
Figure 6.
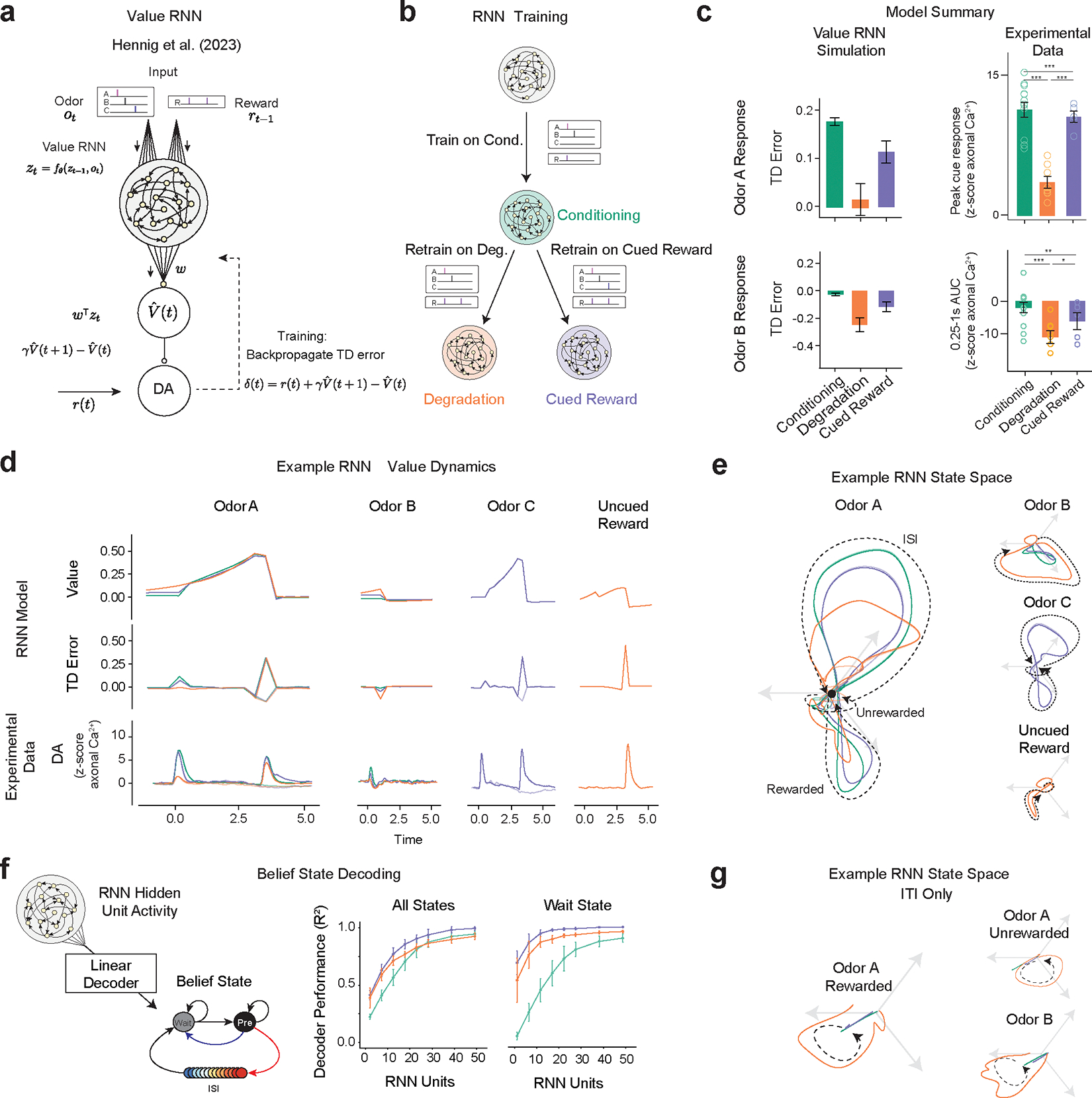
Value-RNNs recapitulate experimental results using state-spaces akin to hand-crafted Belief-State model. For all panels, experimental data: Conditioning (n=13), Degradation (n = 8), Cued Reward (n = 5) error bars are SEM, Extinction (n=7); models (n=25 simulations) error bars are SD;
(a) The Value-RNN replaces the hand-crafted state space representation with an RNN that is trained only on the observations of cues and rewards. The TD error is used to train the network.
(b) RNNs were initially trained on simulated Conditioning experiments, before being retrained on either Degradation or Cued Reward conditions.
(c) The asymptotic predictions of the RNN models (mean, error bars: SD, n = 25 simulations, 50-unit RNNs) closely match the experimental results (see Figure 2f, 5f for statistics). * P < 0.05, **, P < 0.01, *** P < 0.001
(d) Example value, TD error, and corresponding average experimental data from a single RNN simulation. Notably, decreased Odor A response is explained by increased value in the pre-cue period.
(e) Hidden neuron activity projected into 3D space using CCA from the same RNNs used in (d). The Odor A ISI representation is similar in each of the three conditions, and similar to the Odor C representation. Odor B representation is significantly changed in the Degradation condition.
(f) Correspondence between RNN state space and Belief-State model. A linear decoder was trained to predict beliefs using RNN hidden unit activity. With increasing hidden layer size (n=25 each layer size), the RNN becomes increasingly belief-like. The improved performance of the decoder for the Degradation condition is explained by better decoding of the Wait state. Better Wait state decoding is explained by altered ITI representation.
(g) Same RNNs as in (d) and (e), hidden unit activity projected into state-space as (e) for the ITI period only reveals ITI representation is significantly different in the Degradation case.