
Figure 4.
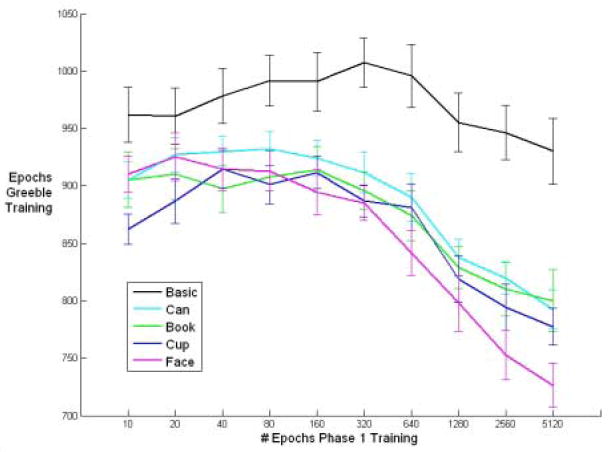
Amount of time to learn Greebles as a function of number of epochs of pretraining on the first task. Training concluded when the RMSE of the Greebles fell below .05. Networks at the basic level always took longer to learn Greebles than all other networks and did not benefit significantly from increased experience with the basic level task. All expert level networks benefited from more pre-training, especially faces. Error bars denote +/-1 standard error.