
Table 5.
Exact match accuracy of our baselines on the test dataset.
| Info length | GPT-4 (%) | GPT-3.5-turbo (%) | BERT-multilabel (%) | BERT-utterance (%) | Random (%) |
|---|---|---|---|---|---|
| Up to day 2 | 13.33 | 0.00 | 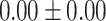 |
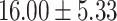 |
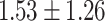 |
| Up to day 3 | 33.33 | 0.00 | 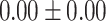 |
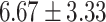 |
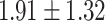 |
| Up to day 4 | 0.00 | 0.00 | 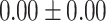 |
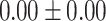 |
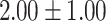 |
| Total | 19.35 | 0.00 | 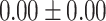 |
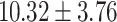 |
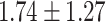 |
For GPT-4 and GPT-3.5-turbo, temperatures were set to 0 to make the models deterministic. For BERT-based models, the models were trained 5 times, and the mean and the standard deviation were recorded. For the Random baseline, it was tested 100 times.
Significant values are in bold.