
Figure 9.
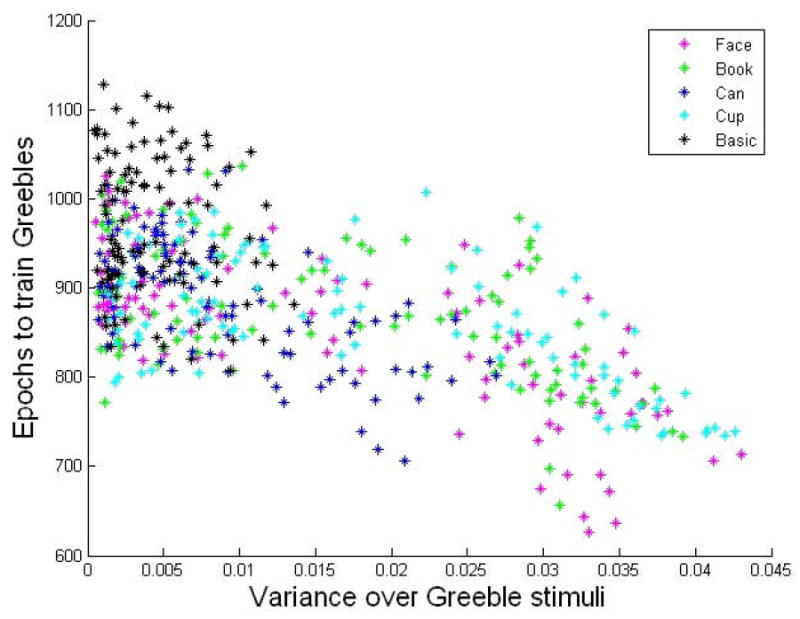
Time to learn Greebles over Greeble pre-training activation variance. As the variance of the hidden layer activations over the Greeble stimuli increases, the training required to learn Greebles decreases. This correlation is strong (r= -0.6317, p < 0.0001). This variance is taken before the networks are trained with Greebles and represents the initial spread of Greebles in representational space.