
Figure 3.
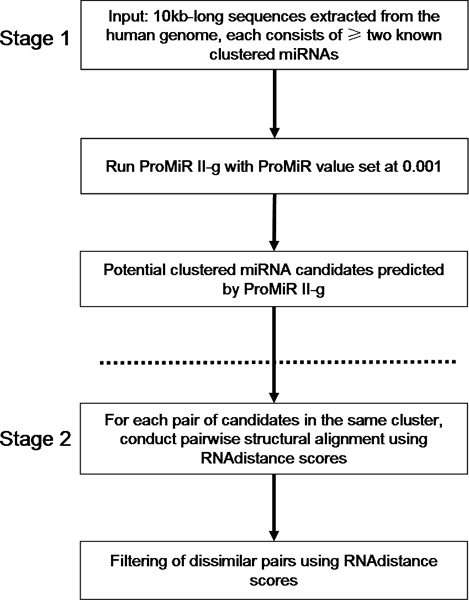
Overview of the clustering-based approach. In principle, our clustering-based approach consists of two stages. In stage 1, a currently available prediction program, for example ProMirII-g, is selected to produce a list of potential candidates. A loose threshold is used because we want to include as many TPs as possible to achieve a high SE. In stage 2, we aim at filtering the FPs from the list of candidates by picking out the dissimilar pairs as determined by the RNAdistance scores.