
Figure 3.
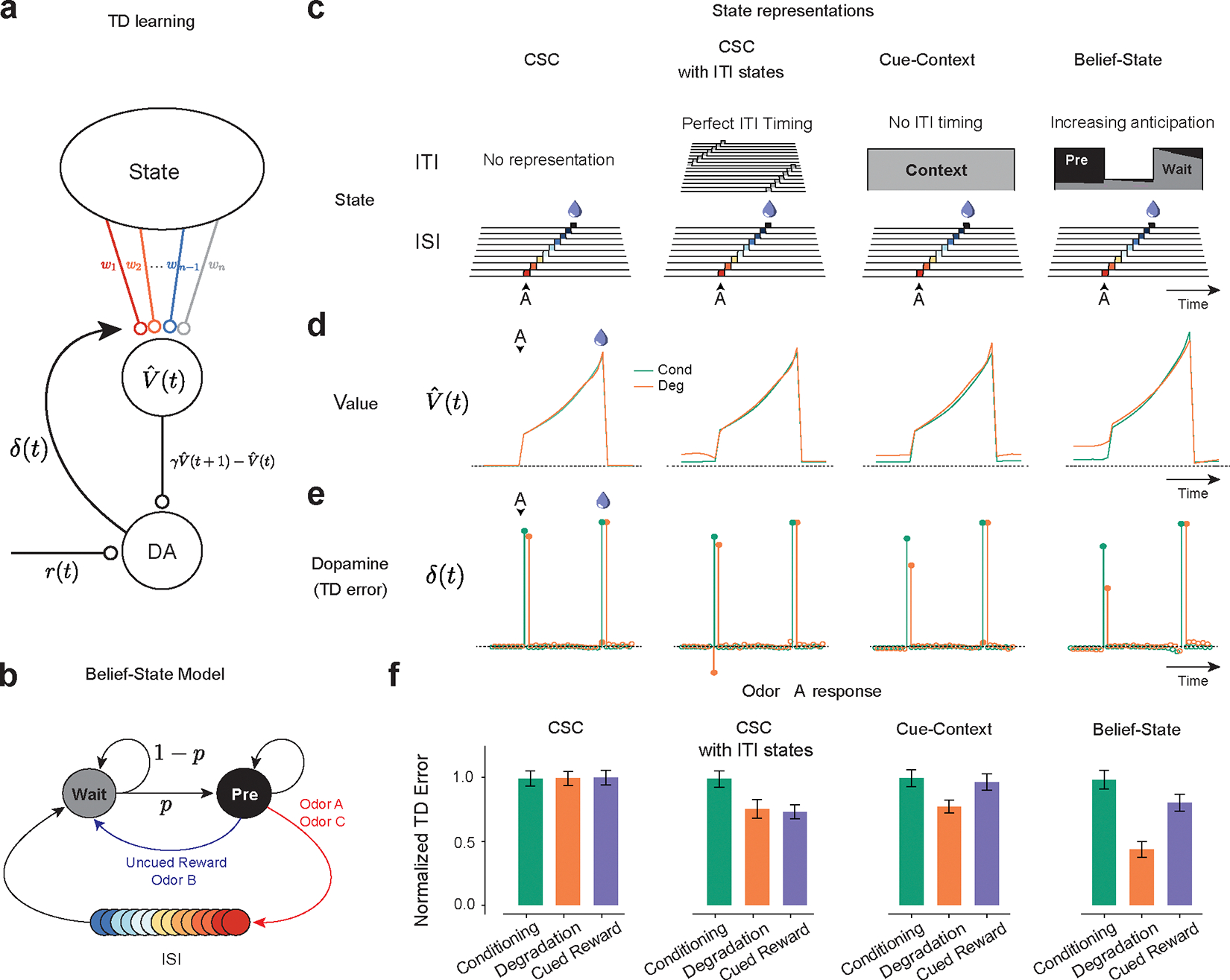
TD learning models can explain dopamine responses in contingency degradation with appropriate ITI representation.
(a) ¬Temporal Difference Zero, TD(0), model – The state representation determines value. The difference in value between the current and gamma-discounted future state plus the reward determines the reward prediction error or dopamine. This error drives updates in the weights.
(b) Belief-State Model: After the ISI, the animal is in the Wait state, transitioning to the pre-transition (‘Pre’) state with fixed probability p. Animal only leaves Pre state following the observation of odor or reward.
(c) State representations: from the left, Complete Serial Compound (CSC) with no ITI representation, CSC with ITI states, Cue-Context model and the Belief-State model.
(d) Value in Odor A trials of each state representation using TD(0) for Conditioning and Degradation conditions
(e) TD error is the difference in value plus the reward.
(f) Mean normalized TD error of Odor A response from 25 simulated experiments. Error bars are SD.