
Figure 2.
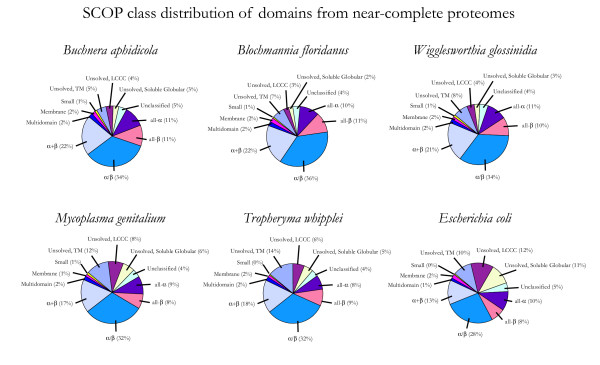
SCOP class distribution in near-complete proteomes. The fraction of domains in each proteome belonging to each of the first 7 SCOP classes is shown. "Unclassified" domains are from proteins annotated as homologous to a known structure using Pfam, but not classified in one of the first 7 classes of SCOP (e.g., due to being in a superfamily solved since the SCOP cutoff date of 15 May 2004). "Unsolved" domains are from proteins not annotated as homologous to a known structure. For statistical analysis, each ORF in the latter two categories was treated as containing exactly one domain. "Unsolved" domains are further divided into three categories based on predicted tractability in high-throughput experiments: "Unsolved, TM" are predicted to contain at least one transmembrane helix, "Unsolved, LCCC" have no predicted transmembrane helices but at least 20% of the sequence in low complexity or coiled coil regions, and "Unsolved, Soluble Globular" are predicted to be tractable in high-throughput experiments due to having neither of these features.