
Figure 3. Model fitting, dimensionality and the blessings of smoothness.
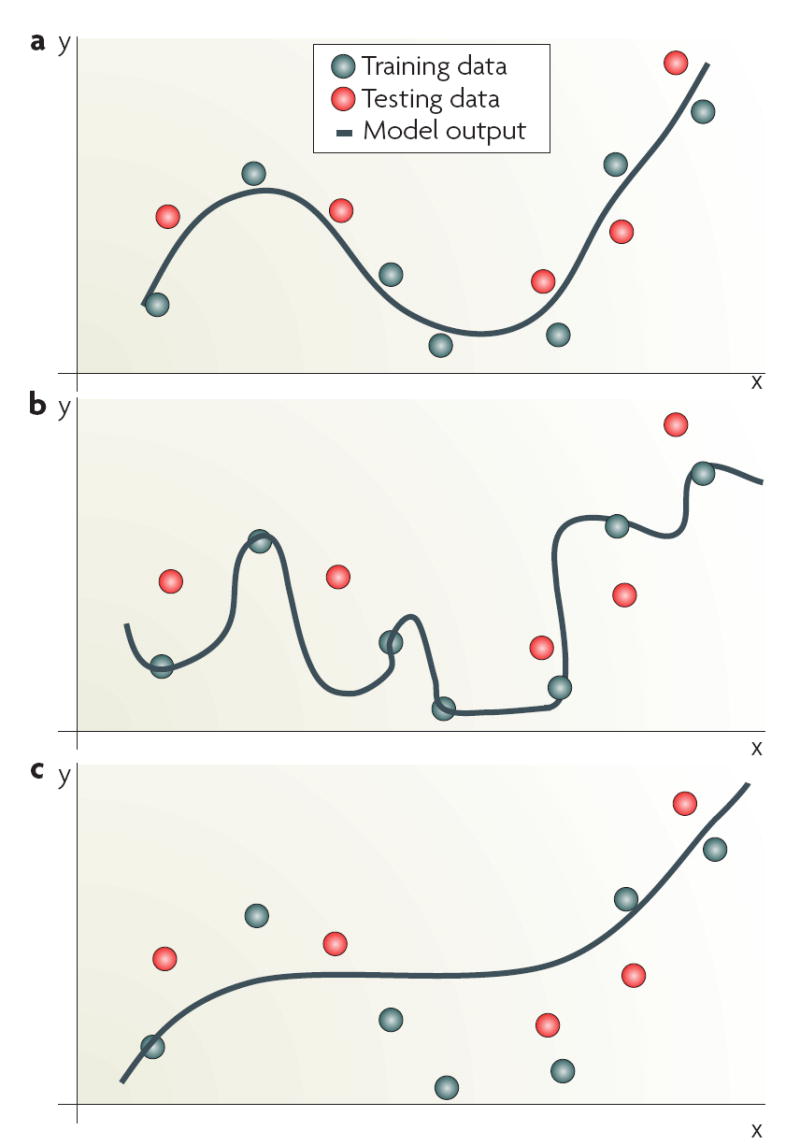
a | Output of a smooth function that yields good generalization on previously unseen inputs. b | A model that performs well on the training data used for model building, but fails to generalize on independent data and is hence overfitted to the training data. c | A model that is insufficiently constructed and trained and is considered to be underfitted. The imposition of stability on the solution can reduce overfitting by ensuring that the function is smooth, and some random fluctuations are well-controlled in high-dimensions46. This allows new samples that are similar to those in the training set to be similarly labelled. This phenomenon is often referred to as the ‘blessing of smoothness’. Stability can also be imposed using regularization that ensures smoothness by constraining the magnitude of the parameters of the model. Support vector machines apply a regularization term that controls the model complexity and makes it less likely to overfit the data (BOX 3). By contrast, k-nearest neighbour or weighted voting average algorithms overcome the challenge simply by reducing data dimensionality. Validation of performance is a crucial component in model building. Although an iterative sequential training is often used for both training and optimization114, validation must be done using an independent data set (not used for model training or optimization) and where there are adequate outcomes relative to the number of variables in the model39. For early proof-of-principle studies, for which an independent data set may not be available, some form of cross-validation can be used. For example, three-fold cross-validation is common, in which the classifier is trained on two-thirds of the overall data set and tested for predictive power on the other third36,115,116. This process is repeated multiple times by reshuffling the data and re-testing the classification error.