

Abstract
Research is presented on the semantic structure of 15 emotion terms as measured by judged-similarity tasks for monolingual English-speaking and monolingual and bilingual Japanese subjects. A major question is the relative explanatory power of a single shared model for English and Japanese versus culture-specific models for each language. The data support a shared model for the semantic structure of emotion terms even though some robust and significant differences are found between English and Japanese structures. The Japanese bilingual subjects use a model more like English when performing tasks in English than when performing the same task in Japanese.
Keywords: Japanese–English comparisons, bilingualism
The major finding of this paper is that English-speaking and Japanese-speaking subjects share a single model of the semantic structure of emotion terms. The incremental contribution of two culture-specific models, one based on an English norm and one based on a Japanese norm, accounts for relatively little of the total variance. Even though a single model accounts for the majority of the variance, there remain robust and statistically significant differences between the English and Japanese culture-specific models. Differences also exist in the performance of Japanese bilingual subjects performing tasks in Japanese versus in English.
These findings are relevant to a number of critical and controversial theoretical questions currently being debated in the behavioral sciences. The issue of cultural universals versus culture specificity or linguistic relativity is the most obvious. Bodies of research that are most directly related include Greenberg’s (1) work on cultural universals, the extensive literature on the universality of the linkage of emotions and facial expressions by Ekman and colleagues (2, 3), Osgood’s (4, 5) cross-cultural finding that all humans share a framework for differentiating the affective meanings of signs, Berlin and Kay’s (6) discovery of universal regularities in color terminology evolution, and the measurement of semantic structure using judged-similarity data, including Herrmann and Raybeck’s comparative study (7) showing impressive similarities in the semantic structure of emotion terms in six languages.
A semantic domain may be defined as an organized set of words, all on the same level of contrast (e.g., not including the term for the superordinate category), that refer to a single conceptual category, such as kinship terms, color terms, names of animals, or emotion terms (8). The structure of a semantic domain derived from judged-similarity tasks is defined as the arrangement of the terms relative to each other represented in Euclidean space. The interpretation of this spatial representation rests upon the fact that in this space terms that are judged more similar are closer to each other than terms that are judged less similar. A semantic structure provides an ideal model system for the study of this aspect of culture.
It is assumed that each individual has an internal cognitive representation of the semantic structure in which the meaning of a term is defined by its location relative to all the other terms. We deal with the aspect of culture that consists of shared cognitive representations of this structure (8, 9). Our aim is to measure the extent to which members of different cultures, speaking unrelated languages, share cognitive representations of the domain of emotion terms. The data reported in the following sections all derive from a study by C.D.R. (10).
Choice of Emotion Terms
An initial and critical step in comparing the semantic structures in English and Japanese is to define the domain and get an idea of its extent. The most objective method for obtaining a representative sample is separately eliciting free lists of emotion terms from monolingual speakers of each language (11). This method ensures that the list of emotion terms comes from native speakers unbiased by the researchers’ theoretical proclivities. Items that are listed by the majority of subjects are generally better known and clearly have more cultural salience than items listed by only a few (12).
The lengths of the free lists obtained from samples of monolingual subjects in English in the United States (n = 52) and in Japanese in Japan (n = 53) are comparable and range from 9 to 55 with a mean of 24.18 words (SD = 8.60). The task produced far more terms in both languages than it is practical to analyze, 415 in English and 384 in Japanese. To obtain our final sample of 15 terms, the items in each language list were ranked in terms of frequency of occurrence in the free-listing task. The Japanese terms were then subjected to translation procedures. Reasonable translations were available for all frequently mentioned terms and no term was eliminated because of translation difficulties. The final sample was based on the criterion of frequency and included all terms that were mentioned at least six times in both the English and Japanese free-listing task.
The final list in English alphabetic order with the corresponding
Japanese term in italics and the Japanese character used in
the questionnaires in parentheses is as follows: anger,
haragatatsu (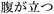 ); anguish, kurushii
(
); anguish, kurushii
(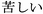 ); anxious, fuan (
); anxious, fuan (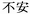 ); bored,
tsumaranai (
); bored,
tsumaranai (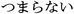 ); disgust, mukatsuku
(
); disgust, mukatsuku
( ); envy, urayamashi (
); envy, urayamashi (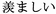 );
excitement, dokidokisuru (
);
excitement, dokidokisuru (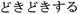 ); fear,
osoroshii (
); fear,
osoroshii (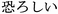 ); happy, ureshii
(
); happy, ureshii
(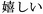 ); hate, kirai (
); hate, kirai (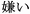 ); lonely,
sabishii (
); lonely,
sabishii (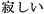 ); love, itoshii
(
); love, itoshii
(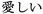 ); sad, kanashii (
); sad, kanashii (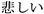 ); shame,
hazukashii (
); shame,
hazukashii (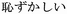 ); and tired, tsukareta
(
); and tired, tsukareta
(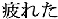 ). Because we took words from the free lists, not
every word has the same linguistic construction. The English
terms are mostly nouns and the Japanese terms are mostly adjectives.
). Because we took words from the free lists, not
every word has the same linguistic construction. The English
terms are mostly nouns and the Japanese terms are mostly adjectives.
Scaling Semantic Structures
The judged-similarity data were collected from three samples of subjects: a monolingual English-speaking group of 33 undergraduate students in Irvine, CA, a monolingual Japanese-speaking group of 32 undergraduate students from a university in Toyama, Japan, and a group of 17 bilingual Japanese students (fluent in speaking and reading English as a second language) from Toyama, Japan.
Two independent sets of data on judged similarities were collected using two different tasks, namely, a triads task and a paired-comparison rating task on a 5-point scale. The triads questionnaire consisted of 105 triads of the 15 emotion terms. The task was to pick, for each triad, the term most different in meaning from the other two (11). A lambda-three balanced incomplete block design (13) in which every pair of terms occurred exactly three times was used. Each subject received a different randomly chosen set of triads. The paired-comparison rating task presented each subject with all of the 105 possible pairs of emotion words. The task was to rate the word pairs in terms of how similar they were on a scale of 1 (most dissimilar) to 5 (most similar) (11). The numerals from 1 to 5 were printed on the questionnaire, and the subject marked the appropriate answer on a Scantron card for automated data entry. For both tasks the order of presentation of items and questions was individually randomized for each subject.
Each monolingual subject filled out two questionnaires, one for triads and one for paired-comparisons, in the appropriate language. The bilingual subjects filled out four questionnaires each, performing both tasks in both languages. The data for each subject and task were coded in a series of 15 × 15 symmetric matrices with the rows and columns labeled by the emotion terms, all in the same English alphabetic order. Each matrix contained the raw similarity judgments from a single task for a single individual. For each triad, one point was placed in the cell representing the pair of words remaining after the subject had chosen the word most different in meaning from the other two. If, for example, in the triad of happy, love, bored, the subject had circled bored as most different in meaning, then one point of similarity was entered for the pair happy–love in the cell representing the intersection of happy and love.
To obtain the semantic structure for all tasks and subjects, the data were stacked into a single matrix, and a correspondence analysis was performed on that matrix (8, 9, 14). Because correspondence analysis assumes similarity data, a “3” was placed on the diagonal of each matrix derived from triads and a “5” was placed on the diagonal of each matrix derived from the paired-comparison task. This treatment of the diagonal values rests on the assumption that each emotion term is maximally similar in meaning to itself (14). The stacked matrix contained 198 matrices, each representing the similarity structure of a specific task for a specific subject: two tasks each for 33 monolingual English-speaking subjects, i.e., 66; two tasks each for 32 monolingual Japanese-speaking subjects, i.e., 64; and four tasks each (two tasks in each language) for 17 bilingual Japanese subjects, i.e., 68. Because each matrix contained 15 terms, the total matrix had 2,970 (15 × 198) rows and 15 columns (one for each emotion term).
Correspondence analysis of the stacked matrix produced a multidimensional scaling representation of the data. The analysis is standard and can be found in any conventional treatment of correspondence analysis (14, 15). The optimal scores from correspondence analysis may produce different size representations for different tasks and individuals. These differences in scale (size) are artifacts of differences of variance among subjects or tasks and have no substantive interpretation. To avoid these size differences, the optimal row scores for each dimension and each subject were standardized to a mean of zero and variance equal to the square root of the singular values. This procedure has previously been used in a study of biases in social perception and in studies of the scaling of other semantic domains (8, 9, 14).
The first five singular values (including the trivial) were 1.00, 0.36, 0.24, 0.21, and 0.18. The trivial dimension accounted for 32% of the variance, whereas the next two dimensions accounted for 28% of the remaining variance. Because the majority of the interpretable effects were found here, results are presented only for the first two nontrivial dimensions. The two-dimensional plot of all 2,970 scores forms an incomprehensible cloud of points, but by judicious choice of subsets of points to plot, selected aspects of the data can be summarized and contrasted.
Fig. 1 presents an overall view of the semantic structure of emotion terms across all subjects and tasks. In this spatial representation, emotion terms that are judged more similar are closer to each other than terms that are judged less similar. Thus, for example, anger and hate are very similar (close) to each other and quite dissimilar (distant) from happy. The figure represents a model of a common shared semantic structure derived from all subjects, both English-speaking and Japanese-speaking. The ellipses in this and subsequent figures represent 97.5% confidence limits on the mean scores for each term. The confidence ellipses are estimated from all 198 locations of each term under a bivariate normal assumption, and they give a visual idea of the degree of resolution of the methods. The area of the confidence ellipses is a function of both variability in the measures and the number of cases involved. The fact that the ellipses are based on 198 scores accounts in large part for their small size. In subsequent plots, larger ellipses are a function of the comparison of subgroups with smaller sample sizes.
Figure 1.

The shared model of the semantic structure of emotion terms for English and Japanese. The ellipses represent 97.5% confidence regions of the mean position for each term.
The difference between the two methods of measuring semantic structure, triads and paired-comparison ratings, is examined for monolingual subjects only. A two-way analysis of variance on task and language, computed separately for each term, shows no significant differences due to task. This provides very strong evidence that our measures are reliable and that we are justified in merging data from the two tasks in subsequent analyses.
Fig. 2 shows the critical comparison between the two culture-specific models of the semantic structures for emotion terms in English and Japanese. The comparison includes monolingual subjects only, although both tasks are included. The labels are nearest the English terms, represented by thick ellipses. The confidence level of the ellipses is chosen so that two terms are significantly different if the two ellipses do not touch, taking into account Bonferroni’s correction for multiple tests (16). The farther apart the ellipses are, the greater the differences in the judgments of the English-speaking and Japanese-speaking subjects. The interpretation of Dimension 1 corresponds to what Osgood (4, 5) called the Evaluative Factor, “represented by scales such as good–bad, pleasant–unpleasant, and positive–negative,” whereas Dimension 2 corresponds to his Activity Factor, “represented by scales such as fast–slow, active–passive, and excitable–calm.” The first dimension goes from unpleasant on the left to pleasant on the right, whereas the second dimension goes from passive at the bottom to active at the top.
Figure 2.

A comparison of two culture-specific models of the semantic structure of emotion terms—English (thick ellipses) and Japanese (thin ellipses)—based on monolingual subjects only.
The global configurations of the two language groups are very similar, although significant differences are measurable in 11 of the 15 emotion terms. Few of these appear large enough to be of practical importance. For example, even though the English terms for disgust, hate, and anger are all statistically significantly different from their Japanese counterparts, the observed difference is quite small and does not change the overall configuration. Three of the terms, however, show much greater differences in position and may be interpreted to have practical consequences. The measured location of the English word shame is more extreme on the unpleasant dimension than that of the Japanese counterpart hazukashii. We think that this difference reflects a genuine difference in the meanings of the two words rather than being an accident of measurement or sampling variability. Subsequent to the analysis of the data, we asked two Japanese-speaking colleagues to translate the Kanji and Hiragana for hazukashii into English, and both of them gave shame and embarrassed as translations. Our intuition is that embarrassed is closer in meaning to hazukashii than shame. One of the strengths of the method is that this conjecture could be empirically tested in a new study.
Other terms that show quite large differences are anxious and bored. Our colleagues translated the Kanji for fuan as uneasy as well as anxious. The Japanese word is both more unpleasant and more passive than the English concept. The Japanese translation for bored, tsumaranai, is more active than the English word.
Shape Comparisons Between Monolingual and Bilingual Subjects
Another way of understanding the similarities and differences among the three samples in the study is to compare subjects in terms of the “shapes” of their Euclidean representation of semantic structure of emotion terms. The approach derives from recent advances in morphometrics, the quantitative study of biological shape variation based on landmark data (17, 18). A typical question posed by researchers in morphometrics would be whether, during the developmental process from birth to adulthood, the skull changes in shape in addition to just getting larger. They would begin with the measurement of selected landmarks, for example, points at which certain sutures meet in the skull, given as coordinates in some low-dimensional Euclidean space. Our method follows Rao and Suryawanshi’s (17) suggestion that information on the shape of an object be encoded in terms of logarithms of the k(k − 1)/2 Euclidean distances between all possible pairs of landmarks. In our data the locations of emotion terms in the spatial configuration are equivalent to the landmarks used in morphometrics. The Euclidean distances for each subject and task may be computed from the row score coordinates reported earlier. This results in a 15 × 15 symmetric matrix of Euclidean distances (computed in four dimensions) among the 15 emotion terms for each subject and task combination. The upper half (above the diagonal) of the matrix is written as a vector, and, following Rao and Suryawanshi (17), the natural logarithms of the individual components of the distance vector are taken.
From this stage on we prefer to use correspondence analysis rather than morphometric methods. Following procedures outlined in previous publications (11, 14), we transform the vector of logged Euclidean distances into a similarity measure appropriate for correspondence analysis by subtracting each individual component of the logged distance vector from a number larger (five times in this case) than the largest value in the vector. The result is a matrix with 198 rows, one for each combination of subject and task in the study, and 105 columns, the vector of k(k − 1)/2 similarities among the 15 emotion terms.
Correspondence analysis of this matrix results in optimal row scores that represent the similarity among subjects in terms of the shape of their configurations; that is, it represents the similarities among the profiles of the vectors derived from Euclidean distances. In correspondence analysis, two vectors that differ by any multiplicative constant receive identical row scores. Thus optimal row scores reflect overall similarities based exclusively on shape. This property accounts for our choice of correspondence analysis.
The first three singular values, including the trivial, of the correspondence analysis were 1.00, 0.011, and 0.009. The trivial singular value contained 85.6% of the total variance. Of the remaining variance, the second two singular values accounted for only 11.9%. The bulk of the information represented by the trivial singular value represents agreement among subjects and is analyzed in the next section. The striking results reported here are based on only a tiny proportion of the total effects.
The first shape comparison we examine is that between the monolingual English-speaking subjects and the monolingual Japanese-speaking subjects. A plot of the first two nontrivial dimensions in Fig. 3 shows that the English-speaking subjects are clearly distinguished from the Japanese-speaking subjects. (Each subject appears twice, once for the triads task and once for the paired-comparison task.) As would be expected from the figure, the significance level is beyond the 0.001 level for both dimensions. Task differences are not a significant factor. A discriminant analysis in two dimensions correctly classifies 121 of the 130 points in the figure.
Figure 3.

A comparison of shape similarity for the two data collection tasks among monolingual English-speaking subjects (□) and monolingual Japanese-speaking subjects (•).
To compare performance on tasks in English and Japanese for the bilingual subjects we treat, for a given task, individual subjects as their own controls and use a matched-pair t test. For the paired-comparison task, the matched-pair t test gives t = −5.06, which is significant beyond the 0.001 level in the first dimension. The same comparison for the Japanese bilinguals on the triads test gives t = −3.17, which is significant at the 0.006 level in the first dimension.
Fig. 4 shows the comparison between the mean locations of the monolingual groups (i.e., the individuals in Fig. 3) with the mean locations of the bilingual subjects performing in Japanese and English. Ignoring the ellipse for the bilingual responses in English, the remaining three ellipses are independent samples. Thus the three thick ellipses in Fig. 4 are appropriate comparisons for statistical inferences. The bilingual group responding in English is shown (thin ellipse) only to indicate its location, and even though the ellipses overlap, the differences are significant (t tests reported above). The responses of the bilinguals responding in Japanese are in the same location as those of the monolingual Japanese, as they should be if the measurements are based on reasonable representative samples. The bilingual group, when responding in English, is about a third of the way toward the English monolinguals in overall shape. It is apparent that these subjects have learned many but not all of the nuances of the configuration of English emotion terms in their acquisition of a second language.
Figure 4.

A comparison of shape similarity between monolingual groups (summary of data in Fig. 3) and the bilingual Japanese performing in Japanese and English (across both tasks). Ellipses are 97.5% confidence regions of the mean; the thin ellipse is not a legitimate comparison group (see text).
How Widely Shared Is Semantic Structure of Emotion Terms?
Different portions of the semantic structure of emotion terms for our 130 monolingual subjects may be resolved into (i) a portion shared by all subjects, both English-speaking and Japanese-speaking, (ii) a portion shared only with subjects speaking the same language, English or Japanese, (iii) a portion that is unique to each subject, and (iv) a residual portion due to sampling variability and measurement error.
Estimates of the degree of sharing for each of these portions may be obtained by examining appropriate nested subsets of correlations among subjects as outlined below. The analysis is based exclusively upon the monolingual subjects and includes data from both the triads and the paired-comparison tasks. Thus the data consist of 130 rows, each containing the 105 transformed scaled interpoint similarities (obtained in the last section) among the 15 emotion terms for each subject for each task. The subject-by-subject matrix of correlations derived from this data represent the degree of semantic structure similarity among all individuals in the sample.
An approximate estimate of the degree of sharing characterizing the various portions of semantic structure may be obtained by making a few assumptions that are widely used in psychometrics (19) and trace back to Spearman’s work nearly 100 years ago (20). The first assumption is that all the correlations among subjects are positive (which is true for these data). The second assumption is that the average correlation among a set of subjects indicates the extent to which a common shared pattern exists. The third assumption is that the correlation between two subjects is the product of the correlation of each subject with the relevant shared cultural pattern. Given these assumptions, it follows that the square root of the average correlation is an approximation of the average correlation of each subject with the shared pattern (19, 21). Note that if there were perfect sharing with no measurement error, every individual would correlate 1.00 with every other individual in sample.
To determine the portion of sharing of a pattern common to all 130 English and Japanese subjects, we find that the mean of the 8,385 relevant correlations is 0.43 (SD = 0.19). The square root of 0.43 is 0.66, which is the approximate correlation of the average subject with the common shared model derived from both English and Japanese. To a very close approximation, these procedures are equivalent to the average loading that would result from a principal component analysis (0.66 in this case), the natural method to apply with complete correlation matrices (22). Because the individual effects are not derived from complete correlation matrices, we use the approximate methods.
A nested subset of correlations, within the shared set just considered, is composed of correlations comparing speakers of the same language, i.e., within either English speakers or Japanese speakers. The mean of the 4,161 relevant correlations is 0.52 (SD = 0.18). The square root of 0.52 is 0.72, which is the approximate correlation of the average subject with a pattern shared with speakers of the same language. Thus the portion shared only among speakers of the same language results in an increment of 0.06 for the culture-specific models, quite small compared with the shared model based on both languages.
A final nested subset of correlations is obtained by correlating, for each subject, the performance on the triads and paired-comparison tasks. This enables us to make an ad hoc estimate of the unique portion of semantic structure held by each individual. Over all 65 individuals, the average correlation is 0.66 (SD = 0.15) with a square root of 0.81, an increment of 0.09 over the language-specific estimate. Finally, a residual of 0.19 consists of sampling variability and measurement error. The pie chart in Fig. 5 shows the contribution of the various portions of shared knowledge to the total inventory of cultural knowledge.
Figure 5.

Contributions to semantic structure from four sources: common shared model, culture-specific models, individual component, and residual sampling and error variance.
Discussion and Implications
A large part of our motivation to measure the shared agreement between English and Japanese emotion terms was to present a method for the visualization of the reality of a semantic structure as a step toward the comparison of cultures. The results indicate that individuals who speak English or Japanese share to a very large extent internal cognitive representations of the semantic structure of emotion terms. The methods are applicable not only to any semantic domain in any language but also to a variety of other comparisons.
If our results generalize to other cultures, and it is found that the semantic structure of emotion terms is widely shared, they will have potentially important theoretical implications. The findings both reinforce, and are reinforced by, developments in the field of evolutionary psychology (23) and other recent work on human cognitive evolution (24) that suggest that the underlying emotions are common to all humans. The existence of such a set of emotions would provide an obvious explanation for various languages developing similar semantic structures in response to a common underlying reality (23, 25).
The idea that Japan might have a semantic structure similar to the United States because it has been Westernized does not stand up to close scrutiny. For example, in Hofstede’s 40-nation survey on work-related value dimensions, Japan was “most different” from any other country (26). In an unrelated study of human values in 9 countries, it was also Japan that occupied “an extremely distinct position in the lower right quadrant all by itself” (27).
What is particularly impressive about the present findings is the extent to which they are consistent with previous research traditions that posit cultural and semantic universals. For example, the extensive research on emotions and facial expressions of emotion by Ekman (2, 3) and his colleagues clearly rests upon an assumption that the semantic structure of emotion terms is, to a large extent, universally shared. Russell (28) has presented a major quantitative critique of the findings of Ekman and his colleagues, and our results are relevant to the evaluation of that critique. In this study, we were able to obtain a global view of the relative magnitude of the effects studied. We found that a very small proportion of the total effect, namely, shape, could reliably distinguish English-speaking from Japanese-speaking monolingual subjects. Despite this highly statistically significant finding, the overall results favored the shared aspects of semantic structure over culture-specific aspects. Looking only at the differences, one might have concluded that, because they were significant, the common shared aspects were insignificant. This is precisely the reasoning used by Russell.
The work of Berlin and Kay (6) also had a profound impact on the widespread controversy in the behavioral sciences concerning the universality of the semantic structure of domains such as colors, animals, and emotion terms. Before their work, anthropologists assumed that each language classified colors in a unique and idiosyncratic manner. The idea that the semantic structure of color is subject to universal constraints is now clearly established.
Finally, Herrmann and Raybeck (7) published a remarkable cross-cultural comparison of six language groups in 1981. They represented each language with a single structure derived from aggregated data and reported that “the median interculture correlation for emotions was .701” (ref. 7, pp. 201–202). Assuming that the mean is the same as the median, this may be interpreted as equivalent to each language sharing 85% of a common semantic structure, an even larger shared component than reported here.
Acknowledgments
We acknowledge helpful comments on the manuscript by Michael L. Burton, Tarow Indow, R. Duncan Luce, and Robert L. Munroe. The research was supported in part by National Science Foundation Grant SES-9210009 to A.K.R. and W. H. Batchelder.
References
- 1.Greenberg J H, Ferguson C A, Moravcsik E, editors. Universals of Human Language. Palo Alto, CA: Stanford Univ. Press; 1978. , Vols. 1–4. [Google Scholar]
- 2.Ekman P. Psychol Sci. 1992;3:34–38. [Google Scholar]
- 3.Ekman P, Friesen W V. Unmasking the Face: A Guide to Recognizing Emotions from Facial Clues. Englewood Cliffs, NJ: Prentice–Hall; 1975. [Google Scholar]
- 4.Osgood C E, Suci G G, Tannenbaum P H. The Measurement of Meaning. Urbana, IL: Univ. Illinois Press; 1957. [Google Scholar]
- 5.Osgood C E. Am Anthropol. 1964;66:171–200. [Google Scholar]
- 6.Berlin B, Kay P. Basic Color Terms: Their Universality and Evolution. 2nd Ed. Berkeley, CA: Univ. California Press; 1991. [Google Scholar]
- 7.Herrmann D J, Raybeck D. J Cross-Cult Psychol. 1981;12:194–206. [Google Scholar]
- 8.Romney A K, Boyd J P, Moore C C, Batchelder W H, Brazill T J. Proc Natl Acad Sci USA. 1996;93:4699–4705. doi: 10.1073/pnas.93.10.4699. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Romney A K, Batchelder W H, Brazill T J. In: Geometric Representations of Perceptual Phenomena. Luce R D, D’Zmura M, Hoffman D, Iverson G J, Romney A K, editors. Mahwah, NJ: Lawrence Erlbaum; 1995. pp. 267–294. [Google Scholar]
- 10.Rusch, C. D. (1996) Ph.D. dissertation (Univ. California, Irvine, CA).
- 11.Weller S C, Romney A K. Systematic Data Collection. Newbury Park, CA: Sage; 1988. [Google Scholar]
- 12.Romney A K, D’Andrade R G. Am Anthropol. 1964;66:146–170. [Google Scholar]
- 13.Burton M L, Nerlove S B. Soc Sci Res. 1976;5:247–267. [Google Scholar]
- 14.Romney A K, Moore C C, Brazill T J. In: Visualization of Categorical Data. Greenacre M, Blasius J, editors. San Diego: Academic; 1997. , in press. [Google Scholar]
- 15.Weller S C, Romney A K. Metric Scaling: Correspondence Analysis. Newbury Park, CA: Sage; 1990. [Google Scholar]
- 16.Wilkinson L. systat: The System for Statistics. Evanston, IL: SYSTAT; 1989. p. 64. [Google Scholar]
- 17.Rao C R, Suryawanshi S. Proc Natl Acad Sci USA. 1996;93:12132–12136. doi: 10.1073/pnas.93.22.12132. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Bookstein F L. Bull Math Biol. 1996;58:313–365. doi: 10.1007/BF02458311. [DOI] [PubMed] [Google Scholar]
- 19.Nunnally J C. Psychometric Theory. New York: McGraw–Hill; 1978. pp. 175–205. [Google Scholar]
- 20.Spearman C. Am J Psychol. 1904;15:201–293. [Google Scholar]
- 21.Romney A K. J Quant Anthropol. 1989;1:153–223. [Google Scholar]
- 22.Jackson J E. A User’s Guide to Principal Components. New York: Wiley; 1991. [Google Scholar]
- 23.Barkow J H, Cosmides L, Tooby J. The Adapted Mind. New York: Oxford Univ. Press; 1992. [Google Scholar]
- 24.Donald M. Origins of the Modern Mind: Three Stages in the Evolution of Culture and Cognition. Cambridge, MA: Harvard Univ. Press; 1991. [Google Scholar]
- 25.Searle J R. The Construction of Social Reality. New York: Free Press; 1995. [Google Scholar]
- 26.Hofstede G. In: Diversity and Unity in Cross-Cultural Psychology. Rath R, Asthana H S, Sinha D, Sinha J B H, editors. Lisse, The Netherlands: Swets and Zeitlinger; 1982. pp. 173–187. [Google Scholar]
- 27.Ng S H. In: Diversity and Unity in Cross-Cultural Psychology. Rath R, Asthana H S, Sinha D, Sinha J B H, editors. Lisse, The Netherlands: Swets and Zeitlinger; 1982. p. 201. [Google Scholar]
- 28.Russell J A. Psychol Bull. 1994;115:102–141. doi: 10.1037/0033-2909.115.1.102. [DOI] [PubMed] [Google Scholar]