
Fig. 7.
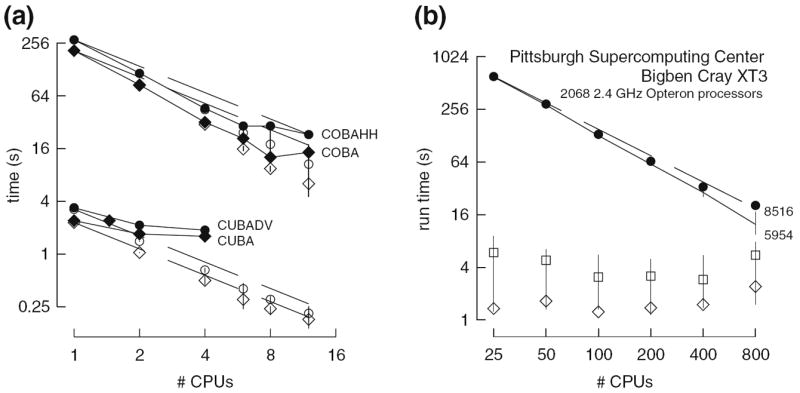
Parallel simulations using NEURON. (a) Four benchmark network models were simulated on 1, 2, 4, 6, 8, and 12 CPUs of a Beowulf cluster (6 nodes, dual CPU, 64-bit 3.2 GHz Intel Xeon with 1024 KB cache). Dashed lines indicate “ideal speedup” (run time inversely proportional to number of CPUs). Solid symbols are run time, open symbols are average computation time per CPU, and vertical bars indicate variation of computation time. The CUBA and CUBADV models execute so quickly that little is gained by parallelizing them. The CUBA model is faster than the more efficient CUBADV because the latter generates twice as many spikes (spike counts are COBAHH 92,219, COBA 62,349, CUBADV 39,280, CUBA 15,371). (b) The Pittsburgh Supercomputing Center’s Cray XT3 (2.4 GHz Opteron processors) was used to simulate a NEURON implementation of the thalamocortical network model of Traub et al. (2005). This model has 3,560 cells in 14 types, 3,500 gap junctions, 5,596,810 equations, and 1,122,520 connections and synapses, and 100 ms of model time it generates 73,465 spikes and 19,844,187 delivered spikes. The dashed line indicates “ideal speedup” and solid circles are the actual run times. The solid black line is the average computation time, and the intersecting vertical lines mark the range of computation times for each CPU. Neither the number of cell classes nor the number of cells in each class were multiples of the number of processors, so load balance was not perfect. When 800 CPUs were used, the number of equations per CPU ranged from 5954 to 8516. Open diamonds are average spike exchange times. Open squares mark average voltage exchange times for the gap junctions, which must be done at every time step; these lie on vertical bars that indicate the range of voltage exchange times. This range is large primarily because of synchronization time due to computation time variation across CPUs. The minimum value is the actual exchange time