
Figure 7.

The relationship between the pseudocount proportion α implied by the MDL principle and column relative entropy. Each point represents a multiple alignment column constructed by PSI-BLAST from the aravind103 query set (18,33) run against SWISS-PROT (34). Only columns with 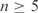 independent observations are considered. The x-axis represents the relative entropy D(f′ || p), where f′ is the observed frequency vector of the column after the addition of m0 = 5.5 pseudocounts, and p is the background amino acid frequency vector implicit in BLOSUM-62. The y-axis represents the pseudocount proportion α calculated from the MDL theory. The upper diagonal line (shown in red) represents the best power-law fit to the data. The lower diagonal line (shown in green) represents the power-law relationship of α to D(f′ || p) that empirically yields the optimal retrieval on the training set. Note that the background frequency vector p is the fixed point of the linear transformation M. Therefore, if f′= p, the increase in the description length of the data is identically zero for all α, implying that the MDL is optimized at
independent observations are considered. The x-axis represents the relative entropy D(f′ || p), where f′ is the observed frequency vector of the column after the addition of m0 = 5.5 pseudocounts, and p is the background amino acid frequency vector implicit in BLOSUM-62. The y-axis represents the pseudocount proportion α calculated from the MDL theory. The upper diagonal line (shown in red) represents the best power-law fit to the data. The lower diagonal line (shown in green) represents the power-law relationship of α to D(f′ || p) that empirically yields the optimal retrieval on the training set. Note that the background frequency vector p is the fixed point of the linear transformation M. Therefore, if f′= p, the increase in the description length of the data is identically zero for all α, implying that the MDL is optimized at  . For any finite n, vectors f′ close enough to p also imply an optimal α of 1. A small number of such points are seen at the upper left of this graph.
. For any finite n, vectors f′ close enough to p also imply an optimal α of 1. A small number of such points are seen at the upper left of this graph.