
Figure 2.
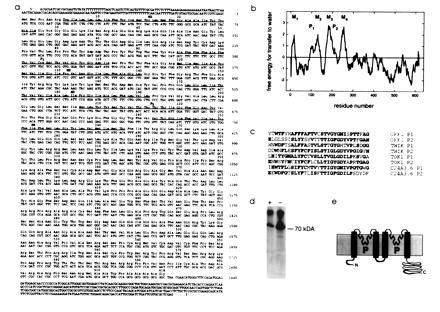
Nucleotide and deduced amino acid sequence of ORK1. (a) The 2.4-kb cDNA insert encoding ORK1 contains a single long ORF. Segments corresponding to putative pore-forming P domains and transmembrane segments (M1–M4) are underlined. The National Center for Biotechnology Information accession number for the nucleotide and amino acid sequence of ORK1 is U55321U55321. (b) Kyte–Doolittle hydrophilicity analysis of the ORK1 ORF with a window of 20 residues. (c) Alignment of the P domains of ORK1, Tok1, TWIK, and C24A3.6, a two P domain ORF from the Caenorhabditis elegans sequence data base (residues identical in 2 or more sequences are in boldface type); the probability that 8 random sequences would have the amino acid identities shown here is less than 10−50 as calculated by the method of Jan and Jan (30). While the overall similarity of ORK1 and Tok1 is low, the region extending from the first P domain to 20 residues past the second yields a 56% similarity and 23% identity with an quality score of 79 by the method of Needleman and Wunsch (26). Sequential randomizations and alignments of this region produce an average quality score of only 51 ± 3, suggesting that the channels share a single common ancestor; sequence data from other species are needed to establish this thesis. ORK1 and TWIK (14) show an overall amino acid identity of 21% and similarity of 48% with a quality score of 214. (d) In vitro translation of ORK1 with (+) or without (−) dog pancreatic microsomes resolved in an SDS/12.5% polyacrylamide gel and visualized by autoradiography. (e) Predicted membrane topology of ORK1.