

Abstract
A method is presented for computing the average solution of problems that are too complicated for adequate resolution, but where information about the statistics of the solution is available. The method involves computing average derivatives by interpolation based on linear regression, and an updating of a measure constrained by the available crude information. Examples are given.
Outline of Goal and Method
There are many problems in science whose solution is described by a set of differential equations, but where the solution of these equations is so complicated that it cannot be found in practice, even numerically, because it cannot be resolved properly. An accurate numerical solution requires that the problem be well resolved, i.e., that enough variables (“degrees of freedom”) be retained in the calculation to represent all relevant features of the solution. Well known examples where good resolution cannot be achieved in practice include turbulence and various problems in statistical physics and in economics. We consider in the present paper what one should do in underresolved problems, i.e., problems where good resolution has not been achieved.
There exists a large literature on the solution of underresolved problems, describing a wide variety of problem-specific tools; for example, in the case of turbulence there are modeling methods and methods for “large-eddy simulation” (1). All these methods involve some assumptions about the relation between what one can effectively compute and the “invisible” degrees of freedom that cannot be properly represented. Obviously, nothing can be done without some information in addition to what can be computed. In the present paper we assume that the additional information consists of explicit information about a measure preserved by the differential equations. In many problems of interest this kind of information is available, but it does not seem to have been fruitfully utilized previously. The key special case of turbulence will be treated in detail elsewhere, where it will be shown that it falls within the class of problems to which our methods apply.
The situation of interest is as follows: Consider a differential equation of the form
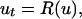 |
1 |
where t is the time and R(u) = R(u, ∂u/∂x, …) is a (generally nonlinear) function of its arguments. Assume in addition that a measure on the space of solutions of Eq. 1 is invariant under the flow induced by Eq. 1, and that we know what it is. We denote averages with respect to this measure by angle brackets: 〈⋅〉. We further assume that we cannot resolve u, but that we can find some information about u at a small number of mesh points; the information could consist of point values but it is more reasonable physically and mathematically to assume that what one has is “filtered” values, as would be indeed produced by a real physical measurement. We thus assume that what we have at the mesh points are the values ūα defined by:
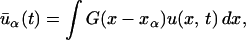 |
2 |
where α is an index on the mesh. The kernel G can represent, for example, spatial averaging. The coarse grid data in Eq. 2 specify, at every moment in time, a subset of functions (the functions that are consistent with these observations). We denote averages over this restricted subset by angle brackets with a subscript corresponding to the observations: 〈⋅〉ū. We call the measure on the restricted subset the “constrained measure.” If the problem is underresolved, the measure is carried by a nontrivial set of functions. It is important to note that the constrained measure is not invariant; indeed, if the invariant measure we start with is ergodic, the constrained measure tends in time to the unconstrained measure; for example, if we demanded that initially all the functions assumed given values at the grid points, there is no reason to believe that the solutions of the differential equations that evolve from these data would still take on the very same values at the mesh points at later times.
Our goal is to calculate averages of the solutions with respect to the constrained measure; these averages represent what one can calculate on the crude grid, properly averaged over the “invisible” degrees of freedom that cannot be represented on that grid. Given the constrained measure and the filtered values, the mean and the moments of the solution can be found at all points by interpolation (equivalent to linear regression, ref. 2), and therefore the mean derivatives of these quantities at the computational points can be found, for all practical purposes without error. The remaining problem is to characterize the evolution of the constrained measure so that the mean solution (and any moments that may be needed) can be advanced in time. Our assumption is that the constrained measure remains the invariant measure constrained by n filters, where n is the number of grid points. The filters therefore have to change in time. The formulas below will allow us to relate quantities whose evolution can be calculated to the parameters that determine the evolving filters. In the present paper we shall simplify the problem of finding the evolving filters by assuming that the filters are determined by the evolution of the mean solution (and not, for example, by the evolution of the higher moments of the solutions). This is equivalent to assuming that the equation
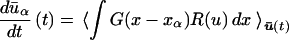 |
3 |
is a good approximation to the real evolution of the ūα(t) given by Eqs. 1 and 2. Of course, the validity of this assumption depends in particular on a good choice of filters G. In the present paper, we assume furthermore that the measure is either Gaussian or approximately Gaussian, in a sense specified below.
The two keys to success are: (i) averaging with respect to the right constrained measure and (ii) updating the constraints as the solutions evolve. Ingredient (i) was already used numerically in ref. 3. A number of interesting attempts have been made over the years to “fill in” data from coarse grids in difficult computations so as to enhance accuracy without refining the grid (see, e.g., refs. 4 and 5), but without our two key ingredients the usefulness of the earlier methods is necessarily limited.
We proceed as follows: First we present some elementary but important results on constrained Gaussian probabilities; then we explain and apply our scheme in the special cases of linear and nonlinear Schrödinger equations. Note that in the nonlinear case the invariant measure is not Gaussian. We also explain why these are significant test models. Because these model equations have some simplifying features, we also sketch a more general methodology.
Gaussian Distributions: Conditional Expectation Under Affine Constraints
We start by describing how to calculate expectation values of functions of normally distributed variables when the variables satisfy constraints of the affine form. Let u = (u1, … , un)T be a real vector of jointly normal random variables; it has a probability density F(u) of the form,
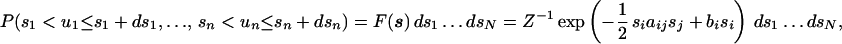 |
4 |
where Z is the appropriate normalization factor, repeated indices imply summation, the n × n matrix A with entries aij is symmetric, and its inverse A−1, assumed to exist, is the pairwise covariance matrix whose elements are
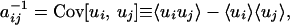 |
5 |
where the brackets denote averaging with respect to the probability density, and the vector b with components bi is related to the pointwise expectation values by
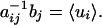 |
6 |
The distribution is fully determined by the n means and by the ½n(n + 1) independent elements of the covariance matrix; therefore, all expectation values of observables 〈𝒪(u)〉 can be expressed in terms of these parameters. In particular, all higher-order moments are given by Wick’s theorem (e.g., ref. 6).
Next, assume that the random vector u satisfies a set of affine constraints of the form,
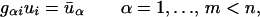 |
7 |
where the index α enumerates the constraints; the matrix G, whose entries are gαi, is the discrete analog of the continuous kernel G(·) introduced in Eq. 2. To distinguish between the vector space of random variables, (u1, … , un), and the vector space of constraints, (ū1, … , ūm), we use Roman and Greek letter indices, respectively.
Our goal is to calculate conditional expectation values, i.e., averages over the functions that satisfy the constraints; formally,
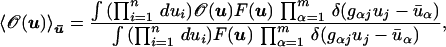 |
8 |
where the left-hand side introduces a notation for a constrained average and F(u) is the properly normalized probability density (Eq. 4). We shall use the following three lemmas:
Lemma 1. The conditional expectation of the variable ui obeys an affine relation,
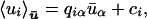 |
9 |
where the n × m matrix Q with entries qiα and the n-vector c with entries ci are
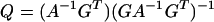 |
10 |
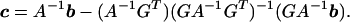 |
Lemma 2. The conditional covariance matrix has entries
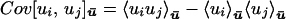 |
11 |
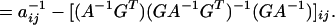 |
Lemma 3. Wick’s theorem holds for constrained expectations, namely,
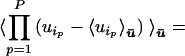 |
12 |
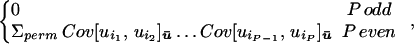 |
where the summation is over all possible pairings of the P coordinates that are in the list.
Lemmas 1 and 2 can be deduced from standard linear regression theory. Lemma 3 can be proved by noting that a delta function is the limit of a narrow Gaussian function. As a result, the projection of a Gaussian measure on the subspace of functions that satisfy the constraints can be viewed as approximately Gaussian, hence satisfying Wick’s theorem; an appropriate limit can then be taken.
A Linear Schrödinger Equation
We demonstrate our method by applying it to two equations of Schrödinger type. We chose these problems because we feel that a nonlinear Schrödinger equation is a suitable one-dimensional cartoon of the Euler/Navier-Stokes problem that we are most interested in: it is Hamiltonian and nonlinear. The more popular cartoon, the Burgers equation, will be analyzed elsewhwere; its peculiar properties (dominance of the solution by shocks and the need for a driving noise term to obtain an invariant measure) introduce added complications whose analysis does not fit within a short introductory paper.
We start with a linear Schrödinger equation written as a pair of real equations:
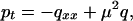 |
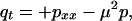 |
13 |
where p, q : [0, 2π) × [0, ∞) → ℝ, μ is a given constant, and periodic boundary conditions are assumed. This system of equations can be derived from a Hamiltonian,
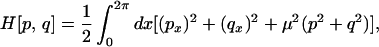 |
14 |
where p(x, t) and q(x, t) are the canonically conjugate variables.
This system has an invariant measure, the canonical measure, depending on a temperature that we set equal to one, so that the invariant measure has the density distribution F[p, q] = exp(−H[p, q]). The quadratic form of the Hamiltonian makes the canonical distribution Gaussian, completely specified by the average functions 〈p(x)〉 and 〈q(x)〉, which are zero by symmetry, and by the covariance functions,
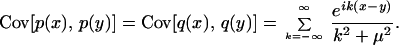 |
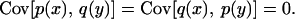 |
15 |
The measure is absolutely continuous with respect to a Wiener measure, and the sample functions in this ensemble are continuous but not differentiable with probability one, so that the evolution of a single solution in time is hard to calculate.
We pick initial data from the invariant ensemble, but then assume that measurement has revealed, at each of m points, the values of two sets of filtered quantities that can be though of as local averages of the solution:
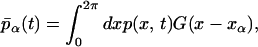 |
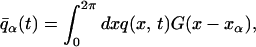 |
16 |
where α = 1, … , m, xα = 2πα/m are the points about which the averages are evaluated, and the function G(·) is a Gaussian filter (i.e., a function of Gaussian shape, not a random variable) of width σ. Once we know the values of these filtered values, the constrained average is defined. We wish of course to evaluate the future means of the solutions in the ensemble that has been constrained in this way, without calculating any particular solutions and using only the information at the m given points.
Given the values of the filters, formulas (Eqs. 9 and 11) allow us to find the mean of the solution in the ensemble conditioned by these filtered values; a short manipulation yields
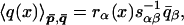 |
17 |
where
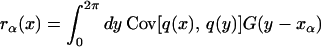 |
18 |
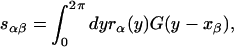 |
and the sαβ−1 are the α, β elements of the matrix that is the inverse of the matrix whose entries are the sαβ. The result of this procedure is shown in Fig. 1, where we plot the mean of the functions that satisfy the constraints that have been imposed at a set of 10 points. The width of the filtering kernel is σ = 2π/m (the distance between the grid points). Note that we know exactly the mean of the functions in the constrained ensemble, and we know it everywhere.
Figure 1.

The interpolating function. Given 10 constraints, p̄α (open circles), the mean of the functions in the constrained ensemble is reconstructed (solid line).
In the present linear problem, if one knows the mean of the functions in the constrained ensemble, one can readily evaluate the mean time derivative at the grid points by applying the differential operator to the mean function. However, one cannot integrate this mean derivative in time and expect to obtain the mean future, because at a later time the ensemble that will have evolved from the initial constrained ensemble will not be the same as the initial ensemble. The assumption in the whole approach is that the ensemble prepared initially by placing conditions (the values of the filters) on the functions sampled from the invariant ensemble evolves into an ensemble that can still be represented as a subset of the ensemble that carries the invariant measure, with a measure conditioned by new filters G and filtered values p̄ and q̄. Here we are making the further assumption that it is sufficient to advance in time only mean values of p̄ and q̄. Hence,
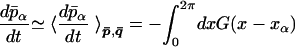 |
19 |
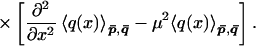 |
Using Eqs. 17 and 15 we find the more detailed expression:
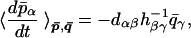 |
20 |
with
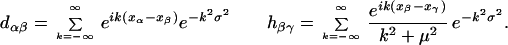 |
21 |
An analogous equation with opposite sign is obtained for the mean time derivative of the vector q̄. We now have a closed system of equations for the estimation of the mean values of p̄ and q̄ in the future. We emphasize that the last assumption whereby it is sufficient to advance in time the mean values of p̄ and q̄ is nonessential and unlikely to be true in general (see the concluding section). The domain of validity of the more general assumption remains to be determined.
In Fig. 2 we plot the mean evolution of five filtered values p̄α(t) for randomly selected initial values of p̄α(0) and q̄α(0). The filtering function G(·) has a width (defined above) equal to the distance between mesh points. In this linear problem the evolution of the mean of the filtered values can be calculated exactly simply by using Green’s function for the problem to advance the mean solution and hence advance the values of the filters. In Fig. 2 the results of an exact calculation of the filtered values are represented by open circles, and the results obtained by integrating the set of 10 ordinary differential equations (Eq. 20) are represented by dashed lines. The two results are practically indistinguishable.
Figure 2.

Mean evolution of the vector p̄ for m = 5. The initial values of the coarse variables were chosen randomly. The open circles represent the exact solution, whereas the dashed lines were obtained by integrating equations 20.
A Nonlinear Hamiltonian System
We now consider a nonlinear generalization of the method demonstrated in the preceding section. We want to exhibit the power of our method by comparing the solutions that it yields with exact solutions; in the nonlinear case, exact solutions of problems with random data are hard to find, and we resort to a stratagem. Even though our method applies to the full nonlinear partial differential equation, we study a finite dimensional system of 2n ordinary differential equations that is formally an approximation of a nonlinear Schrödinger equation:
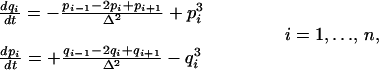 |
22 |
where Δ = 1/n is a mesh size. The approximation is formal because the solutions of the differential equation are not smooth enough to ensure convergence. We consider a periodic system so that q0 = qn and qn+1 = q1 (with analogous conditions on p). In the calculations below, n = 16.
The Hamiltonian of this system is
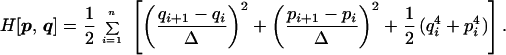 |
23 |
Starting from this discrete system, we shall use a discrete version of the method above to deduce equations for a reduced set of variables, which will reproduce the mean solution of the full set of equations, and we shall be able to show explicitly that the algorithm does what it should.
As in the linear case, we assume that the canonical distribution has a temperature equal to one. Note that now the Hamiltonian is not a quadratic function and the invariant measure is not Gaussian. The lemmas of section 2 cannot be used without approximation. The equilibrium distribution P(p, q) = e−H[p,q] is approximated by a Gaussian distribution, chosen so as to yield the same means and covariances as the original distribution. Symmetry considerations imply that 〈pi〉 = 〈pi〉 = 〈piqj〉 = 0. Translation and reflection invariance, on the other hand, imply that 〈pipj〉 = 〈qiqj〉 = f|i−j|. Thus, the approximate distribution depends on a single vector f|i−j| that can be calculated, for example, by a straightforward Monte Carlo simulation.
We define a subset of 2m coarse variables (m ≪ n) that represent local averages of the vectors p and q:
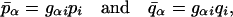 |
24 |
where the index α = 1, … , m enumerates the coarse variables. We consider the case m = 2; thus, we replace a set of 32 variables by a reduced set of 4 variables. The filtering matrix G with entries gαi has a Gaussian profile:
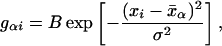 |
25 |
where B is a normalization factor, xi = i/n, x̄α = α/m, and σ is the width of the filter. In the calculations below we took σ = 0.25, i.e., the filter averages over an interval of the order of the distance between the coarse data points.
Given the constrained distribution, the mean time derivative of the coarse variables can be calculated. For example,
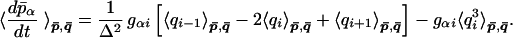 |
26 |
The first term on the right-hand side can readily be calculated by the interpolation formula (Lemma 1). For the second term, which involves the expected value of a cubic function of qi, we use the Gaussian approximation and apply Wick’s theorem,
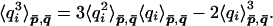 |
27 |
All these terms can be computed explicitly by using Lemmas 1 and 2. The mean time derivative of p̄1 is
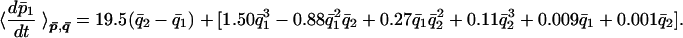 |
28 |
The term in square brackets is the “gaussianized” approximation to the cubic term in Eq. 26. The equation for p̄2 is obtained by substituting 1 ↔ 2; the equations for q̄1, q̄2 are obtained by the transformation p̄ → q̄ and q̄ → −p̄.
We now test the accuracy of the prediction of the mean evolution of the vectors p̄ and q̄, obtained by the integration of equations (Eq. 28). In contrast to the linear example, we do not have an exact mean solution for comparison. Instead, we generated numerically an ensemble of initial conditions that sampled the constrained canonical ensemble. We employed a standard Metropolis algorithm and sampled 104 states. Each state was then evolved in time using a fourth-order Runge–Kutta solver, and by averaging over the evolved ensemble we were able to compute the mean evolution of the solution of the system of 32 equations, which we then compared with the solution of the reduced system. The possibility of making this comparison is the reason we started with a discrete system rather than the full partial differential equation.
A comparison between the true mean and the mean produced by our averaging/updating procedure is shown in Fig. 3 a and b. The two graphs show different intervals of time; the coarse initial conditions are p̄1 = 0.2, p̄2 = 0.3, q̄1 = 0.6, and q̄2 = 0.55.
Figure 3.

Mean evolution of the coarse variables, p̄1 (▵), p̄2 (□), q̄1 (∗), and q̄2 (○). The symbols represent the mean evolution of an ensemble of initial conditions generated by means of a Monte Carlo algorithm. The solid lines are the solutions obtained by integrating the mean time derivatives (Eq. 28). The two graphs show different time intervals: (a) t = 0 − 0.2; (b) t = 0 − 10.
Discussion
We have shown by examples that one can calculate average solutions accurately on a crude grid. The examples were simple but not trivial; in particular, they were complicated enough so that the calculation of even a single sample solution was difficult. The main tools were interpolation based on regression and the characterization of constrained measures by time-dependent filters. In more complete papers to come we plan to show that the method generalizes to more complicated situations. In the Gaussian case, one can advance in time not only the mean solution but also its moments and covariances. As more information is updated, one can update not only the values of the filtered variables, but also parameters that determine the structure of the filters (i.e., one does not have to keep G in Eq. 2 fixed). In non-Gaussian problems, one can perform local “gaussianization” rather than global “gaussianization,” as above, and describe a broader range of measures. Furthermore, it should be obvious from the discussion that one does not need complete information about the measures, but only the covariances and low-order moments on scales smaller than the distance between mesh points. This partial information is available in a broad range of situations (7).
Acknowledgments
We are grateful to Prof. G. I. Barenblatt and to Dr. D. Nolan for many fruitful discussions. This work was supported by the Applied Mathematical Sciences Subprogram of the Office of Energy Research, under Contract Number DE-AC03-76SF-00098.
References
- 1.Lesieur M, Compte P, Zinn-Justin J, editors. Computational Fluid Mechanics, Les Houches Summer School of Theoretical Physics, Session 54. Amsterdam: Elsevier; 1996. [Google Scholar]
- 2.Papoulis A. Probability, Random Variables, and Stochastic Processes. New York: McGraw–Hill; 1991. [Google Scholar]
- 3.Chorin A J. Math Comp. 1973;27:1–15. [Google Scholar]
- 4.Scotti A, Meneveau C. Phys Rev Lett. 1997;78:867–870. [Google Scholar]
- 5.McComb W D, Watt H G. Phys Rev Lett. 1990;65:3281–3284. doi: 10.1103/PhysRevLett.65.3281. [DOI] [PubMed] [Google Scholar]
- 6.Kleinert H. Gauge Fields in Condensed Matter. Teaneck, NJ: World Scientific; 1989. [Google Scholar]
- 7.Barenblatt G I, Chorin A J. Proc Symp Appl Math. 1998;54:1–25. [Google Scholar]