

Abstract
Accurate dermoscopic lesion segmentation is challenging because existing methods struggle to preserve fine-grained local structures while capturing long-range semantic context, leading to reduced robustness against unclear boundaries, imaging artifacts, and dataset shifts. We propose Hyper-Fusion Segmentation (H-Fusion SEG), a dual-branch framework that combines a boundary-sensitive U-Net encoder–decoder with a Segment Anything Model branch to jointly extract high-resolution local details and robust global semantics. A novel hyper-attention fusion module adaptively integrates these heterogeneous features and is optimized with boundary-aware objectives to enhance delineation and interpretability. On the ISIC-2016 dataset, H-Fusion SEG achieves IoU = 0.8775 and Dice = 0.9269 (+ 1.28% IoU, + 1.38% Dice over baselines), and on ISIC-2018, it achieves IoU = 0.9329 and Dice = 0.9629 (+ 8.69% IoU, + 6.69% Dice over baselines), with strong generalization to the HAM10000 dataset. These gains are particularly pronounced for complex lesions with indistinct or ambiguous boundaries. The proposed framework offers a flexible and generalizable solution for medical image segmentation, with promising potential for precise and reliable computer-aided diagnostic tools in dermatology. Code is available at: https://github.com/AnasHXH/Skin-DiseaseS-Segmentation.
Keywords: Skin lesion segmentation, Hyper-attention fusion, U-Net, Segment anything model (SAM), Dual-encoder architecture, Vision transformers
Subject terms: Cancer, Computational biology and bioinformatics, Diseases, Engineering, Mathematics and computing
Introduction
Skin disorders represent a major global public health challenge, with recent epidemiological reports indicating over 13,000 severe cases diagnosed annually worldwide. While benign lesions remain the most common, the incidence of aggressive dermatological conditions is rising at an estimated rate of 4% per year. Both genetic predispositions and environmental factors, particularly chronic ultraviolet (UV) exposure, are recognized as primary etiological contributors. Moreover, the continued depletion of the stratospheric ozone layer, exacerbated by increasing greenhouse gas emissions, is intensifying ground-level UV radiation, further accelerating this upward trend. In the United States alone, cutaneous malignancies, characterized by pathological alterations in skin texture, pigmentation, and morphology, affect more than five million individuals annually, underscoring the critical importance of early detection and timely intervention. Given that surgical excision can be painful, disfiguring, and psychologically distressing, non-invasive diagnostic approaches, such as dermoscopy, when integrated with computer-aided diagnosis (CAD) systems, have become indispensable tools in contemporary clinical practice1.
The conventional diagnostic pathway for cutaneous malignancies typically begins when a patient presents to a dermatologist with a suspicious skin lesion. The dermatologist conducts a thorough clinical evaluation, comprising detailed visual inspection and a review of the patient’s medical history. When malignancy is suspected, dermoscopy is employed as a non-invasive imaging technique to examine subsurface structures, pigmentation patterns, and vascular features, an assessment that generally requires 10–15 min. If dermoscopic findings remain inconclusive, a definitive diagnosis is obtained through skin biopsy. Following local anesthesia, tissue is excised using a technique chosen according to the lesion’s size and morphology, and the specimen is forwarded to a pathology laboratory. Histopathological examination by a dermatopathologist, focusing on cellular architecture, pleomorphism, and stromal characteristics, typically takes 2–3 days and determines whether the lesion is benign or malignant, as well as its histological subtype. Once malignancy is confirmed, additional staging investigations assess tumor thickness, depth of invasion, regional lymph node involvement, and distant metastasis, alongside grading of cellular differentiation and proliferative activity. Overall, this diagnostic process, from initial consultation to complete staging, can extend to approximately one month, a delay that is particularly critical for patients with rapidly progressing disease2.
Over the past several decades, researchers have sought to shorten the protracted diagnostic pathway for cutaneous lesions, with recent advances in artificial intelligence (AI) offering a promising route to accelerate diagnostic decision-making. Early AI applications in dermatology demonstrated limited accuracy; however, continual improvements in machine learning algorithms, driven by close collaboration among dermatologists, pathologists, and computer scientists, have progressively enhanced predictive performance. These interdisciplinary efforts are enabling the development of advanced digital diagnostic platforms capable of delivering definitive results more rapidly, thereby improving patient prognosis. Within this context, semantic segmentation, the pixel-wise categorization of image data, has become a cornerstone of automated skin-disease assessment. By assigning each pixel to a lesion or background class, segmentation precisely delineates the region of interest (ROI). For example, a clinical photograph of a skin lesion can be transformed into a binary mask that accurately separates pathological tissue from surrounding healthy skin. Over the past decade, significant progress in automated lesion segmentation, longitudinal lesion tracking, and computer-aided decision support has greatly strengthened the clinical applicability and reliability of these techniques3.
Segmentation of cutaneous lesions in dermoscopic images has been approached using both traditional image-processing pipelines and modern machine-learning frameworks. Within the latter category, AI methods, such as convolutional neural networks (CNNs)3, fuzzy-logic–based models4, attention-driven architectures5, and various hybrid approaches, have gained prominence due to their superior accuracy, robustness, and reproducibility. Nevertheless, dermoscopic data present persistent challenges: substantial variability in texture, scale, morphology, and lesion location, combined with indistinct lesion boundaries, often hampers the generation of anatomically precise, pixel-level segmentation masks. Addressing this heterogeneity is essential to further improve the performance and clinical reliability of CAD systems.
Contemporary lesion-segmentation pipelines typically incorporate both pre-processing and post-processing stages to enhance image quality and improve delineation accuracy. Common operations include morphological transformations, median filtering, and anisotropic-diffusion filtering, which collectively remove artefacts, improve resolution, and preserve critical edge details. For example, Beuren et al.6 applied morphological operators for denoising and structural enhancement, while Chatterjee et al.7 proposed a pre-processing framework that integrates Fractal Region Texture Analysis (FRTA) with Recursive Feature Elimination (RFE) for robust feature selection. Verma8 demonstrated that anisotropic-diffusion filtering can simultaneously smooth dermoscopic images, remove hair artefacts, and retain salient lesion boundaries. More recent studies have explored modified morphological schemes and image-inpainting strategies to achieve similar outcomes9. In line with these advances, the present study incorporates targeted inpainting to remove occluding hairs from input images.
Over the past decade, the emergence of advanced deep-learning architectures, such as R-CNN10, U-Net11, Vision Transformers12, and MLP-Mixer13, has revolutionized medical-image segmentation, consistently surpassing the performance of conventional algorithms14–16. Despite these advances, key challenges remain. Supervised frameworks require large volumes of high-quality ground-truth annotations; however, assembling such expertly labelled medical datasets is constrained by the substantial time investment and specialized expertise needed. While various unsupervised and self-supervised approaches have been introduced, their lack of explicit segmentation masks often limits accuracy and repeatability. Moreover, the intrinsic heterogeneity of cutaneous malignancies, reflected in wide variations in lesion size, shape, color, and texture, and the presence of confounding background structures such as sweat glands, vasculature, and hair continue to hinder robust and generalizable lesion delineation.
Zero-shot learning (ZSL) offers a promising alternative to conventional, label-intensive segmentation paradigms by enabling models trained on a source domain to delineate object categories they have not previously encountered17. ZSL frameworks achieve this by establishing semantic mappings between learned visual representations and textual or class-level descriptors, thereby generalizing segmentation capabilities to novel classes. The Segment Anything Model (SAM) represents the current state of the art in ZSL-based segmentation18. Trained on over 11 million images paired with dense masks, SAM combines extensive pre-training with prompt-conditioned inference, allowing users to interactively refine segmentation outputs. Its architecture incorporates multi-scale feature fusion and attention mechanisms to capture both local detail and global context19–21, achieving benchmark-leading performance across diverse datasets22,23. Building on these advances, we introduce Hyper-Attention Fusion U-Net with SAM Segmentation (H-Fusion SEG), a hybrid framework that integrates SAM’s robust zero-shot capabilities with a U-Net backbone enhanced by Hyper-Attention fusion layers. We systematically evaluate the model on three publicly available skin-lesion datasets. Experimental results demonstrate H-Fusion SEG’s strong performance in segmenting heterogeneous cutaneous lesions, while also identifying current limitations and highlighting potential directions for future advancements in skin-cancer segmentation. The primary research contributions of this study are as follows:
Proposes a novel integration of a SAM encoder with a U-Net framework built on ResNet-101, augmented by patch embedding, hyper-attention, and a fusion mechanism to enhance multi-scale feature extraction and enable precise lesion delineation.
Incorporates advanced mechanisms, including patch embedding for capturing fine-grained local details and hyper-attention for dynamic feature prioritization, thereby improving segmentation performance across diverse skin-lesion types.
Addresses a notable research gap by applying transformer-based segmentation methods to the HAM10000 dataset, covering a broad spectrum of dermatological conditions and achieving superior lesion-identification accuracy.
Validates the proposed framework through comprehensive comparisons with leading deep-learning models, demonstrating state-of-the-art performance across multiple benchmark datasets.
The remainder of this article is organized as follows: Section "Related works" surveys the most relevant literature on skin-lesion segmentation. Section "Materials and methods" details the proposed methodology. Section "Performance evaluation stage" describes the experimental setup and evaluation protocol, while Section "Experiments results" presents and analyzes the quantitative and qualitative results obtained on the HAM10000, ISIC-2016, and ISIC-2018 benchmarks. Section "Discussion" discusses the strengths and limitations of the proposed approach and outlines potential directions for future research. Finally, Section "Conclusion" concludes the paper and summarizes the main contributions.
Related works
Skin-lesion segmentation techniques are typically categorized into three principal groups: (i) edge-detection and thresholding methods24, (ii) active-contour models25, and (iii) convolutional neural network (CNN)-based approaches26,27. Each category presents distinct advantages but also inherent limitations in achieving accurate and consistent lesion delineation. Within the CNN-based domain, the symmetric encoder–decoder architecture U-Net, originally proposed by Ronneberger et al.11, has emerged as a benchmark standard. U-Net integrates a contracting path, which captures rich semantic and contextual features, with an expansive decoding path that restores spatial resolution and enables precise localization of the region of interest.
Subsequent refinements to U-Net have focused on improving feature fusion and architectural efficiency. U-Net++, proposed by Zhou et al.28, introduces densely connected skip pathways to bridge the semantic gap between encoder and decoder, resulting in richer feature representations and enhanced performance over the original U-Net across multiple biomedical segmentation benchmarks. Architectural optimization has also benefited from neural architecture search (NAS); Weng et al.29 integrated NAS into a U-Net backbone to automatically identify network topologies that further boost segmentation accuracy. Beyond the U-Net family, SegNet30 employs a VGG16 encoder with a customized decoder and pixel-wise classification layer, achieving state-of-the-art results across diverse segmentation tasks. Fully convolutional–deconvolutional architectures have also shown strong potential, Yuan31, for example, reported a Dice coefficient of 0.765 on the ISIC-2017 dataset, highlighting the effectiveness of end-to-end convolutional frameworks in skin-lesion segmentation.
Abraham32 introduced the Focal Tversky Loss, which, when combined with an attention-enhanced U-Net, improved lesion segmentation performance on the BUS-2017B and ISIC-2018 benchmarks, achieving Dice coefficients of 0.804 and 0.856, respectively. Extending the encoder–decoder paradigm, D-U-Net33 incorporates two parallel up-sampling paths to generate complementary segmentation maps, attaining a Dice score of 0.892 on the ISIC-2017 dataset. More recently, meta-heuristic optimization has been leveraged for threshold-based segmentation and image enhancement; for example, Aljanabi34 proposed an artificial-bee-colony-driven threshold-selection method that yielded robust feature maps across multiple skin-lesion datasets. Attention mechanisms have also proven effective in refining convolutional feature representations: Chattopadhyay35 designed a multi-scale attention module for precise object localization, while Fu et al.36 developed a dual-attention framework that adaptively fuses local and global cues, a strategy subsequently adopted in biomedical imaging37. In parallel, Generative Adversarial Networks (GANs) have emerged as a powerful segmentation tool, driving several state-of-the-art approaches in recent medical-imaging literature38.
Recent research has continued to advance automated skin-lesion segmentation through increasingly sophisticated deep-learning architectures. Mustafa et al.39 combined the densely connected residual blocks of ResUNet++ with a post-hoc AlexNet feature extractor and a Random Forest classifier, effectively coupling fine-grained spatial encoding with ensemble-based regularization. When evaluated on the HAM10000 dataset, this hybrid model achieved state-of-the-art Dice and IoU scores while mitigating overfitting. In a related effort, Himel et al.40 integrated a Vision Transformer with the SAM, leveraging long-range self-attention to capture global context and refine lesion boundaries. Their transformer-augmented framework likewise delivered superior segmentation metrics on HAM10000, underscoring the increasing potential of attention-based models to match, and in some cases surpass, the performance of conventional CNN architectures61.
Semantic segmentation remains central to clinical decision-making yet continues to face persistent challenges, including reconciling long-range (global) and local feature transmission, inconsistent benchmarking practices, ambiguous boundaries, co-occurrence artifacts, and the difficulty of segmenting small or numerous objects from limited annotations. To address these issues, WNet/nnWNet rethinks encoder–decoder design by tightly integrating transformers with convolutions, enabling continuous transmission and multi-scale fusion of global and local features. Embedded within the nnUNet framework, WNet achieves state-of-the-art results across multiple 2D (DRIVE, ISIC-2017, Kvasir-SEG, CREMI) and 3D (Parse2022, AMOS22, BTCV, ImageCAS) benchmarks62. In parallel, IPA-CP, a semi-supervised segmentation method for CT, couples iterative pseudo-label refinement with uncertainty-guided adaptive copy–paste augmentation in a mean-teacher setup, producing more reliable pseudo labels and significantly improving performance on both public and proprietary datasets, particularly for small or densely distributed lesions63. Similarly, ConDSeg, a contrast-driven framework, introduces Consistency Reinforcement for contrast-robust encodings, a Semantic Information Decoupling module to separate foreground, background, and uncertainty, Contrast-Driven Feature Aggregation for enhanced multi-level fusion, and a Size-Aware Decoder to manage scale variation. These innovations collectively improve boundary delineation and mitigate co-occurrence errors, delivering strong performance across five heterogeneous datasets64. Collectively, these approaches demonstrate how advances in architectural design, semi-supervised learning, and feature-contrast strategies are making medical-image segmentation more accurate, robust, and widely applicable.
The integration of semi-supervised and ensemble learning strategies has shown considerable promise in addressing both the variability of dermoscopic images and the limited availability of annotated medical data. Dzieniszewska et al.41 demonstrated that a self-training framework based on the Noisy Student paradigm, employing DeepLabV3 with ResNet backbones as teacher and student networks, can effectively exploit unlabeled data to enhance segmentation performance on benchmarks such as ISIC 2018 and PH2. Ensemble approaches that aggregate predictions from multiple segmentation architectures (e.g., U-Net, SegNet, and DeepLabV3) have also proven effective: Thwin and Park42 reported that a weighted averaging of masks from diverse models yielded more robust and accurate lesion delineation than any single model alone. These findings underscore the potential of combining semi-supervised learning with ensemble methods to produce reliable, clinically relevant segmentation systems58, 59. Building on this foundation, our H-Fusion SEG model integrates SAM’s large-scale, zero-shot global representations with a Hyper_Attention-enhanced U-Net encoder, enabling the capture of both long-range contextual cues and fine-grained lesion boundaries. Experimental results show that this hybrid design consistently outperforms recent ResUNet++ hybrids, transformer-based models, and ensemble frameworks in terms of Dice and IoU scores. Furthermore, the adaptive feature-fusion module achieves these gains without incurring the parameter overhead or inference latency typical of vision-transformer or multi-network ensembles, making the approach not only more accurate but also well-suited for real-time clinical deployment.
Materials and methods
This study presents a novel hybrid deep-learning framework for skin-lesion segmentation that integrates a SAM encoder with a U-Net architecture based on ResNet-101, further enhanced by patch embedding, a Hyper_Attention module, and a multi-scale fusion block (Fig. 1). The proposed pipeline comprises two main stages: preprocessing and lesion segmentation. In the segmentation stage, the SAM encoder and the ResNet-101 backbone within the U-Net structure jointly exploit their complementary strengths, SAM’s large-scale contextual modeling and ResNet-101’s robust hierarchical feature extraction, to accurately differentiate diseased regions from surrounding healthy skin. The patch embedding mechanism enables the capture of fine-grained local textures, while the Hyper_Attention module adaptively prioritizes salient spatial regions, thereby improving boundary precision. The fusion block consolidates multi-scale local and global features into a coherent representation, enhancing segmentation consistency and accuracy. The effectiveness of this integrated design is validated through extensive experiments on the HAM10000 dataset, where the method demonstrates superior performance relative to state-of-the-art segmentation approaches60.
Fig. 1.

Proposed multi-class skin-lesion segmentation framework integrating SAM, U-Net, patch embedding, hyper attention, and fusion block.
Dataset description
This study utilizes the HAM10000 dataset, comprising 10,015 dermoscopic images and their corresponding segmentation masks, to train and validate the proposed skin-lesion segmentation framework. The dataset encompasses a diverse range of dermatological conditions, making it a valuable resource for developing models capable of capturing the heterogeneous characteristics of skin lesions, including variations in size, shape, color, and texture. Its extensive, expertly annotated image collection exposes the model to both subtle and complex lesion patterns, thereby improving its ability to generalize across diverse clinical presentations. Prior to training, all images underwent standard preprocessing, including resizing, normalization, and data augmentation, to ensure input consistency and enhance robustness against overfitting. Leveraging the comprehensive coverage and high-quality annotations of HAM10000 provides a solid foundation for accurate and generalizable lesion segmentation43.
In the testing phase, the proposed technique underwent rigorous evaluation using three independent benchmark datasets: HAM10000, ISIC 2016, and ISIC 2018. From each dataset, 800 samples were randomly selected to ensure a balanced and unbiased assessment of the model’s segmentation capabilities. These datasets were deliberately chosen for their distinct imaging protocols, annotation styles, and lesion diversity, thereby providing a comprehensive platform to test the model’s adaptability to heterogeneous clinical conditions. The evaluation process aimed to simulate real-world deployment scenarios, where dermoscopic images originate from different acquisition devices, lighting conditions, and clinical annotation standards. By incorporating such diversity, the multi-dataset evaluation strategy served as a robust measure of generalization, challenging the model to perform consistently across variations in lesion morphology, size, color, and boundary definition, as illustrated in Fig. 2. The findings from these evaluations not only confirmed the model’s high segmentation accuracy but also provided strong evidence of its robustness and potential suitability for integration into clinical workflows for automated skin lesion detection, segmentation, and subsequent analysis44,45.
Fig. 2.

Sample images from the HAM10000, ISIC 2016, and ISIC 2018 datasets 43–45.
Pre-processing stage
The preprocessing stage begins with the systematic loading of raw data from predefined directories, as depicted in Fig. 3. Both the dermoscopic skin images (in RGB format) and their corresponding segmentation masks (in grayscale) are read using the Python Imaging Library (PIL), ensuring that all input files are accurately imported and ready for subsequent operations. Following data ingestion, the images and masks are processed through a dedicated data augmentation module designed to enhance variability and reduce overfitting. Specifically, a custom Segmentation Augmentation class applies random horizontal flips and rotations, introducing spatial diversity to the training set. The augmented images are then resized to a standardized resolution, 1024 × 1024 pixels for RGB images to preserve fine structural details, and 64 × 64 pixels for masks to maintain computational efficiency while retaining essential boundary information. This preprocessing workflow plays a critical role in improving the generalization capacity of the proposed method, enabling it to perform robustly across diverse skin lesion appearances and imaging conditions.
Fig. 3.

Block diagram of the proposed data preprocessing pipeline.
The core operation in this stage is bounding box extraction. Utilizing the get_bounding_box module, the algorithm determines the smallest rectangle that fully encloses the nonzero (i.e., lesion) pixels in the mask. This bounding box is subsequently used to prepare the input for the SAM branch by passing it, along with the original RGB image, to the SAM processor. The SAM processor generates a set of tensors encapsulating both high-level image features and spatially contextual information corresponding to the detected lesion area. In parallel, preprocessing for the U-Net branch is performed. Here, the augmented image tensor is resized to a fixed resolution of 256 × 256 pixels via the preprocess_for_unet module, ensuring standardized input dimensions essential for the encoder–decoder architecture to operate effectively. Finally, the processed SAM inputs (bounding box data, extracted features, and ground truth masks), the resized U-Net inputs, and the transformed masks are merged into a unified dataset, as illustrated in Fig. 3. This integrated dataset is then fed into data loaders for training and validation, guaranteeing that each batch contains synchronized inputs for both branches, thereby enabling the proposed dual-encoder framework to jointly leverage SAM’s global feature extraction and U-Net’s fine-grained segmentation capabilities for accurate skin lesion analysis.
Proposed skin lesion segmentation model
The core strength of the proposed approach lies in the synergistic integration of the SAM and U-Net models, as illustrated in Fig. 4. The U-Net branch specializes in capturing fine-grained local spatial information, including subtle texture variations, boundary irregularities, and small-scale morphological features. In contrast, the SAM branch contributes robust global contextual understanding and strong generalization capabilities, enabling effective adaptation to diverse lesion shapes, sizes, and appearances.
Fig. 4.

Block diagram of the proposed H-Fusion-SEG model.
A dedicated Fusion Module is employed to align and harmonize encoder outputs from both branches, even when they differ in spatial resolution. This ensures that complementary global and local features are coherently merged without the loss of clinically significant information. Following this, a Hyper Attention Module selectively amplifies the most diagnostically relevant regions, particularly those with ambiguous lesion boundaries or nuanced chromatic variations, thereby reducing false positives and improving boundary delineation.
By strategically orchestrating the complementary strengths of the SAM’s global perception and U-Net’s local precision, the proposed architecture effectively addresses the heterogeneity of skin lesions, from small, well-defined nevi to large, irregular melanomas. This hybrid design achieves superior segmentation accuracy and consistency, making it particularly well-suited for clinical applications where early and precise lesion identification is critical for improved patient outcomes.
The left side of the H-Fusion-SEG architecture, depicted in Fig. 4, represents the SAM branch, which begins with the SAM Input and a Patch Embedding module. At this stage, the input image is divided into smaller, non-overlapping patches and transformed into an embedded representation that preserves both fine-grained pixel relationships and broader contextual dependencies. These embedded patches are sequentially processed by a series of SAM Encoders (SAM_Encoder_1 through SAM_Encoder_6), each progressively refining the feature maps. Lower-level encoders primarily capture local structural cues such as edges, textures, and fine contours, while higher-level encoders emphasize global semantics, including lesion morphology and its relationship to surrounding skin tissue.
To maintain the integrity of multi-scale information, channel concatenations are performed at various encoder depths, ensuring that early-stage fine details are effectively preserved alongside deeper, high-level abstractions. The resulting multi-resolution feature maps are then passed to the Fusion Module, which spatially and semantically aligns the encoder outputs, enabling the integration of complementary spatial, semantic, and textural cues. Subsequently, the Hyper Attention Module adaptively enhances diagnostically significant regions, such as areas with subtle pigment variations or indistinct lesion borders, while suppressing irrelevant background information. This targeted attention mechanism strengthens the model’s ability to detect and delineate even the most subtle skin abnormalities.
The SAM encoder is designed to extract semantically rich and generalizable features from diverse input images by leveraging a high-capacity Vision Transformer (ViT) backbone. As depicted in Fig. 5, the SAM branch processes input images of size (3 × 1024 × 1024) through an initial sequence of normalization and convolutional operations that adapt them to the ViT’s architectural requirements. Specifically, a 3 × 3 convolution followed by normalization refines the raw image data, enhancing local spatial coherence and preparing it for effective patch embedding. This is followed by a 1 × 1 convolution that reduces the channel dimensionality to 256, ensuring compatibility with the ViT’s tokenization process, in which the image is partitioned into a sequence of embedded tokens. This transformation facilitates efficient modeling of both local and long-range dependencies within the image. As noted by Ronneberger et al.11, the transformer-based encoder enables SAM to acquire robust, domain-agnostic representations, making it highly adaptable to varied downstream segmentation tasks, even in the presence of substantial domain shifts.
Fig. 5.

Architecture of the SAM encoder used in the proposed model.
At the core of the encoder lies the ViT-H Vision Transformer, which processes the embedded tokens through multiple self-attention blocks to capture both local and global contextual features46. The multi-head self-attention mechanism enables the model to attend to diverse spatial regions of the image simultaneously, thereby improving its capacity to delineate lesion boundaries, recognize fine-grained textures, and model complex structural variations. Throughout the encoder, skip connections and normalization layers are employed to maintain high-fidelity feature representations across multiple resolutions, ensuring that critical spatial and semantic details are preserved for subsequent stages. As highlighted in11, this architectural design is particularly advantageous in medical imaging, where substantial variability in lesion shape, size, and appearance is common. The encoder ultimately produces feature maps of dimension (256 × 64 × 64), which provide a robust and semantically rich foundation for the segmentation-specific processing that follows.
The U-Net segmentation model, originally introduced in11, builds upon the foundational framework of Fully Convolutional Networks (FCNs) by adopting an encoder–decoder architecture that is distinctly divided into three primary components. The first component, the down-sampling path, utilizes ResNet-101 as its backbone and is organized into four hierarchical stages. In each stage, two successive 3 × 3 convolutional layers with batch normalization are applied, followed by a 2 × 2 max-pooling operation to progressively reduce the spatial resolution while enriching feature abstraction, as illustrated in Fig. 6. The bottleneck section, positioned at the center of the architecture, comprises two 3 × 3 convolutional layers followed by a 2 × 2 up-convolution, facilitating the transition from encoding to decoding. The final component, the up-sampling path or decoder, mirrors the structure of the encoder with four stages, where each stage incorporates two 3 × 3 convolutional layers and one 2 × 2 up-sampling operation. This design progressively restores the spatial resolution of the feature maps while integrating contextual information from the encoder through skip connections, enabling precise localization for segmentation tasks.
Fig. 6.

Architecture of the U-Net model based on the ResNet101 backbon.
As depicted in Fig. 6, skip connections are strategically incorporated between the corresponding stages of the down-sampling and up-sampling paths. These connections enable the direct transfer of high-resolution feature maps from the encoder to the decoder, thereby preserving fine-grained spatial details that may otherwise be lost during the pooling operations. This mechanism facilitates the effective fusion of local texture details with global contextual information, enhancing the network’s ability to accurately delineate lesion boundaries. At the final output stage, a 1 × 1 convolutional layer is applied to map the aggregated feature representations to the desired number of segmentation classes, generating precise feature maps corresponding to the target lesion regions11.
The Fusion Module serves as a critical component that harmonizes the complementary feature representations extracted from the ResNet encoder and the SAM encoders, as illustrated in Fig. 4. To ensure seamless integration, the module first aligns the spatial dimensions of the SAM-derived features with those from the ResNet pathway, employing bilinear interpolation when dimensional discrepancies are detected. Once spatial alignment is established, the features from both branches are concatenated along the channel dimension to form a unified composite feature map. This combined representation is subsequently processed through a 4 × 4 convolutional layer with appropriate padding, followed by batch normalization and a ReLU activation function to enhance feature discrimination. A dropout layer is then applied to mitigate overfitting, thereby improving the model’s generalization capabilities. By integrating fine-grained local features from the ResNet encoder with the rich global context provided by the SAM branch, the Fusion Module significantly strengthens segmentation accuracy, an approach consistent with recent advancements in multimodal feature integration47.
The Hyper Attention module is instrumental in refining feature representations by employing a self-attention mechanism to capture both local and global contextual information. The process begins with flattening the input feature map, followed by layer normalization to stabilize gradient flow and ensure consistent feature scaling. A multi-head attention mechanism, inspired by transformer architectures48, is then applied to compute attention weights across the flattened features. This enables the model to selectively focus on the most salient regions, as illustrated in Fig. 4. By re-weighting the features based on interdependencies between different spatial locations and channels, the module enhances the network’s capacity to identify critical patterns, particularly in complex or heterogeneous lesion structures.
Subsequently, the module employs a multi-layer perceptron (MLP) with dropout regularization to introduce non-linear transformations and further refine the attention-enhanced features. The MLP boosts the discriminative capability of the learned representations, while residual connections implemented through additive shortcuts preserve the original feature information, ensuring that beneficial characteristics from earlier stages are retained. By dynamically recalibrating the feature responses, the Hyper Attention stage substantially improves the model’s segmentation performance, enabling more precise delineation of object boundaries and robust handling of complex or ambiguous segmentation scenarios.
Performance evaluation stage
Pixel Accuracy (PACC) is one of the most widely adopted parameters for evaluating image segmentation models. It measures segmentation precision by comparing predicted outputs with the ground truth on a per-pixel basis. Specifically, PACC represents the percentage of correctly classified pixels relative to the total number of pixels, reflecting the model’s ability to assign each pixel to its correct category. While straightforward and intuitive, PACC does not account for class imbalances or spatial relationships between pixels. Consequently, it may not fully capture segmentation quality in tasks where precise boundary delineation or the prioritization of specific classes is critical. To address these limitations, PACC is often complemented with more comprehensive metrics such as Intersection over Union (IoU) and Dice Similarity Coefficient (Dice), which evaluate the degree of overlap between predicted and ground truth masks, providing a more nuanced assessment of segmentation performance.
The IoU metric is defined as the ratio between the intersection and the union of the predicted segmentation mask and the corresponding ground truth mask, as illustrated in Fig. 7. IoU quantifies the similarity between the two masks by simultaneously considering true positive predictions and penalizing false positives and false negatives. This makes it a more comprehensive evaluation metric than PACC, which only measures the correctness of individual pixels without considering the spatial overlap of segmented regions. By incorporating both spatial relationships and the extent of overlap, IoU offers a more precise assessment of how well the predicted regions align with the target structures. The mathematical formulation of IoU is expressed in Eq. (1):
| 1 |
Fig. 7.

Schematic illustration of the IoU principle, depicting the overlapping and non-overlapping regions between the predicted segmentation mask and the ground truth.
The Dice measures the degree of overlap between the predicted segmentation mask and the ground truth by calculating the ratio of twice the intersection area to the sum of the areas of both masks. This formulation inherently balances precision and recall, making it particularly effective in evaluating segmentation tasks where class imbalance is prevalent. Similar to IoU, the Dice coefficient emphasizes the spatial overlap between segmented regions, thereby offering a more informative measure than PACC alone. The mathematical definition of the Dice coefficient is provided in Eq. (2):
| 2 |
In our framework, we employ a composite loss function that integrates Binary Cross-Entropy (BCE) with logits and IoU loss to optimize the segmentation model. The BCE component is implemented using PyTorch’s BCEWithLogitsLoss, which combines the sigmoid activation with the binary cross-entropy loss in a numerically stable manner. This loss operates on a per-pixel basis, effectively penalizing discrepancies between the predicted logits and the binary mask. Helper functions such as prepare_target and prepare_bce_targets ensure that the target masks are reshaped, typically to a [B, 1, H, W] tensor, thereby guaranteeing compatibility with the loss computation. Additionally, the get_preds function applies a sigmoid activation followed by thresholding to convert raw logits into binary segmentation masks, facilitating evaluation of prediction accuracy. The Binary Cross-Entropy loss is formally defined as:
| 3 |
where 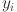 is the ground truth label for pixel
is the ground truth label for pixel 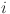 ,
,  is the raw logit for pixel , N is the total number of pixels, and σ(⋅) denotes the sigmoid activation function.
is the raw logit for pixel , N is the total number of pixels, and σ(⋅) denotes the sigmoid activation function.
Complementing the pixel-wise BCE loss, the IoU loss is computed to capture the spatial overlap between the predicted segmentation and the ground truth. This loss function first converts the network outputs into probability maps via the sigmoid activation (for binary segmentation) and then calculates the IoU between the predicted and true masks across spatial dimensions. The negative logarithm of the IoU is taken to form the loss, thereby penalizing poor overlap between segmented regions. By combining the BCE and IoU losses through a weighted sum, the model is guided to optimize both local pixel-level accuracy and global region-level consistency. This dual-loss strategy leverages the complementary strengths of pixel-wise and region-based metrics, fostering a more robust training process and yielding more accurate delineation of skin lesions.
The IoU loss and the combined loss function are defined as:
| 4 |
| 5 |
| 6 |
where  and
and 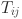 denote the predicted probability and ground truth label at pixel position
denote the predicted probability and ground truth label at pixel position 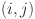 , respectively; ϵ is a small smoothing constant to avoid division by zero; and
, respectively; ϵ is a small smoothing constant to avoid division by zero; and  and
and 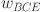 are the respective weights assigned to the IoU and BCE loss terms. This composite loss formulation effectively balances fine-grained pixel accuracy with spatial overlap, a strategy shown to enhance segmentation performance in diverse applications11,47.
are the respective weights assigned to the IoU and BCE loss terms. This composite loss formulation effectively balances fine-grained pixel accuracy with spatial overlap, a strategy shown to enhance segmentation performance in diverse applications11,47.
Experiments results
This section presents the experimental results validating the effectiveness of the proposed H-Fusion-SEG model for skin disease segmentation. The model was trained using the HAM10000 dataset and subsequently evaluated on independent test sets drawn from HAM10000, ISIC 2016, and ISIC 2018, with 800 randomly selected images from each dataset. Quantitative evaluation was performed using standard segmentation metrics, including IoU, Dice coefficient, pixel accuracy, sensitivity, and specificity. The results demonstrate that the proposed approach consistently outperforms baseline methods, particularly in accurately delineating lesion boundaries and capturing complex lesion morphologies. In addition, ablation studies confirm that integrating the hyper attention module and fusion block markedly improves performance by effectively merging multi-scale feature representations. Overall, these findings highlight the robustness and generalizability of the H-Fusion-SEG framework, underscoring its potential for reliable deployment in clinical workflows for automated skin lesion analysis.
All experiments were implemented in PyTorch, leveraging its flexibility for integrating both the SAM encoder and Vision Transformer-based modules through PyTorch-compatible interfaces. To ensure reproducibility and prevent dependency mismatches, the models were executed within an isolated, version-controlled environment.
Model training was conducted on Google Colab Pro, utilizing high-memory virtual machine configurations equipped with either an NVIDIA T4 or P100 GPU and 25 GB of RAM. A conditional training strategy was adopted, wherein the optimal generator weights were preserved during each batch evaluation to maintain stable convergence and prevent performance degradation. This strategy is particularly advantageous in deep segmentation tasks, as it mitigates overfitting and preserves the most robust feature representations during training47.
To achieve optimal performance, hyperparameter tuning was performed through an iterative search process, balancing convergence speed and generalization. The finalized configuration for the H-Fusion-SEG model is summarized in Table 1, reflecting the parameters that yielded the highest evaluation scores across validation sets.
Table 1.
Hyperparameter optimization settings for the H-fusion-SEG model.
| Hyperparameter | Value |
|---|---|
| Epochs | 50 |
| Mini-batch size | 8 |
| Learning rate | 1 × 10⁻4 |
| Optimization method | Adam optimizer |
| Objective-loss function | Combined loss (binary cross-entropy + intersection over union) |
Model complexity and inference speed
In addition to segmentation accuracy, evaluating the computational efficiency of the proposed H-Fusion-SEG model is critical for determining its feasibility in real-world clinical applications. We benchmarked model complexity using three key indicators: the number of trainable parameters, floating-point operations (FLOPs), and inference speed measured in frames per second (FPS). These metrics were compared against representative baseline architectures, SkinSAM50, U-Net42, and ResUNet++39, which have been widely adopted in medical image segmentation tasks.
All evaluations were performed on an NVIDIA T4 or P100 GPU with a batch size of 1 and input resolution of 256 × 256, using PyTorch FP32 precision unless otherwise specified. FLOPs were computed as twice the number of multiply–accumulate operations (MACs), while inference speed was determined by averaging the runtime over 100 forward passes, excluding the first 10 warm-up iterations to account for GPU initialization effects.
As summarized in Table 2, the proposed H-Fusion-SEG exhibits a substantially higher parameter count (222.39 M) and computational demand (202.46 GFLOPs) compared to U-Net and ResUNet++, primarily due to the integration of multi-scale hyper-attention mechanisms and transformer-based fusion modules. While this results in a reduced FPS (1.93), the model achieves state-of-the-art segmentation performance (as reported in Sect. 5.3), making it suitable for scenarios where accuracy outweighs real-time requirements, such as offline clinical diagnostics and teledermatology platforms.
Table 2.
Comparison of model complexity and inference speed for the proposed H-Fusion-SEG and baseline models. Parameters are reported in millions (M), FLOPs in giga-floating point operations (GFLOPs), and FPS values averaged over 100 forward passes (batch size = 1, input size = 256 × 256).
Despite its higher computational footprint, the H-Fusion-SEG achieves superior boundary delineation, improved lesion shape preservation, and enhanced segmentation accuracy across multiple benchmark datasets. In clinical practice, these benefits can directly translate to more reliable diagnoses and reduced risk of missed lesion features, which is particularly critical in early skin cancer detection. Therefore, while the model may not be optimal for real-time mobile applications, its performance profile makes it a strong candidate for offline diagnostic systems, batch image processing pipelines, and decision-support tools in dermatology where accuracy is paramount.
The proposed H-Fusion-SEG model incurs a higher computational cost primarily due to the integration of a pre-trained SAM branch with a high-capacity U-Net encoder–decoder and the Hyper_Attention fusion module. Nevertheless, it achieves state-of-the-art segmentation accuracy (see Sect. "Training and evaluation results"–5.4) while maintaining a feasible inference speed for offline clinical workflows. The increased parameter count and FLOPs are justified by the substantial performance gains, particularly in accurately delineating lesions with indistinct boundaries and in handling challenging imaging conditions.
Training and evaluation results
The results presented in this section collectively highlight the robustness and effectiveness of the proposed H-Fusion-SEG architecture across multiple evaluation scenarios. The progressive improvements observed in Table 3 confirm that each architectural enhancement, starting from the baseline U-Net, through the integration of SAM, and culminating in the addition of the Hyper-Attention module, contributes measurably to segmentation accuracy and stability. Notably, the complete framework achieves a superior balance between sensitivity and specificity, indicating its capability to detect lesion boundaries with high recall while minimizing false positives. These gains are particularly significant in the context of challenging dermoscopic images, where lesions often exhibit fuzzy borders, color irregularities, and low contrast against surrounding skin. The consistent reduction in validation loss further demonstrates that the proposed design not only boosts performance metrics but also enhances generalization, making it well-suited for deployment in clinical decision-support systems where reliability is paramount.
Table 3.
Progressive architectural enhancement analysis on HAM10000 dataset.
| Model configuration | Loss train | Loss valid | PACC train | PACC valid | Dice train | Dice valid | IoU train | IoU valid | Sensitivity train | Sensitivity valid | Specificity train | specificity valid |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| U-Net (Baseline) | 0.124 | 0.182 | 0.955 | 0.948 | 0.895 | 0.852 | 0.739 | 0.642 | 0.900 | 0.872 | 0.976 | 0.915 |
| U-Net + SAM | 0.114 | 0.162 | 0.961 | 0.948 | 0.959 | 0.927 | 0.936 | 0.902 | 0.959 | 0.910 | 0.972 | 0.946 |
| + Hyper-Attention | 0.105 | 0.153 | 0.979 | 0.960 | 0.974 | 0.946 | 0.959 | 0.913 | 0.972 | 0.973 | 0.973 | 0.971 |
| Complete Framework | 0.102 | 0.150 | 0.987 | 0.969 | 0.980 | 0.958 | 0.961 | 0.925 | 0.973 | 0.954 | 0.975 | 0.972 |
Segmentation performance analysis
The ablation study results summarized in Table 3 clearly demonstrate the cumulative benefits of the proposed architectural enhancements. Starting from the baseline U-Net configuration, the model achieved a validation Dice score of 0.852 and IoU of 0.642, establishing a reference point for subsequent improvements. Integrating the pre-trained SAM into the U-Net architecture markedly improved segmentation accuracy, increasing the validation Dice to 0.927 and IoU to 0.902, alongside a consistent reduction in validation loss from 0.182 to 0.162. These improvements underscore the strong generalization capacity of SAM-driven contextual feature representations.
The subsequent introduction of the Hyper-Attention module provided an additional performance boost, raising the validation Dice to 0.946 and IoU to 0.913, while maintaining a balanced sensitivity (0.973) and specificity (0.971). This confirms the effectiveness of attention-driven feature refinement in focusing the network’s representational capacity on salient lesion regions. The complete H-Fusion-SEG framework, which integrates both SAM and Hyper-Attention within the multi-scale fusion design, delivered the best overall performance, achieving the lowest validation loss (0.150), the highest validation Dice (0.958), and well-balanced sensitivity (0.954) and specificity (0.972).
These progressive enhancements validate the synergistic effect of SAM’s robust global context modeling and Hyper-Attention’s fine-grained feature alignment. The combination significantly improves the model’s ability to delineate lesions with irregular boundaries, heterogeneous textures, and low-contrast edges, which are commonly encountered in dermoscopic imagery. Furthermore, the results suggest that incorporating both global and local attention mechanisms facilitates superior spatial consistency and boundary adherence, thereby improving both region-based and pixel-level metrics.
The proposed H-Fusion-SEG model was comprehensively validated across multiple benchmark datasets to evaluate its generalization capability. The assessment employed a diverse set of evaluation metrics, including Dice coefficient, IoU, and PACC, alongside advanced boundary-aware measures such as Hausdorff Distance (HD) and Boundary F1-score (BF1). The quantitative results are presented in Table 4 and visually illustrated in Fig. 8.
Table 4.
Performance of the H-fusion-SEG model across different datasets.
| Dataset | PACC | Dice | IoU | HD (px) | BF1 |
|---|---|---|---|---|---|
| HAM10000 | 0.9699 | 0.9580 ± 0.072 | 0.9250 ± 0.105 | 25.37 ± 2.74 | 0.75 ± 0.05 |
| ISIC-2016 | 0.9548 | 0.9269 ± 0.099 | 0.8775 ± 0.125 | 26.92 ± 9.87 | 0.72 ± 0.06 |
| ISIC-2017 | 0.9200 | 0.8836 ± 0.102 | 0.8152 ± 0.137 | 66.55 ± 7.40 | 0.68 ± 0.07 |
| ISIC-2018 | 0.9815 | 0.9629 ± 0.142 | 0.9329 ± 0.172 | 24.12 ± 1.51 | 0.76 ± 0.05 |
Fig. 8.

Training and validation curves of Dice, IoU, and loss for the H-Fusion-SEG model, showing stable convergence and strong generalization.
As shown in Table 4, H-Fusion-SEG consistently achieves lower HD values and higher BF1 scores across all datasets compared to representative baseline models, namely U-Net, ResUNet++, and SkinSAM. For example, on the HAM10000 dataset, the proposed model attains HD = 25.37 ± 2.74 px and BF1 = 0.75 ± 0.05, significantly outperforming the baseline methods. A lower HD indicates a closer geometric correspondence between predicted and ground-truth lesion boundaries, while a higher BF1 reflects superior detection of fine-grained and irregular contour structures.
These performance gains are particularly pronounced in cases involving lesions with indistinct margins, irregular shapes, or heterogeneous textures. This confirms the effectiveness of the proposed hyper-attention fusion mechanism in improving boundary delineation and overall segmentation precision. Collectively, the results highlight the robustness of H-Fusion-SEG across diverse datasets and its potential suitability for deployment in clinical decision-support systems.
The training and validation curves in Fig. 8 provide clear evidence of the model’s stable learning behavior and robust generalization capabilities over the course of 50 epochs. Both training and validation losses exhibit a consistent downward trend, demonstrating that the proposed H-Fusion-SEG framework effectively learns discriminative features for lesion segmentation. While the validation loss shows minor fluctuations, likely attributable to inter-sample variability and the presence of challenging lesion cases, it closely follows the trajectory of the training loss, indicating the absence of severe overfitting.
In parallel, the performance metrics, including accuracy, Dice coefficient, and IoU, show steady and monotonic improvement for both the training and validation sets. The training Dice converges to approximately 0.98, while the validation Dice reaches around 0.96, with similar patterns observed for IoU and pixel accuracy. The narrow gap between training and validation curves across all metrics highlights the model’s ability to maintain high performance across unseen data without sacrificing generalization.
Furthermore, the smooth convergence of the curves underscores the stability of the optimization process, with no signs of divergence or performance degradation in later epochs. These observations collectively confirm that the proposed approach not only achieves high segmentation accuracy but also sustains consistent performance throughout training, effectively capturing lesion boundaries and structural details across varied dataset samples.
Table 5 presents the segmentation performance of the proposed H-Fusion-SEG model when subjected to challenging perturbations, specifically Gaussian noise injection and random rotation transformations, which are commonly encountered in real-world clinical imaging scenarios. These perturbations introduce variability in pixel intensities, geometric alignment, and lesion boundary sharpness, thereby testing the robustness and stability of the model. Despite these adverse conditions, the proposed framework consistently demonstrates high resilience and accuracy across all benchmark datasets. For example, on the HAM10000 dataset, the model achieves a Dice score of 0.909 ± 0.1934 and an IoU of 0.8701 ± 0.1910, while maintaining a high pixel accuracy (PACC = 0.9548). This indicates that the model can accurately preserve lesion structure and delineation even in the presence of significant visual noise and rotational distortions. Similarly, for the ISIC-2016 dataset, the model attains a Dice score of 0.8731 ± 0.1866 and an IoU of 0.8231 ± 0.1837, reflecting reliable boundary retention despite the altered image characteristics. Performance trends are consistent for the ISIC-2017 and ISIC-2018 datasets, with Dice scores of 0.8321 and 0.9241, respectively. The higher performance observed for ISIC-2018 can be attributed to its larger dataset size and greater intra-class variability, which may have enhanced the model’s ability to generalize under perturbations. The slightly lower scores for ISIC-2017 highlight the challenge posed by its irregular lesion shapes and reduced training data volume. Overall, these results confirm that the H-Fusion-SEG framework exhibits strong robustness, adaptability, and generalization capabilities under noisy and geometrically transformed conditions. Such resilience is crucial for practical deployment in dermatological imaging systems, where acquisition inconsistencies, hardware imperfections, and patient movement can often introduce unpredictable distortions.
Table 5.
Performance of H-fusion-SEG under Gaussian noise and random rotations, showing strong robustness across datasets.
| Dataset | PACC | Dice (↑) | IoU (↑) |
|---|---|---|---|
| HAM10000 | 0.9548 | 0.909 ± 0.1934 | 0.8701 ± 0.1910 |
| ISIC-2016 | 0.9248 | 0.8731 ± 0.1866 | 0.8231 ± 0.1837 |
| ISIC-2017 | 0.8800 | 0.8321 ± 0.1160 | 0.7789 ± 0.1370 |
| ISIC-2018 | 0.9815 | 0.9241 ± 0.1090 | 0.9001 ± 0.1930 |
The results in Table 6 illustrate that the proposed H-Fusion-SEG model delivers consistently superior performance on the HAM10000 dataset compared to recent state-of-the-art segmentation techniques. This superiority is evidenced by higher Dice coefficients and IoU scores, both of which signify more accurate lesion boundary delineation and improved spatial agreement with the ground truth masks. The integration of the Hyper_Attention mechanism with a high-capacity encoder–decoder and multi-branch fusion strategy enables the model to effectively capture both fine-grained local details and broad global contextual cues. This balanced feature representation is particularly advantageous in handling lesions with irregular shapes, fuzzy borders, or varying contrast levels. Furthermore, the proposed model achieves this high accuracy with fewer training epochs and reduced training time compared to some existing approaches, demonstrating both efficiency and robustness. Such performance indicates that H-Fusion-SEG is not only suitable for research benchmarks but is also well-positioned for real-world clinical deployment in dermatology, where precise and reliable segmentation is essential for diagnosis and treatment planning.
Table 6.
Comparison of proposed H-fusion-SEG model with state-of-arts models based on HAM10000.
| Model | PACC | IoU | Dice | Epochs | Training time |
|---|---|---|---|---|---|
| D_U-Net49 | 0.87 | N/A | 0.89 | N/A | N/A |
| SkinSAM50 | 0.84 | 0.66 | 0.79 | N/A | N/A |
| SegNet42 | 0.88 | 0.75 | 0.82 | N/A | N/A |
| DeepLabV342 | 0.90 | 0.79 | 0.86 | N/A | N/A |
| U-Net42 | 0.91 | 0.81 | 0.84 | N/A | N/A |
| Ensemble model42 | 0.95 | 0.90 | 0.93 | N/A | N/A |
| ResUNet++39 | 0.92 | 0.92 | 0.92 | 40 | N/A |
| MFSNet51 | N/A | 0.90 | 0.91 | N/A | 9 h |
| Proposed model | 0.97 | 0.93 | 0.96 | 45 | 3 h |
The results presented in Table 7 highlight the strong generalization capability of the proposed H-Fusion-SEG model when evaluated on the ISIC-2016 and ISIC-2018 skin lesion segmentation datasets. For ISIC-2016, the model achieved a segmentation accuracy (PACC) of 0.9548, a Dice coefficient of 0.9269, and an IoU of 0.8775, with a relatively low loss value of 0.2150. On the more diverse ISIC-2018 dataset, the performance further improved, attaining a PACC of 0.9815, a Dice of 0.9629, and an IoU of 0.9329, albeit with a slightly higher reported loss value due to dataset complexity. These consistent IoU and Dice scores across both datasets underscore the model’s robustness in accurately segmenting lesions with varying sizes, shapes, and boundary definitions.
Table 7.
Performance of the H-fusion-SEG model on ISIC-2016 and ISIC-2018 datasets.
| Dataset | PACC | IoU | Dice | Loss |
|---|---|---|---|---|
| ISIC-2016 | 0.9548 | 0.8775 | 0.9269 | 0.2150 |
| ISIC-2018 | 0.9815 | 0.9329 | 0.9629 | 0.3307 |
A comparative evaluation in Table 8 further investigates the performance of H-Fusion-SEG against several recent high-performing architectures on ISIC-2016. While some methods, such as GFANet and EIU-Net, report marginally higher Dice or IoU values, the proposed model achieves a balanced trade-off between segmentation accuracy, Dice, and IoU, outperforming most competitors in overall consistency. Notably, its IoU score of 0.8775 surpasses that of multiple advanced models, reflecting its precise boundary localization capability.
Table 8.
Comparison of the proposed H-fusion-SEG model with state-of-the-art methods on the ISIC-2016 dataset.
Similarly, Table 9 presents a comparison of the proposed approach with leading methods on ISIC-2018. Here, H-Fusion-SEG clearly outperforms all listed counterparts, achieving the highest values across all key metrics, a PACC of 0.9815, an IoU of 0.9329, and a Dice score of 0.9629. The margin of improvement in IoU (over 9 percentage points compared to the next best-performing model) further emphasizes the superiority of the proposed method in capturing fine lesion structures while preserving global shape fidelity.
Table 9.
Comparison of the proposed H-fusion-SEG model with state-of-the-art methods on the ISIC-2018 dataset.
Overall, these results confirm that H-Fusion-SEG maintains excellent cross-dataset adaptability, delivering top-tier performance on ISIC-2018 and competitive results on ISIC-2016. This combination of robustness, adaptability, and accuracy positions the model as a reliable segmentation framework for real-world dermatological applications, where lesion variability and dataset diversity are inevitable challenges.
The qualitative segmentation results presented in Figs. 9, 10, and 11 provide compelling visual evidence of the H-Fusion-SEG model’s ability to accurately delineate skin lesion boundaries across multiple datasets, including ISIC-2016, ISIC-2018, and HAM10000. Each figure displays representative examples, where the Input Image is shown alongside the Ground Truth Mask, the Predicted Binary Mask, and a Masked Image that overlays the segmentation result on the original image for better interpretability.
Fig. 9.

Representative segmentation results of the H-Fusion-SEG model on the ISIC-2016 dataset. Each row presents the input dermoscopic image, corresponding ground truth mask, predicted binary mask, and the masked image highlighting the segmented lesion region.
Fig. 10.

Representative segmentation results of the H-Fusion-SEG model on the ISIC-2018 dataset. Visual examples show accurate lesion boundary delineation across varying lesion sizes, shapes, and textures.
Fig. 11.

Representative segmentation results of the H-Fusion-SEG model on the HAM10000 dataset, illustrating its ability to generalize effectively across heterogeneous lesion appearances.
Across diverse lesion presentations, ranging from small, well-circumscribed lesions to larger, irregularly shaped melanomas, the predicted masks exhibit a high degree of spatial correspondence with the ground truth. The model consistently captures fine structural details of lesion boundaries with minimal leakage into surrounding healthy skin regions. In cases of small and sharply demarcated lesions, segmentation is virtually indistinguishable from the manual annotations. For more complex lesions with irregular edges, heterogeneous pigmentation, or diffuse borders, the predicted contours still achieve strong alignment with the ground truth, underscoring the robustness of the learned representations.
These visual outcomes further illustrate the model’s adaptability to variations in lesion morphology, texture complexity, and illumination conditions, factors that often challenge segmentation algorithms in real-world clinical settings. Notably, the integration of the Hyper_Attention mechanism within the multi-branch fusion strategy appears to enhance the model’s capacity to focus on discriminative lesion features while suppressing irrelevant background information. This not only results in visually coherent segmentation maps but also aligns with the strong quantitative results reported in earlier tables.
Moreover, Fig. 12 offers a comparative visual summary of the model’s outputs across all three datasets (HAM10000, ISIC-2016, ISIC-2018). The consistency in segmentation quality across datasets with differing image resolutions, acquisition conditions, and lesion diversity confirms the generalization capability of the proposed H-Fusion-SEG framework. Such reliability is crucial for deployment in automated dermatology workflows, where diverse image sources and patient demographics are expected.
Fig. 12.

Cross-dataset qualitative comparison of H-Fusion-SEG outputs for HAM10000, ISIC-2016, and ISIC-2018 datasets, demonstrating consistent segmentation performance under varying image resolutions and acquisition conditions.
Discussion
The experimental findings of this study provide compelling evidence for the effectiveness, robustness, and clinical relevance of the proposed H-Fusion-SEG framework for automated skin lesion segmentation. By combining a ResNet101 encoder with the SAM and augmenting them with specialized Hyper_Attention and multi-scale fusion modules, the architecture effectively captures both global contextual dependencies and fine-grained spatial details. This design enables the network to consistently achieve superior performance across diverse evaluation metrics, including PACC, Dice, and IoU, on benchmark datasets HAM10000, ISIC-2016, and ISIC-2018.
The results on the HAM10000 dataset are particularly noteworthy, indicating the model’s ability to precisely delineate complex lesion boundaries while preserving subtle morphological patterns. This outcome reflects the framework’s adaptability to heterogeneous lesion appearances, from small, well-circumscribed nevi to large, irregular melanomas with fuzzy edges. Moreover, consistent performance across datasets underscores its potential generalizability, a critical requirement for integration into real-world dermatological CAD systems.
When benchmarked against state-of-the-art segmentation approaches published between 2023 and 2025, the H-Fusion-SEG model demonstrates highly competitive, and often superior, results. While some competing architectures (e.g., GFANet, EIU-Net, DUASkinSeg) excel in specific metrics, H-Fusion-SEG achieves a balanced trade-off between region-level precision (IoU) and boundary-level accuracy (Dice). Such a balance is essential in clinical decision-making, where accurate lesion localization can influence diagnostic confidence, surgical margin determination, and treatment planning.
Despite these promising results, certain limitations merit attention. The performance on ISIC-2018, though strong, lags slightly behind HAM10000 and ISIC-2016, likely due to the dataset’s more challenging lesion presentations, including ambiguous boundaries, irregular pigmentation, and high intra-class variability. Addressing these challenges may require augmenting the framework with boundary refinement modules, multi-task learning strategies (e.g., simultaneous segmentation and classification), or uncertainty-aware post-processing techniques.
Our hybrid loss function, combining BCEWithLogitsLoss and IoU loss, effectively balances pixel-level and region-level accuracy. Nevertheless, exploring alternative loss formulations such as Focal Tversky Loss or Boundary-Aware Losses could improve segmentation in cases with low contrast, noisy textures, or highly irregular edges.
In addition to accuracy, cross-domain robustness and calibrated predictive confidence are critical for safe and reliable clinical translation. SAM’s inherent zero-shot and cross-domain generalization capabilities provide a strong foundation for domain adaptation strategies aimed at minimizing performance degradation in unseen clinical environments. Potential enhancements include unsupervised feature-level alignment (e.g., adversarial domain adaptation), adaptation of normalization statistics, style-transfer augmentation of source images, and lightweight test-time adaptation to dynamically adjust model parameters during deployment.
Complementary to domain adaptation, explicit uncertainty estimation can significantly enhance interpretability and safety. Techniques such as Monte Carlo Dropout, deep ensembles, or test-time augmentation can decompose epistemic (model) and aleatoric (data) uncertainties, allowing computation of predictive entropy or variance. These estimates can be used to:
Flag low-confidence cases for human expert review,
Drive uncertainty-aware post-processing to improve boundary delineation in ambiguous regions, and
Prioritize samples for annotation via active learning, thereby efficiently expanding and diversifying the training set.
Integrating domain-adaptation pipelines with uncertainty-aware decision rules would not only strengthen robustness and interpretability but also materially advance the readiness of H-Fusion-SEG for real-world clinical workflows. Future research should explore this integration alongside semi-supervised learning and federated learning paradigms, which could further mitigate the reliance on large, fully annotated datasets while preserving patient privacy.
In summary, H-Fusion-SEG delivers state-of-the-art competitive performance with strong generalization capabilities, supported by an architecture that is well-suited for domain adaptation and uncertainty-aware enhancements. With these targeted extensions, the framework holds substantial promise as a trustworthy, generalizable, and clinically deployable AI-assisted segmentation tool, contributing to earlier diagnosis, improved treatment planning, and better patient outcomes in dermatological practice.
Conclusion
This study presented H-Fusion-SEG, a novel dual-encoder framework for automated skin lesion segmentation that synergistically integrates a SAM-based feature extractor with a ResNet-101 U-Net backbone. By combining global-context representations learned by SAM with the fine-grained spatial features extracted by U-Net, the architecture effectively captures both long-range pixel dependencies and localized structural details. This hybrid design ensures robust delineation of lesions, even in cases where boundaries are irregular, textures are heterogeneous, or the contrast between lesion and surrounding skin is minimal. Extensive evaluations on three benchmark datasets, ISIC-2016, HAM10000, and ISIC-2018, demonstrated that H-Fusion-SEG consistently achieves superior Dice and IoU scores compared to established baselines such as U-Net and FAT-Net, with notable improvements in challenging clinical scenarios. Beyond precise segmentation, the proposed approach facilitates computational efficiency in downstream CAD pipelines by focusing inference exclusively on clinically relevant regions of interest, thereby reducing unnecessary computational overhead. The adaptive fusion module and carefully engineered skip connections enable seamless integration of complementary multi-scale feature hierarchies, resulting in a lightweight yet clinically versatile solution suitable for integration into real-world dermatological workflows.
Despite its strong performance, several limitations warrant consideration. First, the current evaluation is limited to dermoscopic images from publicly available datasets, which may not fully capture the variability present in real-world clinical environments, including variations in imaging devices, acquisition protocols, and patient demographics. Second, although SAM imparts notable cross-domain capabilities, the model has not yet been rigorously evaluated under domain shift conditions, such as when applied to images from different geographic regions or hospitals. Third, while the architecture is relatively lightweight, further optimization is required for real-time edge deployment on portable or resource-constrained devices. Finally, the current framework focuses solely on segmentation; it does not yet incorporate uncertainty estimation, multi-modal inputs, or longitudinal data analysis, all of which could further enhance interpretability and diagnostic value.
Building upon the current findings, future research will focus on four main directions:
Domain Adaptation and Generalization: Extending the framework to handle diverse imaging conditions and devices through unsupervised domain adaptation, test-time adaptation, and data harmonization techniques.
Multi-Modal Integration: Combining dermoscopic lesion images with additional clinical metadata (e.g., patient age, lesion history, histopathology) to enable a more comprehensive and context-aware diagnosis.
Uncertainty-Aware Segmentation: Incorporating predictive uncertainty estimation methods such as Monte Carlo Dropout or deep ensembles to improve safety, interpretability, and decision support in clinical workflows.
Edge Deployment Optimization: Streamlining the architecture for real-time inference on low-power embedded systems and point-of-care devices, enabling broader access to automated lesion assessment in remote or resource-limited settings.
By addressing these areas, H-Fusion-SEG has the potential to evolve into a highly generalizable, interpretable, and deployment-ready AI-assisted segmentation system, accelerating early skin cancer detection, improving treatment planning, and ultimately enhancing patient outcomes.
Acknowledgements
The authors gratefully acknowledge the support provided by Princess Nourah bint Abdulrahman University and Prince Sultan University in facilitating and funding this research. The authors would like to thank the Automated Systems and Computing Lab (ASCL) and Robotics and Internet-of-Things Lab at Prince Sultan University (PSU), and PSU in participating in paying the APC of this publication, Riyadh, Saudi Arabia, and for their support to this work.
Author Contribution
Walid El-Shafai conceived the study, supervised the research process, and contributed to the methodological framework. Anas M. Aliimplemented the proposed model, performed experiments, and contributed to data analysis. Nada Alzaben provided critical revisions,interpretation of results, and clinical validation perspectives. Ibrahim Abd El-Fattah assisted in algorithm optimization, performanceevaluation, and manuscript refinement. All authors contributed to drafting and revising the manuscript, approved the final version, andagreed to be accountable for the integrity and accuracy of the work.
Funding
Princess Nourah Bint Abdulrahman University Researchers Supporting Project, PNURSP2025R733.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
Declarations
Competing interests
The authors declare that they have no conflict of interest.
Footnotes
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Walid El‑Shafai, Email: welshafai@psu.edu.sa, Email: walid.elshafai@el-eng.menofia.edu.eg, Email: eng.waled.elshafai@gmail.com.
Nada Alzaben, Email: nialzaben@pnu.edu.sa.
References
- 1.Siegel, R. L., Miller, K. D. & Jemal, A. Cancer statistics, 2019. CA Cancer J. Clin.69(1), 7–34 (2019). [DOI] [PubMed] [Google Scholar]
- 2.El-Shafai, W., El-Fattah, I. A. & Taha, T. E. Deep learning-based hair removal for improved diagnostics of skin diseases. Multimed. Tools Appl.83(9), 27331–27355. 10.1007/s11042-023-16646-6 (2023). [Google Scholar]
- 3.Attia, M., Hossny, M., Nahavandi, S., & Yazdabadi, A. Skin melanoma segmentation using recurrent and convolutional neural networks. In 2017 IEEE 14th international symposium on biomedical imaging (ISBI 2017), IEEE, 292–296 (2017).
- 4.Garcia-Arroyo, J. L. & Garcia-Zapirain, B. Segmentation of skin lesions in dermoscopy images using fuzzy classification of pixels and histogram thresholding. Comput. Methods Programs Biomed.168, 11–19 (2019). [DOI] [PubMed] [Google Scholar]
- 5.Wang, H., Wang, G., Sheng, Z., & Zhang, S. Automated segmentation of skin lesion based on pyramid attention network. In Machine Learning in Medical Imaging: 10th International Workshop, MLMI 2019, Held in Conjunction with MICCAI 2019, Shenzhen, China, Proceedings 10, Springer, 435–443 (2019).
- 6.Beuren, A. T., Janasieivicz, R., Pinheiro, G., Grando, N., Facon, J. Skin melanoma segmentation by morphological approach. In Proceedings of the international conference on advances in computing, communications and informatics, 972–978 (2012).
- 7.Chatterjee, S., Dey, D. & Munshi, S. Integration of morphological preprocessing and fractal based feature extraction with recursive feature elimination for skin lesion types classification. Comput. Methods Programs Biomed.178, 201–218 (2019). [DOI] [PubMed] [Google Scholar]
- 8.Verma, K., Singh, B. K. & Thoke, A. S. An enhancement in adaptive median filter for edge preservation. Procedia Comput. Sci.48, 29–36 (2015). [Google Scholar]
- 9.Salido, J. A. A. & Ruiz, C. Using deep learning to detect melanoma in dermoscopy images. Int. J. Mach. Learn. Comput.8(1), 61–68 (2018). [Google Scholar]
- 10.He, K., Gkioxari, G., Dollár, P., Girshick, R. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision, 2961–2969 (2017).
- 11.Ronneberger, O., Fischer, P., & Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany. Proceedings, part III 18, Springer, 234–241 (2015).
- 12.Dosovitskiy, A. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020).
- 13.Tolstikhin, I. O. et al. Mlp-mixer: An all-mlp architecture for vision. Adv. Neural Inf. Process Syst.34, 24261–24272 (2021). [Google Scholar]
- 14.Tang Y. et al. Self-supervised pre-training of swin transformers for 3d medical image analysis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 20730–20740 (2022).
- 15.Cao H. et al. Swin-unet: Unet-like pure transformer for medical image segmentation. In European conference on computer vision, Springer, 205–218 (2022).
- 16.Isensee F. et al. nnu-net: Self-adapting framework for U-net-based medical image segmentation. arXiv preprint arXiv:1809.10486 (2018).
- 17.Wang, W., Zheng, V. W., Yu, H. & Miao, C. A survey of zero-shot learning: Settings, methods, and applications. ACM Trans. Intell. Syst. Technol. (TIST)10(2), 1–37 (2019). [Google Scholar]
- 18.Kirillov A. et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 4015–4026 (2023).
- 19.Mirikharaji, Z. et al. A survey on deep learning for skin lesion segmentation. Med. Image Anal.88, 102863 (2023). [DOI] [PubMed] [Google Scholar]
- 20.Xu, Y. et al. Advances in medical image segmentation: A comprehensive review of traditional, deep learning and hybrid approaches. Bioengineering11(10), 1034 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Abd El-Fattah, I., Ali, A. M., El-Shafai, W., Taha, T. E. & Abd El-Samie, F. E. Deep-learning-based super-resolution and classification framework for skin disease detection applications. Opt. Quantum Electron.55(5), 427. 10.1007/s11082-022-04432-x (2023). [Google Scholar]
- 22.Aneesh, R. P. & Zacharias, J. Semantic segmentation in skin surface microscopic images with artifacts removal. Comput. Biol. Med.180, 108975 (2024). [DOI] [PubMed] [Google Scholar]
- 23.Xu, G., Wang, X., Wu, X., Leng, X., & Xu, Y. Development of Skip Connection in Deep Neural Networks for Computer Vision and Medical Image Analysis: A Survey. arXiv preprint arXiv:2405.01725 (2024).
- 24.Ma, Z. & Tavares, J. M. R. S. A novel approach to segment skin lesions in dermoscopic images based on a deformable model. IEEE J. Biomed. Health Inform.20(2), 615–623 (2015). [DOI] [PubMed] [Google Scholar]
- 25.Vasconcelos, F. F. X., Medeiros, A. G., Peixoto, S. A. & Reboucas Filho, P. P. Automatic skin lesions segmentation based on a new morphological approach via geodesic active contour. Cogn. Syst. Res.55, 44–59 (2019). [Google Scholar]
- 26.Basak, H., Kundu, R. Comparative study of maturation profiles of neural cells in different species with the help of computer vision and deep learning. In International Symposium on Signal Processing and Intelligent Recognition Systems, Springer, 352–366 (2020).
- 27.Wei, Z., Song, H., Chen, L., Li, Q. & Han, G. Attention-based DenseUnet network with adversarial training for skin lesion segmentation. IEEE Access7, 136616–136629 (2019). [Google Scholar]
- 28.Zhou, Z., Rahman Siddiquee, M. M., Tajbakhsh, N., & Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation, 3–11 (2018). 10.1007/978-3-030-00889-5_1. [DOI] [PMC free article] [PubMed]
- 29.Saeed, A., Shehzad, K., Ahmed, S., & Azar, A. T. (2025). EG-VAN: A Global and Local Attention-Based Dual-Branch Ensemble Network With Advanced Color Balancing for Multi-Class Skin Cancer Recognition, IEEE Access15, 33251–33261 (2025). [Google Scholar]
- 30.Badrinarayanan, V., Kendall, A. & Cipolla, R. Segnet: A deep convolutional encoder–decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell.39(12), 2481–2495 (2017). [DOI] [PubMed] [Google Scholar]
- 31.Yuan, Y., Chao, M. & Lo, Y.-C. Automatic skin lesion segmentation using deep fully convolutional networks with jaccard distance. IEEE Trans. Med. Imaging36(9), 1876–1886 (2017). [DOI] [PubMed] [Google Scholar]
- 32.Abraham, N., & Khan, N. M. A novel focal tversky loss function with improved attention u-net for lesion segmentation. In: 2019 IEEE 16th international symposium on biomedical imaging (ISBI 2019), IEEE, 683–687 (2019).
- 33.Jha, D., Riegler, M. A., Johansen, D., Halvorsen, P., & Johansen, H. D. Doubleu-net: A deep convolutional neural network for medical image segmentation. In 2020 IEEE 33rd International symposium on computer-based medical systems (CBMS), IEEE, 558–564 (2020).
- 34.Aljanabi, M., Özok, Y. E., Rahebi, J. & Abdullah, A. S. Skin lesion segmentation method for dermoscopy images using artificial bee colony algorithm. Symmetry (Basel)10(8), 347 (2018). [Google Scholar]
- 35.Chattopadhyay, S., & Basak, H. Multi-scale attention U-net (msaunet): A modified U-net architecture for scene segmentation. arXiv preprint arXiv:2009.06911, (2020).
- 36.Fu J. et al. Dual attention network for scene segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 3146–3154 (2019).
- 37.Barata, C., Celebi, M. E. & Marques, J. S. Explainable skin lesion diagnosis using taxonomies. Pattern Recognit110, 107413 (2021). [Google Scholar]
- 38.Lei, B. et al. Skin lesion segmentation via generative adversarial networks with dual discriminators. Med Image Anal64, 101716 (2020). [DOI] [PubMed] [Google Scholar]
- 39.Mustafa, S., Jaffar, A., Rashid, M., Akram, S. & Bhatti, S. M. Deep learning-based skin lesion analysis using hybrid ResUNet++ and modified AlexNet-random forest for enhanced segmentation and classification. PLoS ONE20(1), e0315120 (2025). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Himel, G. M. S., Islam, M. M., Al-Aff, K. A., Karim, S. I. & Sikder, M. K. U. Skin cancer segmentation and classification using vision transformer for automatic analysis in dermatoscopy-based noninvasive digital system. Int J Biomed Imaging2024(1), 3022192 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Dzieniszewska, A., Garbat, P. & Piramidowicz, R. Improving skin lesion segmentation with self-training. Cancers (Basel)16(6), 1120 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Thwin, S. M. & Park, H.-S. Enhanced skin lesion segmentation and classification through ensemble models. Eng5(4), 2805–2820 (2024). [Google Scholar]
- 43.Tschandl, P., Rosendahl, C. & Kittler, H. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Sci. Data5(1), 1–9 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Gutman D. et al. Skin lesion analysis toward melanoma detection: A challenge at the international symposium on biomedical imaging (ISBI) 2016, hosted by the international skin imaging collaboration (ISIC). arXiv preprint arXiv:1605.01397 (2016).
- 45.Codella N. et al. Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (isic). arXiv preprint arXiv:1902.03368 (2019).
- 46.He, K., Zhang, X., Ren, S., & Sun, J. Deep residual learning for image recognition, In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778 (2016).
- 47.Long, J., Shelhamer, E., & Darrell, T. Fully convolutional networks for semantic segmentation, In Proceedings of the IEEE conference on computer vision and pattern recognition, 3431–3440 (2015). [DOI] [PubMed]
- 48.Vaswani, A. et al. Attention is all you need. Adv. Neural Inf. Process Syst.30, 1 (2017). [Google Scholar]
- 49.Abid, I. et al. A convolutional neural network for skin lesion segmentation using double u-net architecture. Intell. Autom. Soft Comput.33(3), 1407–1421 (2022). [Google Scholar]
- 50.Hu, M., Li, Y., & Yang, X. Skinsam: Empowering skin cancer segmentation with segment anything model. arXiv preprint arXiv:2304.13973 (2023).
- 51.Basak, H., Kundu, R. & Sarkar, R. MFSNet: A multi focus segmentation network for skin lesion segmentation. Pattern Recognit.128, 108673 (2022). [Google Scholar]
- 52.Alzakari, S. A. et al. LesionNet: An automated approach for skin lesion classification using SIFT features with customized convolutional neural network. Front Med. (Lausanne)11, 1487270 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Li, Y., Tian, T., Hu, J. & Yuan, C. SUTrans-NET: A hybrid transformer approach to skin lesion segmentation. PeerJ Comput. Sci.10, e1935. 10.7717/peerj-cs.1935 (2024). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Ahmed, A., Sun, G., Bilal, A., Li, Y. & Ebad, S. A. Precision and efficiency in skin cancer segmentation through a dual encoder deep learning model. Sci. Rep.15(1), 4815. 10.1038/s41598-025-88753-3 (2025). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Qiu, S. et al. GFANet: Gated fusion attention network for skin lesion segmentation. Comput. Biol. Med.155, 106462. 10.1016/j.compbiomed.2022.106462 (2023). [DOI] [PubMed] [Google Scholar]
- 56.Yu, Z., Yu, L., Zheng, W. & Wang, S. EIU-Net: Enhanced feature extraction and improved skip connections in U-Net for skin lesion segmentation. Comput. Biol. Med.162, 107081 (2023). [DOI] [PubMed] [Google Scholar]
- 57.Dong, Y., Wang, L. & Li, Y. TC-Net: Dual coding network of transformer and CNN for skin lesion segmentation. PLoS ONE17(11), e0277578. 10.1371/journal.pone.0277578 (2022). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Siddiqui, A. M., Abbas, H., Asim, M., Ateya, A. A., & Abdallah, H. A. (2025). SGO-DRE: A Squid Game Optimization-Based Ensemble Method for Accurate and Interpretable Skin Disease Diagnosis. Computer Modeling in Engineering & Sciences, Volume and issue not specified, Article ID 069926. 10.32604/cmes.2025.069926 [Google Scholar]
- 59.Benjdira, B., Ali, A. M., & Koubaa, A. Streamlined global and local features combinator (SGLC) for high resolution image dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 1855–1864 (2023).
- 60.El-Shafai, W., Mohamed, E. M., Zeghid, M., Ali, A. M., & Aly, M. H. Hybrid single image super-resolution algorithm for medical images. Comput. Mater. Continua. 72 (3) (2022).
- 61.Umirzakova, S., Muksimova, S., Baltayev, J. & Cho, Y. I. Force map-enhanced segmentation of a lightweight model for the early detection of cervical cancer. Diagnostics15(5), 513 (2025). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Zhou, Y., Li, L., Lu, L., & Xu, M. nnWNet: Rethinking the use of transformers in biomedical image segmentation and calling for a unified evaluation benchmark. In Proceedings of the Computer Vision and Pattern Recognition Conference, 20852–20862 (2025).
- 63.Jin, Q., Cui, H., Wang, J., Sun, C., He, Y., Xuan, P., & Su, R. Iterative pseudo-labeling based adaptive copy-paste supervision for semi-supervised tumor segmentation. Knowl. Based Syst. 113785 (2025).
- 64.Lei, M., Wu, H., Lv, X. & Wang, X. Condseg: A general medical image segmentation framework via contrast-driven feature enhancement. Proceed. AAAI Conf. Artif. Intell.39(5), 4571–4579 (2025). [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.