005) | 0.887 (0.004) | 0.882 (0.005) | 0.889 (0.004) | 0.887 (0.004) | 0.878 (0.005) | 0.881 (0.005) |
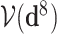 MSE
MSE 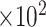 (IPW) (IPW) |
0.814 (0.017) | 0.619 (0.013) | 0.735 (0.024) | 0.591 (0.013) | 0.671 (0.019) | 0.619 (0.013) | 0.669 (0.016) |
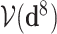 MSE
MSE  (WIPW) (WIPW) |
1.185 (0.024) | 0.598 (0.013) | 0.646 (0.012) | 0.560 (0.012) | 0.576 (0.015) | 0.578 (0.012) | 0.574 (0.014) |
 MSE
MSE  (AIPW) (AIPW) |
0.544 (0.011) | 0.419 (0.008) | 0.463 (0.012) | 0.407 (0.008) | 0.446 (0.011) | 0.438 (0.009) | 0.432 (0.009) |
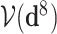 MSE
MSE 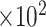 (WAIPW) (WAIPW) |
0.552 (0.012) | 0.411 (0.008) | 0.419 (0.010) | 0.400 (0.008) | 0.420 (0.011) | 0.427 (0.009) | 0.411 (0.009) |
| Coverage | |||||||
 95% CI (IPW)
95% CI (IPW) |
0.949 (0.003) | 0.950 (0.003) | 0.949 (0.003) | 0.954 (0.003) | 0.947 (0.003) | 0.951 (0.003) | 0.950 (0.003) |
 95% CI (WIPW)
95% CI (WIPW) |
0.943 (0.003) | 0.948 (0.003) | 0.945 (0.003) | 0.953 (0.003) | 0.944 (0.003) | 0.949 (0.003) | 0.948 (0.003) |
 95% CI (AIPW)
95% CI (AIPW) |
0.944 (0.003) | 0.952 (0.003) | 0.951 (0.003) | 0.952 (0.003) | 0.954 (0.003) | 0.950 (0.003) | 0.950 (0.003) |
 95% CI (WAIPW)
95% CI (WAIPW) |
0.947 (0.003) | 0.951 (0.003) | 0.950 (0.003) | 0.951 (0.003) | 0.948 (0.003) | 0.947 (0.003) | 0.944 (0.003) |
 95% LB (IPW)
95% LB (IPW) |
0.952 (0.003) | 0.960 (0.003) | 0.960 (0.003) | 0.954 (0.003) | 0.954 (0.003) | 0.950 (0.003) | 0.953 (0.003) |
 95% LB (WIPW)
95% LB (WIPW) |
0.946 (0.003) | 0.954 (0.003) | 0.948 (0.003) | 0.950 (0.003) | 0.947 (0.003) | 0.947 (0.003) | 0.945 (0.003) |
 95% LB (AIPW)
95% LB (AIPW) |
0.944 (0.003) | 0.959 (0.003) | 0.955 (0.003) | 0.951 (0.003) | 0.954 (0.003) | 0.950 (0.003) | 0.952 (0.003) |
 95% LB (WAIPW)
95% LB (WAIPW) |
0.946 (0.003) | 0.957 (0.003) | 0.950 (0.003) | 0.947 (0.003) | 0.947 (0.003) | 0.944 (0.003) | 0.945 (0.003) |
 95% UB (IPW)
95% UB (IPW) |
0.950 (0.003) | 0.944 (0.003) | 0.940 (0.003) | 0.955 (0.003) | 0.942 (0.003) | 0.949 (0.003) | 0.944 (0.003) |
 95% UB (WIPW)
95% UB (WIPW) |
0.946 (0.003) | 0.947 (0.003) | 0.944 (0.003) | 0.955 (0.003) | 0.946 (0.003) | 0.952 (0.003) | 0.947 (0.003) |
 95% UB (AIPW)
95% UB (AIPW) |
0.952 (0.003) | 0.947 (0.003) | 0.948 (0.003) | 0.954 (0.003) | 0.949 (0.003) | 0.944 (0.003) | 0.948 (0.003) |
 95% UB (WAIPW)
95% UB (WAIPW) |
0.952 (0.003) | 0.946 (0.003) | 0.952 (0.003) | 0.956 (0.003) | 0.949 (0.003) | 0.948 (0.003) | 0.950 (0.003) |
Columns indicate the randomization method: WAIPW(0.5) is TS based on the WAIPW estimator (2) with  for all t and AIPW(1) uses
for all t and AIPW(1) uses 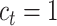 for all t; WIPW(
for all t; WIPW(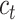 ) and IAIPW(
) and IAIPW( ) are defined similarly. SR denotes simple, uniform randomization. Mean Y denotes the MC average mean outcome for the 1000 individuals in the trial; lower mean outcomes are more favorable. Proportion
) are defined similarly. SR denotes simple, uniform randomization. Mean Y denotes the MC average mean outcome for the 1000 individuals in the trial; lower mean outcomes are more favorable. Proportion 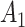 Opt is the MC average proportion of subjects assigned the optimal treatment at the first stage; Proportion Regime Opt is the MC average proportion of subjects who were consistent with following the optimal regime
Opt is the MC average proportion of subjects assigned the optimal treatment at the first stage; Proportion Regime Opt is the MC average proportion of subjects who were consistent with following the optimal regime 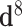 in the trial. For estimation results,
in the trial. For estimation results, 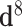 Est Opt denotes the proportion of trials we correctly estimate
Est Opt denotes the proportion of trials we correctly estimate 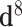 to be the optimal regime;
to be the optimal regime;  or
or 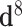 Est Opt is the proportion of trials we estimate either regime 7 or 8 to be the optimal regime; and
Est Opt is the proportion of trials we estimate either regime 7 or 8 to be the optimal regime; and  MSE is the MC mean squared error for regime 8. For the estimation results, the term in parentheses, for example, (IPW), denotes the estimator used after the trial is completed.
MSE is the MC mean squared error for regime 8. For the estimation results, the term in parentheses, for example, (IPW), denotes the estimator used after the trial is completed. 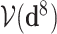 95% CI is the MC proportion of 95% confidence intervals that cover the true value; the term in parentheses is the estimator used to construct the confidence interval.
95% CI is the MC proportion of 95% confidence intervals that cover the true value; the term in parentheses is the estimator used to construct the confidence interval. 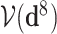 95% LB for lower confidence bounds
95% LB for lower confidence bounds  95% UB for upper confidence bounds are defined similarly. Bold values indicate the most favorable result among the randomization methods. Standard deviations of entries are in parentheses.
95% UB for upper confidence bounds are defined similarly. Bold values indicate the most favorable result among the randomization methods. Standard deviations of entries are in parentheses.
Reflecting post-trial performance, Table 1 shows for 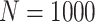 the proportion of trials where
the proportion of trials where 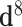 alone or either of
alone or either of  or
or 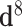 is identified as optimal and the mean-squared error (MSE) for
is identified as optimal and the mean-squared error (MSE) for  based on estimation of
based on estimation of  using the IPW, AIPW, WIPW, and WAIPW estimators with final data at the end of the trial; analogous results for
using the IPW, AIPW, WIPW, and WAIPW estimators with final data at the end of the trial; analogous results for  are in Web Appendix A. Relative to SR, using RAR based on any of the estimators generally identifies optimal regimes at higher rates. Performance of 95% confidence intervals and lower/upper confidence bounds for the true value based on the asymptotic theory in Section 4 is presented for
are in Web Appendix A. Relative to SR, using RAR based on any of the estimators generally identifies optimal regimes at higher rates. Performance of 95% confidence intervals and lower/upper confidence bounds for the true value based on the asymptotic theory in Section 4 is presented for 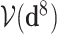 ; that for other regimes is similar, see Web Appendix C. Regardless of randomization scheme, the nominal level is achieved in almost every case. Figure 2 shows the distribution of the 5000 centered and scaled final value estimates
; that for other regimes is similar, see Web Appendix C. Regardless of randomization scheme, the nominal level is achieved in almost every case. Figure 2 shows the distribution of the 5000 centered and scaled final value estimates  ,
, 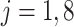 , obtained using the IPW, AIPW, WIPW, and WAIPW estimators based on RAR using the WAIPW estimator with
, obtained using the IPW, AIPW, WIPW, and WAIPW estimators based on RAR using the WAIPW estimator with 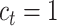 ,
,  ; those for other schemes are similar. As found by Zhang et al. (2021b) and others, unweighted estimators result in mildly skewed distributions, while weighted estimators yield approximate standard normality. Similar observations hold over all simulation scenarios we have tried, with both continuous and binary outcomes; see Web Appendix C.
; those for other schemes are similar. As found by Zhang et al. (2021b) and others, unweighted estimators result in mildly skewed distributions, while weighted estimators yield approximate standard normality. Similar observations hold over all simulation scenarios we have tried, with both continuous and binary outcomes; see Web Appendix C.
FIGURE 2.

Monte Carlo distributions of centered and scaled estimates as in the theory of Section 4 for selected estimators in the simulation in Section 5.1,  . The histograms correspond to the indicated estimator for
. The histograms correspond to the indicated estimator for 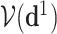 and
and  under up-front randomization using TS based on the WAIPW estimator (2) with
under up-front randomization using TS based on the WAIPW estimator (2) with  for all t. The vertical line indicates mean zero, and the density of a standard normal distribution is superimposed.
for all t. The vertical line indicates mean zero, and the density of a standard normal distribution is superimposed.
5.2. Sequential randomization at each stage based on optimal regimes
We report on simulation studies involving 5000 Monte Carlo trials under the scenario in Section 5.1 to compare the Q-learning-based sequential RAR approach using TS in Section 3.2 with 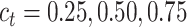 and 1 to SR and to a conservatively tuned (AR-1) and more aggressively tuned (AR-2) version of the SMART-AR method of Cheung et al. (2014); see Web Appendix A for details. Results for additional scenarios are in Web Appendix C. To implement all RAR methods, we posit linear models
and 1 to SR and to a conservatively tuned (AR-1) and more aggressively tuned (AR-2) version of the SMART-AR method of Cheung et al. (2014); see Web Appendix A for details. Results for additional scenarios are in Web Appendix C. To implement all RAR methods, we posit linear models 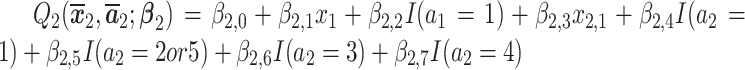 and
and 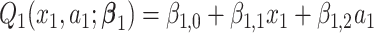 . For sequential RAR, we set
. For sequential RAR, we set  and
and  . Clipping constants of 0.05 and 0.95 were imposed on all methods.
. Clipping constants of 0.05 and 0.95 were imposed on all methods.
At each week, for each RAR method, newly enrolled subjects are assigned stage 1 treatment using the same randomization probability. Already-enrolled subjects who have reached stage 2 at this week and require stage 2 randomization are partitioned into 4 groups based on 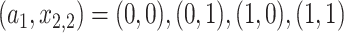 . Within each group, randomization probabilities are calculated; thus, second-stage probabilities are specific to each stage 1 treatment-response status combination. The burn-in period ends at the time
. Within each group, randomization probabilities are calculated; thus, second-stage probabilities are specific to each stage 1 treatment-response status combination. The burn-in period ends at the time  when at least 25 subjects have completed the trial with experience consistent with each of the
when at least 25 subjects have completed the trial with experience consistent with each of the 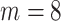 embedded regimes.
embedded regimes.
Table 2 presents the results for 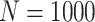 ; those for
; those for  are in Table A.2 of Web Appendix A. As in Section 5.1, the sequential RAR method results in improved (over SR) in-trial outcomes on average by assigning optimal treatments and regimes at higher rates. The AR methods also improve on SR but are relatively conservative. For post-trial estimation, less-aggressive RAR identifies the optimal regime at higher rates than SR. The proposed method with
are in Table A.2 of Web Appendix A. As in Section 5.1, the sequential RAR method results in improved (over SR) in-trial outcomes on average by assigning optimal treatments and regimes at higher rates. The AR methods also improve on SR but are relatively conservative. For post-trial estimation, less-aggressive RAR identifies the optimal regime at higher rates than SR. The proposed method with  and 0.75 yields the best post-trial performance using any of the IPW, WIPW, AIPW, or WAIPW estimators but lower rate of identifying the optimal regime. As expected, the AIPW and WAIPW estimators are more efficient than the IPW and WIPW estimators. While the primary goal of the weighted estimators is to attain nominal coverage, an additional benefit is higher rates of identifying the optimal regime.
and 0.75 yields the best post-trial performance using any of the IPW, WIPW, AIPW, or WAIPW estimators but lower rate of identifying the optimal regime. As expected, the AIPW and WAIPW estimators are more efficient than the IPW and WIPW estimators. While the primary goal of the weighted estimators is to attain nominal coverage, an additional benefit is higher rates of identifying the optimal regime.
TABLE 2.
Simulation results using sequential RAR based on TS for 5000 Monte Carlo replications for the scenario in Section 5.1,  .
.
| SR | TS(0.25) | TS(0.50) | TS(0.75) | TS(1) | AR-1 | AR-2 | |
|---|---|---|---|---|---|---|---|
| In Trial | |||||||
| Mean Y | −1.380 (0.001) | −1.976 (0.001) | −1.999 (0.001) | −2.014 (0.001) | −2.206 (0.001) | −1.950 (0.001) | −1.957 (0.001) |
Proportion  Opt Opt |
0.500 (0.000) | 0.772 (0.001) | 0.780 (0.001) | 0.785 (0.001) | 0.790 (0.000) | 0.775 (0.000) | 0.775 (0.000) |
| Proportion Regime Opt | 0.250 (0.000) | 0.445 (0.001) | 0.491 (0.001) | 0.517 (0.001) | 0.538 (0.002) | 0.320 (0.001) | 0.351 (0.001) |
| Estimation | |||||||
 Est Opt (IPW)
Est Opt (IPW) |
0.433 (0.007) | 0.471 (0.007) | 0.463 (0.007) | 0.423 (0.007) | 0.404 (0.007) | 0.468 (0.007) | 0.484 (0.007) |
 Est Opt (WIPW)
Est Opt (WIPW) |
0.397 (0.007) | 0.480 (0.007) | 0.471 (0.007) | 0.452 (0.007) | 0.434 (0.007) | 0.480 (0.007) | 0.488 (0.007) |
 Est Opt (AIPW)
Est Opt (AIPW) |
0.529 (0.007) | 0.568 (0.007) | 0.549 (0.007) | 0.512 (0.007) | 0.484 (0.007) | 0.546 (0.007) | 0.569 (0.007) |
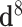 Est Opt (WAIPW)
Est Opt (WAIPW) |
0.516 (0.007) | 0.569 (0.007) | 0.548 (0.007) | 0.530 (0.007) | 0.519 (0.007) | 0.558 (0.007) | 0.582 (0.007) |
 or
or 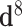 Est Opt (IPW) Est Opt (IPW) |
0.778 (0.006) | 0.813 (0.006) | 0.792 (0.006) | 0.750 (0.006) | 0.724 (0.006) | 0.810 (0.006) | 0.822 (0.005) |
 or
or  Est Opt (WIPW) Est Opt (WIPW) |
0.736 (0.006) | 0.827 (0.005) | 0.814 (0.006) | 0.793 (0.006) | 0.784 (0.006) | 0.820 (0.005) | 0.830 (0.005) |
 or
or  Est Opt (AIPW) Est Opt (AIPW) |
0.857 (0.005) | 0.888 (0.005) | 0.876 (0.005) | 0.840 (0.005) | 0.799 (0.006) | 0.890 (0.004) | 0.904 (0.004) |
 or
or  Est Opt (WAIPW) Est Opt (WAIPW) |
0.854 (0.005) | 0.897 (0.004) | 0.889 (0.004) | 0.873 (0.005) | 0.860 (0.005) | 0.897 (0.004) | 0.912 (0.004) |
 MSE
MSE  (IPW) (IPW) |
0.814 (0.017) | 0.556 (0.012) | 0.541 (0.012) | 0.586 (0.015) | 0.660 (0.020) | 0.837 (0.018) | 0.676 (0.014) |
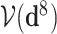 MSE
MSE 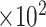 (WIPW) (WIPW) |
1.185 (0.024) | 0.504 (0.011) | 0.480 (0.011) | 0.515 (0.014) | 0.517 (0.014) | 0.767 (0.016) | 0.636 (0.013) |
 MSE
MSE  (AIPW) (AIPW) |
0.544 (0.011) | 0.396 (0.009) | 0.383 (0.008) | 0.401 (0.010) | 0.433 (0.013) | 0.521 (0.011) | 0.442 (0.009) |
 MSE
MSE  (WAIPW) (WAIPW) |
0.552 (0.012) | 0.377 (0.008) | 0.368 (0.008) | 0.381 (0.010) | 0.378 (0.010) | 0.501 (0.010) | 0.432 (0.009) |
| Coverage | |||||||
 95% CI (IPW)
95% CI (IPW) |
0.949 (0.003) | 0.940 (0.003) | 0.951 (0.003) | 0.953 (0.003) | 0.954 (0.003) | 0.949 (0.003) | 0.948 (0.003) |
 95% CI (WIPW)
95% CI (WIPW) |
0.943 (0.003) | 0.940 (0.003) | 0.951 (0.003) | 0.952 (0.003) | 0.954 (0.003) | 0.949 (0.003) | 0.947 (0.003) |
 95% CI (AIPW)
95% CI (AIPW) |
0.944 (0.003) | 0.947 (0.003) | 0.950 (0.003) | 0.958 (0.003) | 0.954 (0.003) | 0.950 (0.003) | 0.952 (0.003) |
 95% CI (WAIPW)
95% CI (WAIPW) |
0.947 (0.003) | 0.942 (0.003) | 0.947 (0.003) | 0.951 (0.003) | 0.952 (0.003) | 0.948 (0.003) | 0.951 (0.003) |
 95% LB (IPW)
95% LB (IPW) |
0.952 (0.003) | 0.948 (0.003) | 0.952 (0.003) | 0.955 (0.003) | 0.960 (0.003) | 0.940 (0.003) | 0.948 (0.003) |
 95% LB (WIPW)
95% LB (WIPW) |
0.946 (0.003) | 0.946 (0.003) | 0.948 (0.003) | 0.950 (0.003) | 0.954 (0.003) | 0.946 (0.003) | 0.949 (0.003) |
 95% LB (AIPW)
95% LB (AIPW) |
0.944 (0.003) | 0.948 (0.003) | 0.948 (0.003) | 0.955 (0.003) | 0.957 (0.003) | 0.944 (0.003) | 0.949 (0.003) |
 95% LB (WAIPW)
95% LB (WAIPW) |
0.946 (0.003) | 0.946 (0.003) | 0.945 (0.003) | 0.947 (0.003) | 0.950 (0.003) | 0.946 (0.003) | 0.951 (0.003) |
 95% UB (IPW)
95% UB (IPW) |
0.950 (0.003) | 0.945 (0.003) | 0.950 (0.003) | 0.950 (0.003) | 0.946 (0.003) | 0.952 (0.003) | 0.950 (0.003) |
 95% UB (WIPW)
95% UB (WIPW) |
0.946 (0.003) | 0.947 (0.003) | 0.951 (0.003) | 0.951 (0.003) | 0.952 (0.003) | 0.949 (0.003) | 0.948 (0.003) |
 95% UB (AIPW)
95% UB (AIPW) |
0.952 (0.003) | 0.946 (0.003) | 0.951 (0.003) | 0.952 (0.003) | 0.952 (0.003) | 0.954 (0.003) | 0.951 (0.003) |
 95% UB (WAIPW)
95% UB (WAIPW) |
0.952 (0.003) | 0.949 (0.003) | 0.953 (0.003) | 0.957 (0.003) | 0.956 (0.003) | 0.952 (0.003) | 0.947 (0.003) |
Columns indicate the randomization method: TS(0.25) is TS via Q-learning with 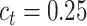 for all t, TS(0.50), TS(0.75), and TS(1) are defined similarly. AR-1 is the conservatively tuned version of SMART-AR and AR-2 is the more aggressive version. SR denotes simple, uniform randomization. All entries are defined as in Table 1.
for all t, TS(0.50), TS(0.75), and TS(1) are defined similarly. AR-1 is the conservatively tuned version of SMART-AR and AR-2 is the more aggressive version. SR denotes simple, uniform randomization. All entries are defined as in Table 1.
Figure 3 shows the distributions of the 5000 centered and scaled final value estimates  ,
, 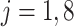 , based on sequential RAR using TS with
, based on sequential RAR using TS with 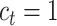 with
with 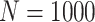 (plots for other methods and regimes are similar). For
(plots for other methods and regimes are similar). For 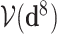 , the weighted estimators are approximately normal while the unweighted estimators are slightly left skewed; for
, the weighted estimators are approximately normal while the unweighted estimators are slightly left skewed; for 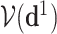 , the unweighted estimators are nonnormal, and the weighted estimators are improved. We attribute this behavior to undersampling of
, the unweighted estimators are nonnormal, and the weighted estimators are improved. We attribute this behavior to undersampling of 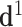 , the least effective regime; the issue is less pronounced for less aggressive randomization. Coverage of confidence intervals and bounds for
, the least effective regime; the issue is less pronounced for less aggressive randomization. Coverage of confidence intervals and bounds for  is mildly improved for the weighted estimators.
is mildly improved for the weighted estimators.
FIGURE 3.

Monte Carlo distributions of centered and scaled estimates as in the theory of Section 4 for selected estimators in the simulation in Section 5.2, 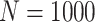 . The histograms correspond to the indicated estimator for
. The histograms correspond to the indicated estimator for  and
and 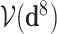 under sequential randomization using TS with
under sequential randomization using TS with 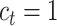 for all t. The vertical line indicates mean zero, and the density of a standard normal distribution is superimposed.
for all t. The vertical line indicates mean zero, and the density of a standard normal distribution is superimposed.
6. DISCUSSION
We have proposed methods for RAR in SMARTs using TS, where randomization can be up-front to embedded regimes or performed sequentially at each stage. Simulation studies demonstrate the benefits over nonadaptive randomization: improved outcomes for subjects in the trial, improved ability to identify an optimal regime, and little or no effect on post-trial inference on embedded regimes. Choice of damping constant can dramatically affect the aggressiveness of TS; thus, the specific features and goals of a SMART should be considered when choosing this parameter. When randomization is up-front, basing TS on WAIPW or AIPW estimators leads to more aggressive adaptation than with WIPW or IPW estimators. SMART-AR methods yield good in- and post-trial performance; however, the tuning parameters are less intuitive and effective. For any SMART, we recommend simulating different adaptive randomization methods to see which best aligns with the trial goals.
The weighted versions of the IPW and AIPW estimators are preferred over the unweighted estimators for post-trial inference. Normalized weighted estimators have sampling distributions closer to the standard normal and yield improved coverage of confidence intervals and bounds and ability to identify optimal embedded regimes. When baseline and intermediate subject variables that are correlated with outcome are available, we recommend the WAIPW estimator for post-trial inference when using RAR of any type.
We have taken a frequentist perspective in alignment with standard SMART methodology. An alternative approach is to adopt a fully Bayesian framework and base RAR on relevant posterior distributions for the model components. With a correctly specified model for the joint distribution of all relevant subject variables across all stages and a suitable prior specification, a Bayesian approach can obviate concern over the relevance of asymptotic theory early in the trial at the cost of the need for trial-specific modeling and implementation on the part of the user. See Web Appendix A for further discussion.
Supplementary Material
Web Appendices A–C, referenced in Sections 3–5, and code to implement the simulations, are available with this paper at the Biometrics website on Oxford Academic.
Contributor Information
Peter Norwood, Quantum Leap Healthcare Collaborative, 499 Illinois Ave, Suite 200, San Francisco, CA 94158, United States.
Marie Davidian, Department of Statistics, North Carolina State University, 2311 Stinson Drive, Campus Box 8203, Raleigh, NC 27695-8203, United States.
Eric Laber, Department of Statistical Science, Duke University, 214 Old Chemistry, Box 90251, Durham, NC 27708-0251, United States.
FUNDING
This research was partially supported by National Institutes of Health grant R01CA280970.
CONFLICT OF INTEREST
None declared.
DATA AVAILABILITY
Data sharing is not applicable to this article, as no datasets are generated or analysed. The methods developed will enable design and analysis of future SMARTs.
REFERENCES
- Atkinson A. C., Biswas A. (2013). Randomised Response-Adaptive Designs in Clinical Trials. Boca Raton, FL: Chapman and Hall/CRC Press. [Google Scholar]
- Berry D. (2011). Adaptive clinical trials in oncology. Nature Reviews Clinical Oncology, 9, 199–207. [DOI] [PubMed] [Google Scholar]
- Berry D. A. (2015). The Brave New World of clinical cancer research: Adaptive biomarker-driven trials integrating clinical practice with clinical research. Molecular Oncology, 9, 951–959. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Berry D. A., Fristedt B. (1985). Bandit Problems: Sequential Allocation of Experiments. London: Chapman and Hall. [Google Scholar]
- Berry S. M., Carlin B. P., Lee J. J., Muller P. (2010). Bayesian Adaptive Methods for Clinical Trials. Boca Raton, FL: Chapman and Hall/CRC Press. [Google Scholar]
- Bibaut A., Dimakopoulou M., Kallus N., Chambaz A., van der Laan M. (2021). Post-contextual-bandit inference. Advances in Neural Information Processing Systems, 34, 28548–28559. [PMC free article] [PubMed] [Google Scholar]
- Bigirumurame T., Uwimpuhwe G., Wason J. (2022). Sequential multiple assignment randomized trial studies should report all key components: a systematic review. Journal of Clinical Epidemiology, 142, 152–160. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cheung Y. K., Chakraborty B., Davidson K. W. (2014). Sequential multiple assignment randomized trial (SMART) with adaptive randomization for quality improvement in depression treatment program. Biometrics, 71, 450–459. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Food and Drug Administration . (2019). Adaptive Designs for Clinical Trials of Drugs and Biologics. Guidance for industry. November 2019. https://www.fda.gov/media/78495/download,US Food and Drug Administration, Silver Spring, MD. [Google Scholar]
- Hadad V., Hirshberg D. A., Zhan R., Wager S., Athey S. (2021). Confidence intervals for policy evaluation in adaptive experiments. Proceedings of the National Academy of Sciences, 118, e2014602118. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hu F., Rosenberger W. F. (2006). The Theory of Response-Adaptive Randomization in Clinical Trials. New York: John Wiley and Sons. [Google Scholar]
- Kidwell K. M. (2014). SMART designs in cancer research: Past, present, and future. Clinical Trials, 11, 445–456. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kim E. S., Herbst R. S., Wistuba I. I., Lee J. J., Blumenschein G. R., Tsao A. et al. (2011). The BATTLE trial: personalizing therapy for lung cancer. Cancer Discovery, 1, 44–53. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Laber E. B., Lizotte D. J., Qian M., Pelham W. E., Murphy S. A. (2014). Dynamic treatment regimes: Technical challenges and applications. Electronic Journal of Statistics, 8,1225–1272. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lattimore T., Szepesvári C. (2020). Bandit Algorithms. Cambridge: Cambridge University Press. [Google Scholar]
- Lorenzoni G., Petracci E., Scarpi E., Baldi I., Gregori D., Nanni O. (2023). Use of Sequential Multiple Assignment Randomized Trials (SMARTs) in oncology: systematic review of published studies. British Journal of Cancer, 128, 1177–1188. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Manschot C., Laber E., Davidian M. (2023). Interim monitoring of sequential multiple assignment randomized trials using partial information. Biometrics, 79, 2881–2894. [DOI] [PubMed] [Google Scholar]
- Moodie E. E., Dean N., Sun Y. R. (2014). Q-learning: Flexible learning about useful utilities. Statistics in Biosciences, 6, 223–243. [Google Scholar]
- Murphy S. A. (2005). An experimental design for the development of adaptive treatment strategies. Statistics in Medicine, 24, 1455–1481. [DOI] [PubMed] [Google Scholar]
- Proschan M., Evans S. (2020). Resist the temptation of response-adaptive randomization. Clinical Infectious Diseases, 71, 3002–3004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Russo D., Roy B. V., Kazerouni A., Osband I., Wen Z. (2018). A Tutorial on Thompson Sampling. Foundations and Trends in Machine Learning, 11, 1–96. [Google Scholar]
- Somers T. J., Winger J. G., Fisher H. M., Hyland K. A., Davidian M., Laber E. B. et al. (2023). Behavioral cancer pain intervention dosing: results of a Sequential Multiple Assignment Randomized Trial. PAIN, 164, 1935–1941. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Thall P., Wathen K. (2007). Practical Bayesian Adaptive Randomization in Clinical Trials. European Journal of Cancer, 43, 859–866. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Thall P. F., Fox P. S., Wathen J. K. (2015). Some caveats for outcome adaptive randomization in clinical trials. In: Modern Adaptive Randomized Clinical Trials: Statistical and Practical Aspects(ed. Sverdiov O.Page), 287–305.. Boca Raton, FL: Chapman and Hall/CRC Press. [Google Scholar]
- Thompson W. R. (1933). On the likelihood that one unknown probability exceeds another in view of the evidence of two samples. Biometrika, 25, 285–294. [Google Scholar]
- Tsiatis A. A., Davidian M., Holloway S., Laber E. B. (2020). Dynamic Treatment Regimes: Statistical Methods for Precision Medicine. Boca Raton, FL: Chapman and Hall/CRC Press. [Google Scholar]
- Viele K., Broglio K., McGlothlin A., Saville B. R. (2020). Comparison of methods for control allocation in multiple arm studies using response adaptive randomization. Clinical Trials, 17, 52–60. [DOI] [PubMed] [Google Scholar]
- Villar S. S., Bowden J., Wason J. (2015a). Multi-armed Bandit Models for the Optimal Design of Clinical Trials: Benefits and Challenges. Statistical Science, 30, 199–215. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Villar S. S., Wason J., Bowden J. (2015b). Response-adaptive randomization for multi-arm clinical trials using the forward looking Gittins Index rule. Biometrics, 71, 969–978. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Villar S. S., Robertson D. S., Rosenberger W. F. (2021). The temptation of overgeneralizing response-adaptive randomization. Clinical Infectious Diseases, 73, e842. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang H., Yee D. (2019). I-SPY 2: a neoaduvant adaptive clinical trial designed to improve outcomes in high-risk breast cancer. Current Breast Cancer Reports, 11, 303–310. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang J. (2021). Response-adaptive trial designs with accelerated Thompson sampling. Pharmaceutical Statistics, 20, 645–656. [DOI] [PubMed] [Google Scholar]
- Wang J., Wu L., Wahed A. S. (2022). Adaptive randomization in a two-stage sequential multiple ASSIGNMENT randomized trial. Biostatistics, 23, 1182–1199. [DOI] [PubMed] [Google Scholar]
- Williamson S. F., Villar S. S. (2020). A response-adaptive randomization procedure for multi-armed clinical trials with normally distributed outcomes. Biometrics, 76, 197–209. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xie M., Singh K. (2013). Confidence distribution, the frequentist distribution estimator of a parameter: A review. International Statistical Review, 81, 3–39. [Google Scholar]
- Zhang K. W., Janson L., Murphy S. A. (2021a). Inference for Batched Bandits. arXiv:2002.03217v3, preprint: not peer reviewed. [PMC free article] [PubMed]
- Zhang K. W., Janson L., Murphy S. A. (2021b). Statistical inference with M-estimators on adaptively collected data. Advances in Neural Information Processing Systems, 34, 7460–7471. [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Web Appendices A–C, referenced in Sections 3–5, and code to implement the simulations, are available with this paper at the Biometrics website on Oxford Academic.
Data Availability Statement
Data sharing is not applicable to this article, as no datasets are generated or analysed. The methods developed will enable design and analysis of future SMARTs.