
Figure 1.
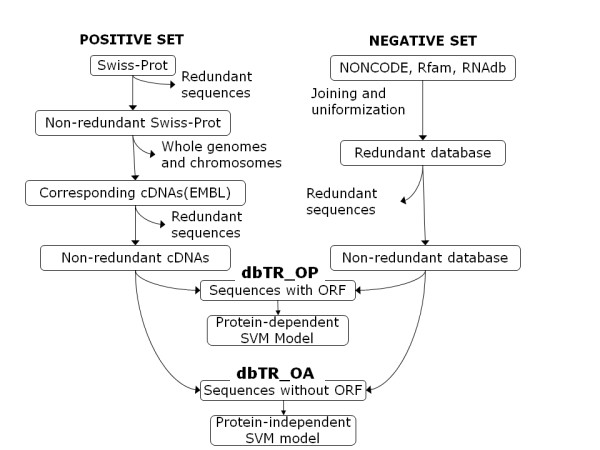
Construction of the training database (dbTR). The dbTR comprises both negative and positive instances, and was subdivided as transcripts having identified ORFs (dbTR_OP) and transcripts lacking ORFs (dbTR_OA). Each of these subsets harbor their own negative and positive instances. dbTR_OP training subset was used to induce the protein-dependent SVM model, while dbTR_OA training subset generated the protein-independent SVM model.