

Abstract
I use a model to show how simple, bottom-up, neural mechanisms in primary visual cortex can qualitatively explain the preattentive component of complex psychophysical phenomena of visual search for a target among distracters. Depending on the image features, the speed of search ranges from fast, when a target pops-out or is instantaneously detectable, to very slow, and it can be asymmetric with respect to switches between the target and distracter objects. It has been unclear which neural mechanisms or even cortical areas control the ease of search, and no physiological correlate has been found for search asymmetry. My model suggests that contextual influences in V1 play a significant role.
Visual search is an important task associated with visual segmentation, and phenomena such as pop out and asymmetries have been extensively studied (1–5). Examples of pop out are that a red dot can be instantly spotted among a background of green ones or a vertical line among horizontal ones. Not everything pops out—a red “X” is much more difficult to spot among green X’s and red “O’s”, and locating it may require attentive serial search (1, 4–6). An example of search asymmetry is that a long line is easier to spot among shorter lines than vice versa. Other typical target-distractor pairs manifesting the asymmetry include tilted vs. vertical, curved vs. straight, and convergent vs. parallel lines, incomplete vs. complete circles, and ellipses vs. circles (3).
A leading psychophysical model (1, 3) of these phenomena accounts for them by considering maps of basic feature dimensions and their interactions. The basic feature dimensions include primitive aspects of inputs such as orientation, color, and brightness. A target is supposed to be instantly detectable against a background provided that its value (or feature) in one of these dimensions (e.g., being oriented vertically or being red) is possessed by none of the distracters. However, if a target is only distinguished from the background by a conjunction of features (e.g., being red and an X, for a target red X against a background of green X’s and red O’s), and particularly by a conjunction of two orientations (6), then it will be difficult to spot. This model has been extended to account for search asymmetries by suggesting that, for some features (such as line length or curvature), targets with larger values (longer or more curved lines) are inherently more detectable than targets with smaller values (shorter or more straight lines) (3). For features without an obvious order, such as closure vs. openness, the data on search asymmetries themselves are used to decide which feature values are “larger” (more detectable) or “smaller” (less detectable).
The model is powerful, and various related and extended models have been proposed to explain a whole continuum of search efficiencies by combining parallel and serial search (4–6). Further, a related model of pop out (2) assumes a set of special features that constitute textons. In this paper, I complement these models by proposing, using a model, that intracortical interactions in V1 are a neural basis for the preattentive component of the search phenomena. It has already been suggested that suppression from similar stimuli outside classical receptive fields contributes to pop out (7, 8), and recently some striate cortical cells were observed to respond more strongly to pop out feature stimuli than stimuli of spatially uniform features (9, 10). My model aims to determine the underlying cortical area for a whole spectrum of difficulties of search for various input stimuli and will show that both suppression and facilitation from the visual context play roles. My model suggests rationales for what should count as a feature dimension, why asymmetries have particular signs, and why conjoining some features is more difficult than others.
I suggest that V1 influences the degrees of ease of search by determining the saliencies of the visual stimuli in inputs. V1 neurons respond directly only to stimuli within their classical receptive fields (CRFs). However, horizontal intracortical connections have been observed to link V1 cells with nearby CRFs (11, 12) and are suggested to be responsible for the modulation of cells’ responses by contextual stimuli outside (but near) their CRFs (7, 13–16). The contextual influences can be suppressive or facilitative depending on the configuration of the contextual stimuli (7, 15–17). I assume that pop out occurs when the response to the target, which is determined by target features as well as contextual features from distracters, is significantly higher than the responses to distracters (which also depend on both direct and contextual stimuli), making the target relatively more salient and easier to spot. Asymmetry arises because the effective contextual interactions are quite different when the target and the distracter objects are swapped. This straightforward idea accounts for a wide range of visual search phenomena. Its realization in my model depends on the complex neural dynamics in the intracortical circuit; although the goal here is to understand the search phenomena rather than the dynamics themselves.
The Model and Its Performance
The model is based on biological data and focuses on the part of V1 responsible for contextual influences (Fig. 1B): layer 2–3 pyramidal cells, interneurons, and horizontal intracortical connections (11, 14, 18). In the model, the centers of the CRFs are uniformly distributed in space. The preferred orientations of the cells at a given location span 180°. The pyramidal cells and interneurons interact with each other locally (18). Images are filtered by edge- or bar-like local CRFs to form the direct input to the excitatory pyramidal cells. Based on experimental data (11, 14), nearby pyramidal cells preferring similar orientations influence each other via horizontal intracortical connections. A pyramidal cell can excite another monosynaptically or can inhibit it disynaptically by projecting to the interneurons that inhibit, and are close to, the target pyramidal cell. The graded responses of the pyramidal cells model firing rates, which are initially determined by the direct inputs within their CRFs and then are quickly modulated by the contextual inputs through the intracortical interactions. These cells report the results of V1 processing, and their temporal averages are the outputs of the model. The horizontal connections are constrained so that the model exhibits the contextual influences observed physiologically (7, 15–17, 19). In particular, (i) the response to a test bar in the CRF is suppressed significantly by similarly oriented bars in the surround (iso-orientation suppression) (7); (ii) the suppression is weaker or weakest, respectively, when the surround bars are oriented randomly or orthogonally to the test bar (7, 17); (iii) however, if the surround bars are aligned with the test bar to form a smooth contour, suppression becomes facilitation (15, 16); (iv) additionally, the responses to bars at or near texture borders are higher than those to bars far inside texture regions (19). The model interactions have not been made consistent with all sources of data because of inconsistencies among the results of experiments. For instance, with colinear surrounds, facilitation is observed by some with a low contrast test bar (15, 16), but suppression is observed by others on a test bar of high contrast (7). Psychophysically, colinear facilitation occurs, and smooth contours have higher saliencies than random backgrounds, under both low and high input contrasts (20–22). My model accommodates colinear facilitation at any contrast and iso-orientation suppression in the same neural circuit. To achieve this, two nearby and linked pyramidal cells (with similar orientation preferences) predominantly excite each other monosynaptically when CRFs are co-aligned and predominantly inhibit each other disynaptically otherwise. Both excitation and inhibition spread no more than 10 CRF sizes. For instance, the central vertical bar in the iso-orientation stimulus of Fig. 2B receives colinear excitation from nearby vertical bars roughly above and below it but disynaptic inhibition from those roughly to its left and right. The synaptic weights are such that the total inhibition on this bar overwhelms the total excitation to achieve iso-orientation suppression. The neural interactions in the model, as conceptually described above, can be summarized for the interested readers by the equations (these details are not necessary for readers to follow the operation of the model and the rest of the paper):
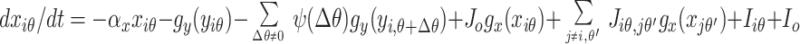 |
1 |
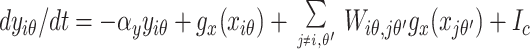 |
2 |
where xiθ and yiθ model the pyramidal and interneuron membrane potentials, respectively, indices i or j mark the centers of the CRFs and θ or θ′ the preferred orientations, gx(x) and gy(y) are sigmoid-like functions modeling cells’ firing rates or responses given membrane potentials x and y, −αxxiθ and −αyyiθ model the decay to resting potentials, ψ(Δθ) is the spread of inhibition within a hypercolumn, Jogx(xiθ) is self or local excitation of the pyramidal cells, Jiθ,jθ′ is the monosynaptic synaptic connection weight from pyramidal cell jθ′ to pyramidal cell iθ, while Wiθ,jθ′ is the synaptic weight from pyramidal cell jθ′ to interneuron iθ that inhibits the local pyramidal cell iθ (serving disynaptic inhibition from pyramidal jθ′ to iθ), Iiθ is the direct visual inputs to the CRF of pyramidal cell iθ, and Ic and Io are background inputs, including neural noise and inputs modeling the general and local normalization of activities (23, 24).
Figure 1.

The model. (A) An input of intermediate contrast to the model. Each bar excites the principal model cells with the appropriate preferred locations and orientations. (B) The local principal (pyramidal) cells and interneurons are roughly reciprocally connected. Each pyramidal cell receives direct input from no more than one bar in the input in A. The pyramidal cells interact with each other (monosynaptically and disynaptically) via horizontal connections, and determine C—the output of the model, with the target’s z score indicated. The thicknesses of the bars are proportional to the temporal averages of pyramidal outputs.
Figure 2.

Contextual influences on the center, vertical (target), bar. All visible bars have the same high input contrast except for the near and super-threshold target bar in E, as in the physiological experiments (7, 15). (A) No contextual stimulus. (B–D) Contextual stimuli are bars oriented parallel, orthogonal, or randomly to the target bar, respectively, as in physiological experiments (7). The ratio of the responses to the target bar in A, B, C, and D is 0.98:0.23:0.74:0.41. (E) A simulation of the experiment in ref. 15. A low contrast (center) target bar is aligned with high contrast contextual bars in a background of randomly oriented bars, leading to a response 70% higher than those to high contrast bars in B. All results are sensitive to input contrast levels.
In each input image (except for Fig. 2E), all of the
visible bar segments have the same (superthreshold) strength.
Contextual influences cause the ultimate responses of the cells to the
bars (shown as proportional to the thickness of the bars in the
figures) to differ. Each plot shows only a small part of a larger input
or output image. In Fig. 1, the greatest response is to the horizontal
bar in the cross because it escapes the iso-orientation suppression
that dampens the responses to the vertical bars. This makes the cross
pop out, assuming that the saliency of an item (i.e., the cross) is
determined by its most salient feature (i.e., the bar). Let
S be the pyramidal response to the most salient bar in an
image item or at an image location and 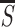 and
σs be the mean and standard deviation of
S at all locations of visible stimuli. I assess the relative
saliency of an item by two quantities r
S/
and
σs be the mean and standard deviation of
S at all locations of visible stimuli. I assess the relative
saliency of an item by two quantities r
S/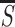 and z
(S −
and z
(S −
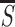 )/σs (although it may
be psychophysically incomplete). r can be directly
visualized in the thicknesses of the output bars in the figures whereas
z models the psychological z score. A highly
salient target should have large values (r > 1,
z > 1), e.g. (r = 2.4,
z = 7.1), in the above example (Fig. 1C).
The saliency in the background of an image is usually not uniform
(i.e., σs > 0), mainly because of the
nonuniform density and alignment of the background bars, as in Fig.
1A, and because of the differences among
distracters.
)/σs (although it may
be psychophysically incomplete). r can be directly
visualized in the thicknesses of the output bars in the figures whereas
z models the psychological z score. A highly
salient target should have large values (r > 1,
z > 1), e.g. (r = 2.4,
z = 7.1), in the above example (Fig. 1C).
The saliency in the background of an image is usually not uniform
(i.e., σs > 0), mainly because of the
nonuniform density and alignment of the background bars, as in Fig.
1A, and because of the differences among
distracters.
A comparison of Fig. 3A and Fig. 1 A and C shows an example of asymmetry: A bar among crosses is much less salient than a cross among bars. This is consistent with previous theories (1, 3): The horizontal bar in the target cross is unique and so pops out, but the vertical target bar is not unique and lacks a horizontal bar in the face of the distracters. Fig. 3 B and C compares the target ‘⌿’ in two different contexts. Against a texture of ‘∤’ it is highly salient because of its unique horizontal bar. Against ‘∤’ and ‘⍀’ it is much less salient because only the conjunction of ‘—’ and ‘/’ distinguishes it, as suggested by psychophysical models (5, 6), but without an explicit representation in my model for conjunction between the bars. Again, the bar whose orientation is not matched in the surround experiences less iso-orientation suppression.
Figure 3.

Inputs and outputs for examples of visual search,
with the target’s relative saliency z score indicated
under the outputs. All visible bars have the same intermediate input
contrast. (A) A vertical target bar among cross distracters
is less salient than a target cross among bars in Fig. 1. The response
S to the target is within the standard deviation from
the average response 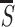 to all image items.
(B) Target ‘⌿’ among distracters
‘∤’. The horizontal bar in the target is the most
salient in the image, and its S is 150% higher than the
average
to all image items.
(B) Target ‘⌿’ among distracters
‘∤’. The horizontal bar in the target is the most
salient in the image, and its S is 150% higher than the
average 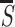 of the image items. (C)
Target ‘⌿’ among distracters
‘∤’ and ‘⍀’ . The target is
actually less salient than average in this example.
of the image items. (C)
Target ‘⌿’ among distracters
‘∤’ and ‘⍀’ . The target is
actually less salient than average in this example.
When neither target nor distracters has a primitive feature (e.g., a particular orientation) that is absent in the other, search asymmetry is much weaker but still present. Many examples of search asymmetries are also psychophysically weak (3, 25). Usually, the phenomena can no longer be understood simply by iso-orientation (or iso-feature) suppression alone. Local colinear excitation and general (orientation nonspecific) surround suppression also play roles. Fig. 4 shows that the model can account for the signs of the typical examples of asymmetry by using stimuli modeled after those in Treisman and Gormican (3). The responses to different items differ only by small fractions, i.e., r ≈ 1, and would be hard to visualize in a figure. However, these fractions are significant for the more salient targets when the background saliency (responses S) is homogeneous enough (i.e., σs small) to make z score large and the search easier (note that z ≥ 3 makes a target more salient than 99% of all items in images). In Fig. 4A, colinear excitation makes longer lines more salient than shorter ones. In Fig. 4B, a pair of parallel bars is less salient because stronger suppression occurs between the two (iso-oriented) bars. In Fig. 4C, a gap in a circle withdraws from the colinear facilitation as well as the general and iso-orientation suppression between the circle segments; apparently, the suppression is quantitatively more reduced than the facilitation to make the gapped circle more salient. In Fig. 4D, colinear excitation within and between image items is not so sensitive to a slight change in item curvature, but iso-orientation suppression is stronger in a background of straight (than curved) lines to make a curved target more salient. In Fig. 4E, interaction between circles (via the circle segments) depends only on the circle–circle distance, whereas interaction between ellipses depends additionally on another random factor—the orientation of the ellipse–ellipse displacement. Hence, noisier cortical responses (larger σs) are evoked from a background of ellipses (than circles), submerging responses (reducing z) from a target circle. It is hard to directly compare the z score in my model with the reaction time in the experiments (3) (see Discussion), and the strengths of asymmetry are sensitive to stimulus parameters in the model and experiments. The model exhibits strongest asymmetries for closed vs. open circles and circle vs. ellipse pairs among the five examples, comparable with the order of strengths of the asymmetries in the experiment (3); however, the asymmetry between straight vs. curved lines is perhaps weaker in the model than human vision. In human vision, search for an open circle among closed circle distracters is almost parallel and insensitive to the size of the gap in the open circle up to half of the circumference (3), suggesting the importance of line ends or terminators for preattentive vision. Although my model does not explicitly use a terminator feature, it exhibits the same insensitivity with z scores of z = 9.7, 8.7, 7.5≫ 1 for gap sizes of 1/6 (Fig. 4C), 1/3, and 1/2 of the circumference, respectively. However, the asymmetry between open and closed circles disappears for a large gap size of 1/2 of the circumference in human vision (3), but not in my model, leaving open the mechanism for and significance of closure or curve length in saliency. Because the model is rotationally invariant (so no single orientation is treated specially), it cannot explain why a line slightly tilted from vertical pops out more readily from vertical line distracters than vice versa. Of course, neither our visual environment nor our visual system is in fact rotationally invariant.
Figure 4.

Five typical examples of visual search asymmetry as simulated in the model (arranged in columns). The input stimuli are plotted, and the target saliency z scores are indicated below each of them. All input bars are of the same intermediate input contrast. The role of figure and ground is switched from the top to the bottom rows.
Discussion
My model suggests that V1 responses directly report the saliencies of input stimuli that control visual search and that contextual influences in V1 make these saliencies reflect the distinctiveness of targets against backgrounds in a way that is consistent with the experimental data on preattentive visual search. By using a stripped-down model, I have isolated intracortical interactions as the primary neural basis within V1 for some qualitative aspects of visual search: pop out and its feature dependence, and the existence and the directions of search asymmetries. The horizontal interactions in my model, in particular, the synaptic weights of the connections, are constrained by anatomical and physiological data and are not the results of fitting the visual search data. That the model can nevertheless qualitatively account for many of the psychophysical observations further supports the proposal of this paper. My model suggests a neural basis for the preattentive component of the search phenomena only. The search ultimately requires decision making and often visual attention or top-down control (especially when the subject knows the target identity), and many attentive and quantitative aspects, e.g., conjunction detections and search times, cannot be modeled in my model without assumptions about these additional, probably extrastriate, mechanisms. Note that I model the dependence of saliencies on input features and configurations rather than how a saliency map directs attention shifts (26).
The model suggests that the unique features and the primitive feature dimensions in existing psychophysical models might find their basis in the intracortical interactions as well as the visual representations (by the CRFs) in V1. For the example of the feature of orientation, the intracortical connections tend to link cells preferring similar orientations (11, 12). A target bar can be viewed as having a unique orientation (feature) if the V1 cell most responsive to the bar does not have substantial intracortical connections from the cells responding to the background bars that are oriented homogeneously but differently enough from the target bar. In other words, the selectivity of the intracortical connections to the preferred orientations of the linked cells implies that orientation is a basic feature dimension, and the orientation tuning width of these connections determines through cortical dynamics the minimum orientation difference [the preattentive just noticeable difference (27)] necessary for a bar to pop out as a unique feature in the orientation dimension by escaping the iso-orientation suppression from the background. The same thing should apply for other basic feature dimensions, such as color, stereo, motion speed, and spatial frequency, as supported by physiological evidence (14, 28) that intracortical connections tend to link neurons with similar selectivities in these dimensions as well. Hence, an image item could pop out when it is unique in these dimensions, and iso-feature (e.g., iso-disparity) suppression could reduce the saliencies of the background when the background features (e.g., depth) are homogeneous. Consider the implication of my argument on conjunctions between feature dimensions: say, motion and orientation. If the intracortical connections link two cells only when they prefer similar feature values in both, rather than one, of the dimensions, a conjunction of motion and orientation (coded by one V1 cell) should be easier to spot (29) than a conjunction of two orientations (5, 6), e.g., in Fig. 3C (coded by two, rather than one, V1 cells). In addition, many of the smaller versus larger feature values (e.g., short vs. long lines, closed vs. open circles), as proposed by the existing models to account for search asymmetries (3), could find their origins in V1 as generated from the basic (orientation) features via the complex interplay between suppressive and facilitative contextual influences.
My model also suggests that, because of the contextual influences, saliencies depend on the image configuration as a whole. Hence, the ease of search and the direction of the asymmetry depend on the densities and positions of image items, the similarity between target and distracter (which is inversely correlated with r), and the heterogeneity amongst the distracters (correlated with σs), as observed in psychophysical studies (4). The ease of search may not hold for every stimulus configuration for a given target-distracter pair, but only on average over some set of configurations. To understand why contextual influences and search phenomena should be related, I have suggested (24, 30) that contextual influences serve preattentive visual segmentation by highlighting important or conspicuous image locations, e.g., smooth contours and boundaries between luminance or texture regions (15, 19), as demonstrated in this model and shown by examples in Fig. 5. Consequently, distinctive small figures pop out because they are the boundaries of themselves from the background; the search asymmetries manifest further the subtleties of the underlying computational mechanism.
Figure 5.

Three examples of how the model operates as a saliency network to highlight important or conspicuous locations in the image—smooth contours against background noise, or boundaries between simple or more complex texture regions.
Many models of contextual influences and intracortical interactions exist, some focusing on the underlying neural circuits (e.g., ref. 31), and others on visual feature or contour linkings by intracortical interactions (e.g., refs. 32–34). Because most models omit search phenomena, I provide detailed comparisons between models elsewhere (23). Sagi’s two-stage model (35), spatial filtering followed by nonlinearity and local surround inhibition, was applied (36) to explain search asymmetry data by (25). The second stage can be seen as a phenomenological model of the cortical contextual suppression. The authors’ idea that random background textural variabilities act as noise to limit search performance (36) is related to the high saliency variance σs in my model to reduce the z score. However, without a detailed model of the contextual interactions, it is harder for that model to account for asymmetry when the distracter background has little (e.g., orientation) variability. More recently, Sagi and collaborators modeled a detailed cortical circuit for contextual influences, although it is for lateral masking detection tasks (37).
Because of its low density in input sampling and its current omission of color, motion, or stereo inputs and multiscale sampling, my model cannot yet generate spatially precise stimuli, such as ellipses and circles of exactly the same size, nor can it yet simulate many of the more complex stimuli used in psychophysical experiments (1, 3–5, 25). Nevertheless, its facility at providing a single neural basis for a host of search phenomena establishes V1 as the likely site of preattentive search and an important target for future investigation. An extended implementation is needed to explore the potential and limits of V1 mechanisms to mediate visual search. For instance, one could test whether V1 mechanisms can explain pop out by uniqueness in seemingly high level or scene based properties like directions of lighting or shading (38, 39) and whether a continuum of search efficiencies arises when a target is defined by conjunctions such as color-and-orientation, disparity-and-color, and motion-and-orientation-and-disparity, as suggested by experimental observations (5, 6, 29, 40). Through computational modeling, the psychophysical data on the search efficiencies in various inter- and intradimensional stimulus conditions constrain the underlying intracortical connections, as hinted by the discussion earlier. In particular, they should generate predictions on the selectivities of the connections to the preferred color, disparity, motion, and spatial frequencies of the linked cells, on which experimental data are still scanty.
Acknowledgments
I thank Peter Dayan, Geoff Hinton, Nancy Kanwisher, Earl Miller, Bart Anderson, and the two reviewers for comments on various versions of the manuscript, and Peter Dayan for many helpful conversations. Funding is provided in part by the Gatsby Foundation.
ABBREVIATION
- CRF
classical receptive field
Footnotes
This paper was submitted directly (Track II) to the Proceedings Office.
References
- 1.Treisman A, Gelade G A. Cognit Psychol. 1980;12:97–136. doi: 10.1016/0010-0285(80)90005-5. [DOI] [PubMed] [Google Scholar]
- 2.Julesz B. Nature (London) 1981;290:91–97. doi: 10.1038/290091a0. [DOI] [PubMed] [Google Scholar]
- 3.Treisman A, Gormican S. Pyschol Rev. 1988;95:15–48. doi: 10.1037/0033-295x.95.1.15. [DOI] [PubMed] [Google Scholar]
- 4.Duncan J, Humphreys G. Psychol Rev. 1989;96:1–26. doi: 10.1037/0033-295x.96.3.433. [DOI] [PubMed] [Google Scholar]
- 5.Wolfe J M, Cave K R, Franzel S L. J Exp Psychol. 1989;15:419–433. doi: 10.1037//0096-1523.15.3.419. [DOI] [PubMed] [Google Scholar]
- 6.Treisman A, Sato S. J Exp Psychol. 1990;16:459–478. doi: 10.1037//0096-1523.16.3.459. [DOI] [PubMed] [Google Scholar]
- 7.Kneirim J J, van Essen D C. J Neurophysiol. 1992;67:961–980. doi: 10.1152/jn.1992.67.4.961. [DOI] [PubMed] [Google Scholar]
- 8.Desimone R, Duncan J. Annu Rev Neurosci. 1995;18:193–122. doi: 10.1146/annurev.ne.18.030195.001205. [DOI] [PubMed] [Google Scholar]
- 9.Kastner S, Nothdurth H C, Pigarev I N. Vision Res. 1997;37:371–376. doi: 10.1016/s0042-6989(96)00184-8. [DOI] [PubMed] [Google Scholar]
- 10.Nothdurth H C, Gallant J L, van Essen D C. Visual Neurosci. 1999;16:15–34. doi: 10.1017/s0952523899156189. [DOI] [PubMed] [Google Scholar]
- 11.Rockland K S, Lund J S. J Comp Neurol. 1983;216:303–318. doi: 10.1002/cne.902160307. [DOI] [PubMed] [Google Scholar]
- 12.Gilbert C D, Wiesel T N. J Neurosci. 1983;3:1116–1133. doi: 10.1523/JNEUROSCI.03-05-01116.1983. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Allman J, Miezin F, McGuinness E. Annu Rev Neurosci. 1985;8:407–430. doi: 10.1146/annurev.ne.08.030185.002203. [DOI] [PubMed] [Google Scholar]
- 14.Gilbert C D. Neuron. 1992;9:1–13. doi: 10.1016/0896-6273(92)90215-y. [DOI] [PubMed] [Google Scholar]
- 15.Kapadia M K, Ito M, Gilbert C D, Westheimer G. Neuron. 1995;15:843–856. doi: 10.1016/0896-6273(95)90175-2. [DOI] [PubMed] [Google Scholar]
- 16.Polat U, Mizobe K, Pettet M W, Kasamatsu T, Norcia A M. Nature (London) 1998;391:580–584. doi: 10.1038/35372. [DOI] [PubMed] [Google Scholar]
- 17.Sillito A M, Grieve K L, Jones H E, Cudeiro J, Davis J. Nature (London) 1995;378:492–496. doi: 10.1038/378492a0. [DOI] [PubMed] [Google Scholar]
- 18.Douglas R J, Martin K A. In: Synaptic Organization of the Brain. Shepherd G M, editor. Oxford Univ. Press; 1990. pp. 389–438. [Google Scholar]
- 19.Gallant J L, van Essen D C, Nothdurth H C. In: Early Vision and Beyond. Papathomas T, Chubb C, Gorea A, Kowler E, editors. Cambridge, MA: MIT Press; 1995. pp. 89–98. [Google Scholar]
- 20.Polat U, Sagi D. Vision Res. 1993;33:993–999. doi: 10.1016/0042-6989(93)90081-7. [DOI] [PubMed] [Google Scholar]
- 21.Kovacs I, Julesz B. Proc Natl Acad Sci USA. 1993;90:7495–7497. doi: 10.1073/pnas.90.16.7495. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Field D J, Hayes A, Hess R F. Vision Res. 1993;33:173–193. doi: 10.1016/0042-6989(93)90156-q. [DOI] [PubMed] [Google Scholar]
- 23.Li Z. Neural Comput. 1998;10:903–940. doi: 10.1162/089976698300017557. [DOI] [PubMed] [Google Scholar]
- 24.Li, Z. (1999) Spatial Vision, in press.
- 25.Gurnsey R, Browse R A. Percept Psychophys. 1987;41:239–252. doi: 10.3758/bf03208222. [DOI] [PubMed] [Google Scholar]
- 26.Koch C, Ullman S. Human Neurobiol. 1985;4:219–227. [PubMed] [Google Scholar]
- 27.Foster D H, Ward P A. Proc R Soc London Ser B. 1991;243:83–86. doi: 10.1098/rspb.1991.0014. [DOI] [PubMed] [Google Scholar]
- 28.Li C Y, Li W. Vision Res. 1994;34:2337–2355. doi: 10.1016/0042-6989(94)90280-1. [DOI] [PubMed] [Google Scholar]
- 29.Mcleod P, Driver J, Crisp J. Nature (London) 1988;332:154–155. doi: 10.1038/332154a0. [DOI] [PubMed] [Google Scholar]
- 30.Li Z. Network Comput Neural Syst. 1999;10:187–212. [Google Scholar]
- 31.Stemmler M, Usher M, Niebur E. Science. 1995;269:1877–1880. doi: 10.1126/science.7569930. [DOI] [PubMed] [Google Scholar]
- 32.Grossberg S, Mingolla E. Percept Psychophys. 1985;38:141–171. doi: 10.3758/bf03198851. [DOI] [PubMed] [Google Scholar]
- 33.Yen S C, Finkel L H. Vision Res. 1998;38:719–741. doi: 10.1016/s0042-6989(97)00197-1. [DOI] [PubMed] [Google Scholar]
- 34.Pettet M W, McKee S P, Grzywacz N M. Vision Res. 1998;38:865–879. doi: 10.1016/s0042-6989(97)00238-1. [DOI] [PubMed] [Google Scholar]
- 35.Sagi D. In: Early Vision and Beyond. Papathomas T, Chubb C, Gorea A, Kowler E, editors. Cambridge, MA: MIT Press; 1995. pp. 69–78. [Google Scholar]
- 36.Rubenstein B, Sagi D. J Opt Soc Am A. 1990;9:1632–1643. doi: 10.1364/josaa.7.001632. [DOI] [PubMed] [Google Scholar]
- 37.Adini Y, Sagi D, Tsodyks M. Proc Natl Acad Sci USA. 1997;94:10426–10431. doi: 10.1073/pnas.94.19.10426. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Ramachandran V S. Nature (London) 1998;331:163–166. doi: 10.1038/331163a0. [DOI] [PubMed] [Google Scholar]
- 39.Enns J, Rensink R. Science. 1990;247:721–723. doi: 10.1126/science.2300824. [DOI] [PubMed] [Google Scholar]
- 40.Nakayama K, Silverman G H. Nature (London) 1986;320:264–265. doi: 10.1038/320264a0. [DOI] [PubMed] [Google Scholar]