

Abstract
Evolution produces complex and structured networks of interacting components in chemical, biological, and social systems. We describe a simple mathematical model for the evolution of an idealized chemical system to study how a network of cooperative molecular species arises and evolves to become more complex and structured. The network is modeled by a directed weighted graph whose positive and negative links represent “catalytic” and “inhibitory” interactions among the molecular species, and which evolves as the least populated species (typically those that go extinct) are replaced by new ones. A small autocatalytic set, appearing by chance, provides the seed for the spontaneous growth of connectivity and cooperation in the graph. A highly structured chemical organization arises inevitably as the autocatalytic set enlarges and percolates through the network in a short analytically determined timescale. This self organization does not require the presence of self-replicating species. The network also exhibits catastrophes over long timescales triggered by the chance elimination of “keystone” species, followed by recoveries.
Structured networks of interacting components are a hallmark of several complex systems, for example, the chemical network of molecular species in cells (1), the web of interdependent biological species in ecosystems (2, 3), and social and economic networks of interacting agents in societies (4–7). The structure of these networks is a product of evolution, shaped partly by the environment and physical constraints and partly by the population (or other) dynamics in the system. For example, imagine a pond on the prebiotic earth containing a set of interacting molecular species with some concentrations. The interactions among the species in the pond affect how the populations evolve with time. If a population goes to zero, or if new molecular species enter the pond from the environment (through storms, floods, or tides), the effective chemical network existing in the pond changes. We discuss a mathematical model that attempts to incorporate this interplay between a network, populations, and the environment in a simple and idealized fashion. The model [including an earlier version (8, 9)] was inspired by the ideas and results in refs. 10–18. Related but different models are studied in refs. 19–21.
The Model
The system consists of s species labeled by the index i = 1,2,… ,s. The network of interactions between species is specified by the s × s real matrix C ≡ {cij}. The network can be visualized as a directed graph whose nodes represent the species. A nonzero cij is represented by a directed weighted link from node j to node i. If cij > 0, then the corresponding link is a cooperative link: species j catalyzes the production of species i. If cij < 0, it is a destructive link: the presence of j causes a depletion of i (22).
Population Dynamics.
The model contains another dynamical variable x ≡ (x1,… . xs), where xi stands for the relative population of the ith species (0 ≤ xi ≤ 1, ∑i=1s xi = 1)). The time evolution of x depends on the interaction coefficients C, as is usual in population models. The specific evolution rule we consider is
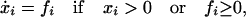 |
1 |
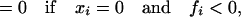 |
where
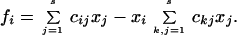 |
This is a particularly simple idealization of catalyzed chemical
reaction dynamics in a well stirred reactor (representing, say, a
prebiotic pond). It is motivated from the following considerations: If
species j catalyzes the ligation of reactants A
and B to form the species i, 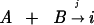 , then the rate of growth of the
population yi of species i in a
well stirred reactor will be given by
ẏi = k(1 +
νyj)nAnB −
φyi, where
nA,nB are
reactant concentrations, k is the rate constant for the
spontaneous reaction, ν is the catalytic efficiency, and φ
represents a common death rate or dilution flux in the reactor (23).
Assuming the catalyzed reaction is much faster than the spontaneous
reaction, and the concentrations of the reactants are large and fixed,
the rate equation becomes ẏi =
cyj − φyi, where c is a
constant. If species i has multiple catalysts, we get
ẏi = ∑js cijyj − φyi. The first of
Eqs. 1 follows from this on using the definition
xi = yi/∑j=1s yj. Note that the second (quadratic) term in
fi follows automatically from the
ẏi equation and the nonlinear
relationship between xi and
yi. Physically, it is needed to preserve
the normalization of the xi under time
evolution. When negative links are permitted, the second of Eqs.
1 is needed in general to prevent relative populations from
going negative. (With negative links, a more realistic chemical
interpretation would be obtained if
ẋi were proportional to
xi, but for simplicity we retain the form
of Eq. 1 in this paper.) Eq. 1 may be viewed as
defining an artificial chemistry in the spirit of refs. 13–17.
, then the rate of growth of the
population yi of species i in a
well stirred reactor will be given by
ẏi = k(1 +
νyj)nAnB −
φyi, where
nA,nB are
reactant concentrations, k is the rate constant for the
spontaneous reaction, ν is the catalytic efficiency, and φ
represents a common death rate or dilution flux in the reactor (23).
Assuming the catalyzed reaction is much faster than the spontaneous
reaction, and the concentrations of the reactants are large and fixed,
the rate equation becomes ẏi =
cyj − φyi, where c is a
constant. If species i has multiple catalysts, we get
ẏi = ∑js cijyj − φyi. The first of
Eqs. 1 follows from this on using the definition
xi = yi/∑j=1s yj. Note that the second (quadratic) term in
fi follows automatically from the
ẏi equation and the nonlinear
relationship between xi and
yi. Physically, it is needed to preserve
the normalization of the xi under time
evolution. When negative links are permitted, the second of Eqs.
1 is needed in general to prevent relative populations from
going negative. (With negative links, a more realistic chemical
interpretation would be obtained if
ẋi were proportional to
xi, but for simplicity we retain the form
of Eq. 1 in this paper.) Eq. 1 may be viewed as
defining an artificial chemistry in the spirit of refs. 13–17.
Graph Dynamics.
The dynamics of C in turn depends on x, as follows: Start with a random graph of s nodes: cij is nonzero with probability p and zero with probability 1 − p. If nonzero, cij is chosen randomly in the interval [−1, 1] for i ≠ j and [−1, 0] for i = j. Thus a link between two distinct species, if it exists, is just as likely to be cooperative as destructive, and a link from a species to itself can only be inhibitive, i.e., autocatalytic or self-replicating individual species are not allowed. The variable x is initialized by choosing each xi randomly between 0 and 1 and then rescaling all xi uniformly such that ∑i=1s xi = 1. The evolution of the network proceeds in three steps:
(i) Keeping the network fixed, the populations are evolved according to Eq. 1 for a time T, which is large enough for x to get reasonably close to its attractor. We denote Xi ≡ xi(T).
(ii) The set of nodes i with the least value of Xi is determined. We call this the set of “least fit” nodes, identifying the relative population of a species in the attractor (or, more specifically, at T) with its “fitness” in the environment defined by the graph. One of the least fit nodes is chosen randomly (say i0) and removed from the system along with all its links, leaving a graph of s − 1 species.
(iii) A new node is added to the graph so that it again has
s nodes. The links of the added node
(cii0 and
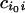 , for
i = 1, … , s) are assigned randomly
according to the same rule as for the nodes in the initial graph. The
new species is given a small relative population
, for
i = 1, … , s) are assigned randomly
according to the same rule as for the nodes in the initial graph. The
new species is given a small relative population
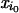 =
x0, and the other populations are
rescaled to keep ∑i=1s xi = 1.
This process, from step i onwards, is iterated many times.
=
x0, and the other populations are
rescaled to keep ∑i=1s xi = 1.
This process, from step i onwards, is iterated many times.
The rules for the evolution of the network C are intended to capture two key features of natural evolution, namely selection and novelty. The species that has the least population in the attractor configuration is the one most likely to be eliminated in a large fluctuation in a possible hostile environment. Often, the least value of Xi is zero. Thus the model implements selection by eliminating from the network a species that has become extinct or has the least chance of survival (18). [Relaxing in various ways the assumption (18) that only the least populated species is removed does not change the qualitative picture presented here; details on the robustness of the model to various deformations will be presented elsewhere.] Novelty is introduced in the network in the form of a new species. This species has on average the same connectivity as the initial set of species, but its actual connections with the existing set are drawn randomly. E.g., if a storm brings into a prebiotic pond a new molecular species from the environment, the new species might be statistically similar to the one being eliminated, but its actual catalytic and inhibitory interactions with the surviving species can be quite different. Another common feature of natural evolution is that populations typically evolve on a fast timescale compared with the network. This is captured in the model by having the xi relax to their attractor before the network is updated. The idealization of a fixed total number of species s is one that we hope to relax in future work.
The model described above differs from the one studied in refs. 8 and 9 in that it allows negative links and varying link strengths, and that the population dynamics, given by Eq. 1 is no longer linear. The earlier model had only fixed point attractors; here limit cycles are also observed. Because C now has negative entries, the formalism of nonnegative matrices no longer applies.
Results
Emergence of Cooperation and Interdependence.
Fig. 1 shows a sample run. The same qualitative behavior is seen in each of several hundred runs performed for p values ranging from 0.00002 to 0.01 and for s = 100, 150, 200. That the ratio of number of cooperative to destructive links at first remains constant at unity (statistically) and then increases by more than an order of magnitude is evidence of the emergence of cooperation. Fig. 1 also shows how a measure of the mutual interdependence of the species changes with time. This measure, “interdependency,” denoted d̄, is defined as d̄ ≡ (1/s)∑i=1s di, where di is the “dependency” of the ith node. di ≡ ∑kj|ckj|hki, where hki is 1 if there exists a directed path from k to i and 0 otherwise. di is the sum of (the absolute value of) the strengths of all links that eventually feed into i along some directed path. di describes not just the character of the “neighborhood” of the ith species but also the long-range connections that affect its dynamics. The increase in d̄ by an order of magnitude is a quantitative measure of the increase of interdependence of species in the network. The increase in the total density of links (l+ + l−)/s is another aspect of the increase of complexity of the system. Note that in the model selection rewards only “performance” as measured in terms of relative population; the rules do not select for higher cooperativity per se. Because a new species is equally likely to have positive or negative links with other species, the introduction of novelty is also not biased in favor of cooperativity. That this behavior is not a consequence of any intrinsic bias in the model that favors the increase of cooperation and interdependence is evidenced by the flat initial region of all of the curves.
Figure 1.

A run with parameter values s = 100, p = 0.005, and x0 = 10−4. (a) Number of populated species, s1, in the attractor of Eq. 1 (i.e., number of nodes with Xi > 0) after the nth addition of a new species (i.e., after n graph update time steps). (b) The number, l+, of positive links (cij > 0) in the graph (blue); the number, l−, of negative links (green); and “interdependency,” d̄, of the species in the network (red). The curves have three distinct regions. Initially s1 is small; most of the species have zero relative populations. l+ and l− also do not vary much from their initial (random graph) value (≈ps2/2 = 25) and remain approximately equal. d̄ hovers about its initial low value. In the second region s1, l+ and d̄ show a sharp increase, and l− decreases. In the third region s1, l+ and d̄ level off (but with fluctuations), and almost all species have nonzero populations in contrast to the initial period.
Autocatalytic Sets.
The explanation for the above behavior lies in the formation and growth of certain structures, autocatalytic sets (ACSs), in the graph. An ACS is defined as a set of nodes such that each node has at least one incoming positive link from a node in the set. Thus an ACS has the property of catalytic closure, i.e., it contains a catalyst for each of its members (24–26). The simplest example of an ACS is a cycle of positive links. Every ACS is not such a cycle but it can be shown that an ACS must contain a cycle of positive links (9). In Fig. 1, there is no ACS in the graph until n = 1,903. A small ACS (which happens to be a cycle of positive links between two nodes) appears at n ≡ n1 = 1,904, exactly where the behavior of the s1 curve changes. As time proceeds, this ACS becomes more complex and enlarges until at n ≡ n2 = 3,643, the entire graph becomes an ACS. l+ and d̄ exhibit an increase and l− a decrease as the ACS comes to occupy a significant part of the graph. After the ACS first appears (at n = n1), the set of populated nodes in the attractor configuration (s1 in number) is always an ACS (except for certain catastrophic events to be discussed later), which we call the “dominant ACS.” The spontaneous appearance of a small ACS at some n = n1, its persistence (except for catastrophes), and its growth until it spans the graph at n = n2, are seen in each of the several hundred runs mentioned earlier. The growth of the ACS across the graph between n1 and n2 occurs exponentially (with stochastic fluctuations),
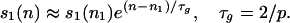 |
2 |
This expression (derived below) agrees with simulations as shown in Fig. 2. The average timescale τa ≡ 〈n1〉 for the first appearance of the ACS is given, for sufficiently small p, by τa ≈ 4/(p2s) (=1,600 for p = 0.005 and s = 100). This follows from the fact that the probability that a graph not containing an ACS will acquire a 2 cycle of positive links at the next update is p2s/4, with larger cycles being much less likely to appear when ps ≪ 1.
Figure 2.

Power law dependence of τg on p. Each data point shows the average of τg over 5 different runs with s = 100 and the given p value. The error bars correspond to one standard deviation. The best fit line has slope −1.02 ± 0.03 and intercept −0.08 ± 0.26, which is consistent with the expected slope −1 and intercept 0.
Up to n = n1, the graph has no ACS. It has chains and trees of positive and negative links and possibly loops containing negative links. These latter structures are not robust. For example, consider a chain of two positive links 1→2→3. Because catalytic links are pointing to node 3, it will do well populationally compared with nodes 1 and 2. However, because 1 has no incoming catalytic links, its relative population will decline to zero under Eq. 1, and it can be picked for replacement in the next graph update. This can disrupt the chain and hence erode the “well being” of node 3 until eventually, after some graph updates, the latter can also join the ranks of the least fit. Species 3 gets eliminated eventually because it does not feed back into and “protect” species 1 and 2, on whom its “well being” depends. In a graph without an ACS, no structure is protected from disruption. Because every node is liable to be replaced sooner or later, the graph remains as random as the initial graph (we have checked that the probability distribution of the number of incoming and outgoing links at a node remains the appropriate binomial for n < n1). This explains why s1, l±, and d̄ hover around their initial values.
The picture changes the moment a small ACS appears in the graph. The key point is that by virtue of catalytic closure, members of the ACS do well collectively in the population dynamics governed by Eq. 1. An ACS is a collective self replicator and beats chains, trees, and other non-ACS structures in the population game, reducing their Xi to zero when it appears. Thus, because graph update proceeds by replacing one of the nodes with Xi= 0 (if present) with a new one, such a replacement being outside the dominant ACS can cause no damage to the links that constitute the ACS. That is why the ACS structure, once it appears, is much more robust than the non-ACS structures discussed earlier. If the new node happens to get an incoming positive link from the dominant ACS, it becomes part of it. Thus the dominant ACS tends to expand in the graph as new nodes get attached to it (8, 9, 15), and s1 increases. In Δn graph updates, the average increase in s1, which is the number of added nodes that will get a positive link from one of the s1 nodes of the dominant ACS, is Δs1 ≈ (p/2)s1Δn, for small p. This proves Eq. 2. (Note that the exponential growth described by Eq. 2 is not to be confused with the exponential growth of populations yi of species that are part of the ACS. Eq. 2 reflects the growth of the ACS across the graph or the increase in the number of species that constitute the ACS.)
Because the dominant ACS grows by adding positive links from the existing dominant ACS, the number of positive links increases as the ACS grows. On the other hand, nodes receiving negative links usually end up being least fit, hence negative links get removed when these nodes are eliminated. Which novelty is captured thus depends on the existing “context”; the network evolves by preferentially capturing links and nodes that “latch on” cooperatively to the existing ACS and by disregarding those that do not. The “context” itself arises when the ACS structure first appears; this event transforms the nature of network evolution from random to “purposeful” (in this case directed toward increasing cooperation). Before the ACS appears, nothing interesting happens even though selection is operative (the least populated species are being eliminated). It is only after the ACS topological structure appears that selection for cooperation and complexity begins. Initially the ACS is small, and its impact on links and interdependency is not visible. As it grows and comes to occupy a significant part of the graph, the latter quantities depart significantly from their initial random graph values.
Inevitability of Autocatalytic Sets.
Note that the appearance of an ACS, although a chance event, is
inevitable. For sp ≪ 1, the probability that a graph not
containing a 2 cycle will acquire one at the next time step is
p2s/4 ≡
q. Because the probability of occurrence of 3 cycles, etc.,
is much smaller, the probability distribution of arrival times
n1 is approximated by
P(n1) = 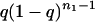 ,
whose mean τa is 1/q.
Because this probability declines exponentially after a timescale
1/q, the appearance of an ACS is inevitable, even for
arbitrarily small (but finite) p.
,
whose mean τa is 1/q.
Because this probability declines exponentially after a timescale
1/q, the appearance of an ACS is inevitable, even for
arbitrarily small (but finite) p.
Occasionally in a graph update, s1 can decrease for various reasons. If the new node forms an ACS of its own with nodes outside the dominant ACS, and the new ACS has a higher population growth rate (as determined by Eq. 1) than the old ACS, it drives the species of the latter to extinction and becomes the new dominant ACS. Alternatively, the new node could be a “destructive parasite:” it receives one or more positive links from and gives one or more negative links to the dominant ACS. Then part or whole of the ACS may join the set of least-fit nodes. Structures that diminish the size of the dominant ACS or destroy it appear rarely. For example, in Fig. 1, destructive parasites appeared 6 times at n = 3,388, 3,478, 3,576, 3,579, 3,592, and 3,613. In each case, s1 decreased by 1.
Emergence of Structure.
At n = n2, the whole graph becomes an ACS; the entire system can collectively self replicate despite the explicit absence of individual self replicators. Such a fully autocatalytic set is a very nonrandom structure. Consider a graph of s nodes and let the probability of a positive link existing between any pair of nodes be p*. Such a graph has on average m* = p*(s − 1) incoming or outgoing positive links per node. For the entire graph to be an ACS, each node must have at least one incoming positive link, i.e., each row of the matrix C must contain at least one positive element. Hence the probability, P, for the entire random graph to be an ACS is
P = probability that every row has at least one positive entry = [probability that a row has at least one positive entry]s = [1 − (probability that every entry of a row is ≤ 0)]s = [1 − (1 − p*)s−1]s = [1 − (1 − m*/(s − 1))s−1]s.
For large s and m* ∼ O(1),
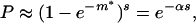 |
3 |
where α is positive and O(1). At n = n2, we find in all our runs that l+(n2) ≡ l* is greater than s but of order s, i.e., m* ≈ O(1). Thus dynamical evolution in the model via the ACS mechanism converts a random organization into a highly structured one that is exponentially unlikely to appear by chance. In the displayed run at n = n2, the graph had 117 positive links. The probability that a random graph with s = 100 nodes and m* = 1.17 would be an ACS is given by Eq. 3 to be ≈10−16.
Such a structure would take an exponentially long time to arise by pure chance. The reason it arises inevitably in a short timescale in the present model is the following: a small ACS can appear by chance quite readily and, once appeared, it grows exponentially fast across the graph by the mechanism outlined earlier. The dynamical appearance of such a structure may be regarded as the emergence of “organizational order.” The appearance of “exponentially unlikely” structures in the prebiotic context has been a puzzle. That in the present model such structures inevitably form in a short time may be relevant for the origin of life problem.
The Self-Organization Timescale in a Prebiotic Scenario.
We now speculate on a possible application to prebiotic chemical evolution. Imagine the molecular species to be small peptide chains with weak catalytic activity in a prebiotic pond alluded to earlier. The pond periodically receives an influx of new molecular species being randomly generated elsewhere in the environment through tides, storms, or floods. Between these influxes of novelty, the pond behaves as a well stirred reactor where the populations of existent molecular species evolve according to (a realistic version of) Eq. 1 and reach their attractor configuration. Under the assumption that the present model captures what happens in such a pond, the growth timescale (Eq. 2) for a highly structured almost fully autocatalytic chemical organization in the pond is τg = 2/p in units of the graph update time step. In this scenario, the latter time unit corresponds to the periodicity of the influx of new molecular species, hence it ranges from 1 day (for tides) to 1 year (for floods). Further, in the present model p/2 is the probability that a random small peptide will catalyze the production of another (26), and this has been estimated in ref. 12 as being in the range 10−5–10−10. With p/2 ≈ 10−8, for example, the timescale for a highly structured chemical organization to grow in the pond would be estimated to be of the order of 106–108 years. It is believed that life originated on Earth in a few hundred million years after the oceans condensed. These considerations suggest that it might be worthwhile to empirically pin down the “catalytic probability” p (introduced in ref. 26) for peptides, catalytic RNA, lipids, etc., on the one hand, and explore chemically more realistic models on the other.
Catastrophes and Recoveries in Network Dynamics.
After n = n2, the character of the network evolution changes again. For the first time, the least-fit node will be one of the ACS members. Most of the time elimination of the node does not affect the ACS significantly, and s1 fluctuates between s and s − 1. Sometimes the least-fit node could be a “keystone” species, which plays an important organizational role in the network despite its low population. When such a node is eliminated, many other nodes can get disconnected from the ACS, resulting in large dips in s1 and d̄ and subsequently large fluctuations in l+ and l−. These large “extinction events” can be seen in Fig. 3. Occasionally, the ACS can even be destroyed completely. The system recovers on the timescale τg after large extinctions if the ACS is not completely destroyed; if it is, and the next few updates obliterate the memory of previous structures in the graph, then again a time on average τa elapses before an ACS arises, and the self-organization process begins anew. It may be of interest (especially in ecology, economics, and finance) that network dynamics based on a fitness selection and the “incremental” introduction of novelty, as discussed here, can by itself cause catastrophic events without the presence of large external perturbations.
Figure 3.

The run of Fig. 1a displayed over a much longer timescale.
Discussion
We have described an evolutionary model in which the dynamics of species' populations (fast variables) and the graph of interactions among them (slow variables) are mutually coupled. The network dynamics displays self organization seeded by the chance but inevitable appearance of a small cooperative structure, namely an ACS. In a dynamics that penalizes species for low population performance, the collective cooperativity of the ACS members makes the set relatively robust against disruption. New species that happen to latch on cooperatively to this structure preferentially survive, further enlarging the ACS in the process. Eventually the graph acquires a highly nonrandom structure. We have discussed the time evolution of quantitative measures of cooperation, interdependence, and structure of the network, which capture various aspects of the complexity of the system.
It is noteworthy that collectively replicating ACSs arise even though individual species are not self replicating. Thus the present mechanism is different from the hypercycle (27), where a template is needed to produce copies of existing species. Unlike the hypercycle, the ACS is not disrupted by parasites and short circuits and grows in complexity, as evidenced in all our runs. It can be disrupted, however, when it loses a “keystone” species.
It is also worth mentioning one departure from ref. 12, in that we find that a fully autocatalytic system (or percolating ACS) is not needed a priori for self organization. In the present model, a small ACS, once formed, typically expands (see also ref. 15) and eventually percolates the whole network dynamically. This dynamical process might be relevant for economic takeoff and technological growth in societies.
Acknowledgments
We thank J. D. Farmer, W. C. Saslaw, and anonymous referees for helpful comments on the manuscript. S.J. acknowledges the Associateship of the Abdus Salam International Centre for Theoretical Physics.
Abbreviation
- ACS
autocatalytic set
Footnotes
Article published online before print: Proc. Natl. Acad. Sci. USA, 10.1073/pnas.021545098.
Article and publication date are at www.pnas.org/cgi/doi/10.1073/pnas.021545098
References
- 1.Lodish H, Baltimore D, Berk A, Zipursky S L, Matsudaira P, Darnell J E. Molecular Cell Biology. New York: Scientific American Books; 1995. [Google Scholar]
- 2.Cohen J E, Briand F, Newman C M. Community Food Webs: Data and Theory. New York: Springer; 1990. [Google Scholar]
- 3.Pimm S L. The Balance of Nature? Ecological Issues in the Conservation of Species and Communities. Chicago: Univ. of Chicago Press; 1991. [Google Scholar]
- 4.Wellman B, Berkovitz S D, editors. Social Structures: A Network Approach. Cambridge, U.K.: Cambridge Univ. Press; 1988. [Google Scholar]
- 5.Axelrod R. The Complexity of Cooperation. Princeton: Princeton Univ. Press; 1997. [Google Scholar]
- 6.Watts D J, Strogatz S H. Nature (London) 1998;393:440–442. doi: 10.1038/30918. [DOI] [PubMed] [Google Scholar]
- 7.Barabasi A-L, Albert R. Science. 1999;286:509–512. doi: 10.1126/science.286.5439.509. [DOI] [PubMed] [Google Scholar]
- 8.Jain S, Krishna S. Phys Rev Lett. 1998;81:5684–5687. [Google Scholar]
- 9.Jain S, Krishna S. Comput Phys Commun. 1999;121–122:116–121. [Google Scholar]
- 10.Dyson F. Origins of Life. Cambridge, U.K.: Cambridge Univ. Press; 1985. [Google Scholar]
- 11.Kauffman S A. J Theor Biol. 1986;119:1–24. doi: 10.1016/s0022-5193(86)80047-9. [DOI] [PubMed] [Google Scholar]
- 12.Kauffman S A. The Origins of Order. Oxford, U.K.: Oxford Univ. Press; 1993. [Google Scholar]
- 13.Farmer J D, Kauffman S A, Packard N H. Physica. 1986;D22:50–67. [Google Scholar]
- 14.Bagley R J, Farmer J D. In: Artificial Life II. Langton C G, Taylor C, Farmer J D, Rasmussen S, editors. Redwood City, CA: Addison–Wesley; 1991. pp. 93–140. [Google Scholar]
- 15.Bagley R J, Farmer J D, Fontana W. In: Artificial Life II. Langton C G, Taylor C, Farmer J D, Rasmussen S, editors. Redwood City, CA: Addison–Wesley; 1991. pp. 141–158. [Google Scholar]
- 16.Fontana W. In: Artificial Life II. Langton C G, Taylor C, Farmer J D, Rasmussen S, editors. Redwood City, CA: Addison–Wesley; 1991. pp. 159–209. [Google Scholar]
- 17.Fontana W, Buss L. Bull Math Biol. 1994;56:1–64. [Google Scholar]
- 18.Bak P, Sneppen K. Phys Rev Lett. 1993;71:4083–4086. doi: 10.1103/PhysRevLett.71.4083. [DOI] [PubMed] [Google Scholar]
- 19.Happel R, Stadler P F. J Theor Biol. 1998;195:329–338. doi: 10.1006/jtbi.1998.0797. [DOI] [PubMed] [Google Scholar]
- 20.Yasutomi, A. & Tokita, K. (1998) Preprint, http://paradox.harvard.edu/∼ tokita/list.html.
- 21.Segré D, Ben-Eli D, Lancet D. Proc Natl Acad Sci USA. 2000;97:4112–4117. doi: 10.1073/pnas.97.8.4112. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Odum E P. Fundamentals of Ecology. Philadelphia: Saunders; 1953. [Google Scholar]
- 23.Ashmore P G. Catalysis and Inhibition of Chemical Reactions. London: Butterworth; 1963. [Google Scholar]
- 24.Eigen M. Naturwissenschaften. 1971;58:465–523. doi: 10.1007/BF00623322. [DOI] [PubMed] [Google Scholar]
- 25.Rossler O E. Z Naturforschung. 1971;26b:741–746. [PubMed] [Google Scholar]
- 26.Kauffman S A. J Cybernetics. 1971;1:71–96. [Google Scholar]
- 27.Eigen M, Schuster P. The Hypercycle. Berlin: Springer; 1979. [Google Scholar]