
Figure 2.
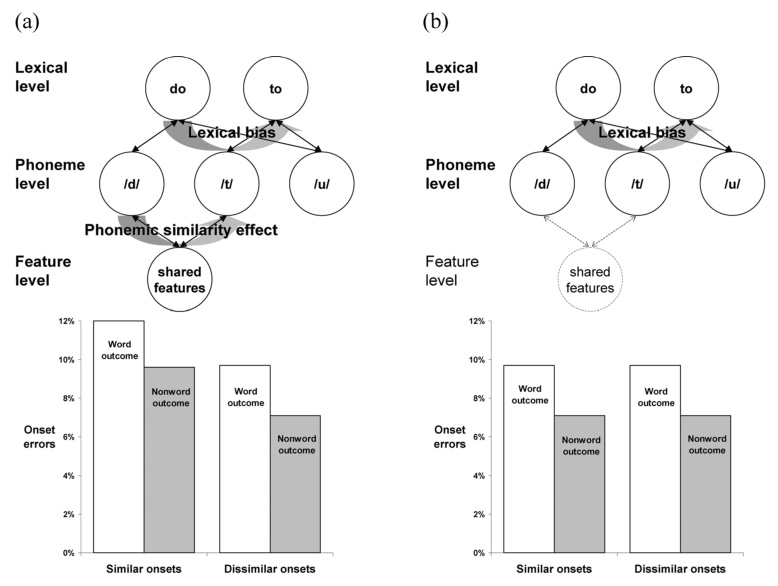
Model predictions for inner speech errors, based on the (a) Unimpoverished and (b) Surface-Impoverished hypotheses. Activated features feed back to connected phonemes, increasing the probability that a similar phoneme will be selected. (a) With feature-level activation, the model predicts an error distribution in inner speech that is identical to that in overt speech. (b) Without feature-level activation, no phonemes receive feedback activation from the features, and so both similar and dissimilar items are treated as if they were dissimilar. Lexical bias occurs in both conditions due to activation feeding back from phonemes to words. (Connection weights = 0.2, decay = 0.4, activation spreading period = 4 time steps, standard deviation of activation noise = 0.68; additional details are available upon request.)