

Abstract
The current state of the art in applied decomposition techniques is summarized within a comparative uniform framework. These techniques are classified by the parametric or information theoretic approaches they adopt. An underlying structural model common to all parametric approaches is outlined. The nature and premises of a typical information theoretic approach are stressed. Some possible application patterns for an information theoretic approach are illustrated. Composition is distinguished from decomposition by pointing out that the former is not a simple reversal of the latter. From the standpoint of application to complex systems, a general evaluation is provided.
Keywords: Bipartite network, Blind source separation, Complexity, Composition, Entropy, Independent component analysis, Information, Information transfer, Integration, Mutual information, Negentropy, Network component analysis, Principal component analysis, Singular value decomposition
Introduction
Decomposition is a process of breaking up into constituent elements. In mathematical analysis, it means factorization and/or finding summands of a real number or a matrix. In systems science, decomposition consists of finding an optimal partition of a system in terms of its subsystems. Decompositions in real-life applications are motivated by a need to obtain a much simpler body of constituents that can best represent a given system of unmanageable size and/or complex structure. Complexity is a lack of information about a system, and unmanageable size means high dimensionality (Donoho, 2000; Fan and Li, 2006). Optimality of decomposition is evaluated by means of some adopted criteria, such as a dispersion measure of observables (for instance, higher eigenvalues or singular values of covariance matrix) or their conformity with prior knowledge on network structure or an entropic measure (information content) involved, etc.
Here we aim to discuss the current state of the art in decomposition within a uniform framework of approach. We do not intend this to be a full-fledged survey. For illustrations and examples on some known techniques, readers will be referred elsewhere. Because decomposition has a vast spectrum of application areas, finding a common framework of interest to all is challenging. The case is the same with determining the type of audience to be addressed. We have chosen a general statistical and information theoretic framework without dwelling on specifics of a certain area, for example, technicalities of statistical inference issues relating to the models discussed. Apart from taking care to introduce a conceptual framework for decomposition on the basis of partitions and except for the two illustrations provided on applications of the last technique and our efforts to find a common framework for exposition, we do not claim originality:
A close study of the relevant literature has led us to conclude that applications of decomposition and relevant techniques fit into two categories of approaches: The first category handles the problem in terms of a structural formal model representing the real-world phenomenon to be considered. The second category uses information theoretic treatment of systems without specifying such a structure. The first four well-known techniques to be discussed can be placed within the first category and are also used for dimension reduction: principal component analysis (PCA), singular value decomposition (SVD), independent component analysis (ICA), and network component analysis (NCA). The final technique, which may be called decomposition with information transfer function (ITF), falls in the second category. Although it is one of the earliest approaches found in literature, ITF is little known and the least explored. In the exposition below, both random vectors and matrices are shown in bold uppercase letters whereas bold italic uppercase letters are used for random vectors only. The superscript t stands for transposition.
A common framework of structure for the first category of techniques can be set up in terms of a linear model such as
| (1) |
In information theory, for instance, this model represents a simple formal communication channel without encoding and decoding (Ash, 1990, Chapter I). The model (1) will shortly be expressed as
The column vector X = (X1, X2,…, Xn)t of the model (1) has n observable random variables X1, X2,…, Xn such as phenotypes in biology. The coordinates of the column vector Z stand for m non-observable random factors Z1, Z2,…, Zm, with n ≤ m, where m denotes the number of arrays into which these latent factors (say, genotypes in the case of the given biological example) can be placed. The (n×1) vector E contains n unobserved residuals E1, E2,…, En, which are sometimes called noise factors. When E1, E2,…, En are missing in the model, i.e., when E=0, (1) becomes a noise-free or noiseless model. Setting Y = AZ and having hence X = Y + E for (1), one easily obtains an initial decomposition {Y, E} of X underlying the model (1). The assumption behind the decomposition {Y, E} is that these two vectors or factors have additive (independent or at least orthogonal) effects on X. Y = AZ is a linear approximation to any differentiable non-linear function (correspondence) Y = Ψ(Z) at a certain point of Z. The general setup (1) outlined above is different from the classical multivariate regression model. In the multivariate regression model, the matrix A is observable and the vector Z is unobservable. Furthermore, under the regression model, the noise vector E cannot obviously be neglected.
The vectors Z and X are related to each other though an unknown mixing matrix A, the rows of which correspond to the coordinates of X, i.e., phenotypes in biology, and the columns correspond to the elements of Z. In physical terms, matrix A stands for a system or a network (i.e., gates) through which, for example, genotypes or similar latent factors are connected to phenotypes or observable outputs. Often, these matrices give some idea about the underlying structure of a system. Such matrices are sometimes given special names like design structure matrices, dependency structure matrices, problem solving matrices, or design precedence matrices (Browning, 2001). In fact, a lower triangular matrix A corresponds to a hierarchical structure and diagonal or block diagonal matrices indicate independence or block-wise independence of components. Generally, matrix cells contain real or complex numbers. In a bipartite network system (e.g., a network between two different groups such as the phenotypes and genotypes in our biology example), however, they are composed of non-negative integers only. Irrespective of their numerical nature, estimation of or information on such matrices becomes of utmost importance for the study of complex systems.
The main statistical problem tackled by the structural approach in (1) is thus to obtain a statistically significant estimate of the matrix A and hence the vector Z by using the information contained in the observable X. In the statistical identification and estimation of matrix A, vector X is assumed generally to have a statistical distribution with non-spherical contours on its domain (e.g., if the variance-covariance matrix of a multivariate normal distribution has distinct eigenvalues, the corresponding probability density function traces ellipsoids in its domain whereas a covariance matrix with identical eigenvalues produces spheroids in its domain). PCA and SVD are basically designed for distributions with non-spherical contours; ICA works well with non-normal distributions. Furthermore, normal distributions have maximum entropy among other distributions with an identical mean and variance and therefore are inappropriate for entropic analyses that seek minimum entropy.
The first four techniques to be discussed below aim at obtaining matrix A from parameters of relevant distributions or at estimating it in terms of some observational phenomena. For the purpose of estimation, some finite number of observations like X1, X2,…, XN, n < N, on X are obtained. The condition n < N is obviously required for non-singularity. Hence, ignoring the corresponding residual vectors E1, E2,…, EN for the corresponding vectors Z1, Z2,…, ZN for the time being, we have the observational phenomenon
| (2) |
In matrix notation, (2) can be re-expressed as
| (3) |
The matrix X corresponds to a set of N observations on n genes, for instance. The objective for the first four techniques is to obtain an estimate of the unknown structure matrix A by means of the observable X and hence to obtain information on Z with the model (2).
As mentioned earlier, ITF does not involve such a structure as (1) above. Instead, an input process like the latent Z of the above discussion is assumed to be transformed to an output process like the observable Y (or X) above with the understanding that Z and Y (or X) may not necessarily obey vector space algebra or any other space algebra with certain topological properties. Both the input and the output of transformation are assumed to be stochastic. We denote a system with S ={X1, X2,…,Xn}, meaning that X1, X2,…,Xn are just components of the system; S does not represent a functional notation. As it is the case with a structural model as in (1), X1, X2,…,Xn usually correspond to output. Because we are interested in the nature of a system, this output feature of X1, X2,…,Xn is often overlooked. Further discussion on systems can be found in the treatment of ITF below. The objective of this final technique is thus to find a partition p{S1, S2, …,Sq}, q ≤ n (e.g., a set of exhaustive disjoint subsets S1, S2, …,Sq), that provides the same information as S.
Principal Component Analysis
Although the underlying mathematical tool of PCA is not new, its application to statistical problems and its subsequent independent development are attributed to Pearson (1901) and Hotelling (1933). This mathematical tool is known as spectral decomposition of nonsingular (positive- or negative-definite) symmetrical square matrices and is sometimes referred as the Hoteling or Karhunen-Loève transform. Because a variance-covariance of a random vector satisfies these square-symmetry and positive-definiteness properties, spectral decomposition can also apply to the variance-covariance matrix V(X) = Σ = ε(X− ε (X))(X− ε (X))t of the observable vector X in model (1) or its estimate Σ̂ obtained from observation matrix X in (2) in the usual way:
where l is an (N×1) sum vector, i.e., l =(1,1,…,1)t, and as pointed out above, we have the condition n < N for Σ̂ to be positive definite (Seber, 1984, p. 59). We shall henceforth deal with such positive-definite cases and shall refer to them as standard PCA. The symbol ^ above any character that denotes a parameter stands (conventionally) for the corresponding estimate.
Spectral decomposition of Σ or Σ̂ is then the factoring-out of these matrices such as
where Q is an n× n matrix with orthonormal columns Q1, Q2,…, Qn that are basically the eigenvectors of Σ, and Λ is a diagonal matrix with positive diagonal elements λ1, λ2,…, λn consisting of the corresponding eigenvalues. We also have similar matrices Q̂ and Λ̂ for Σ̂. In view of the orthonormality of Q1, Q2,…, Qn, the following obvious results are obtained:
| (4) |
The same results will obviously hold for its sample counterpart Q̂. The spectral decomposition of Σ can be re-expressed in the better known way as
| (5) |
The last equality shows that the variance-covariance matrix can also be decomposed as the sum of n matrices Σk= λk QkQkt, (k=1,2,…,n), which are orthogonal to each other so that ΣiΣj= 0 for i ≠ j. Obviously, the matrices Qk = Qk Qtk are idempotent (orthogonal projection) matrices because
| (6) |
The spectral decomposition Σ = QΛQt introduces further computational conveniences for inversion and squaring the variance-covariance matrix Σ, i.e.,
Parallel statements will be valid for the sample counterpart Σ̂ of Σ as well. (For other aspects of spectral decomposition of variance-covariance matrices, see Jolliffe, 2002).
Such decomposition has some implications in statistical applications for the case that n = m. In fact, when Σ or Σ̂ is known, and in consequence when Q or Q̂ can be obtained, we can replace the structure matrix A in (1) with Q or Q̂ to have X = QZ or X = Q̂ Ẑ, depending on the availability Q or Q̂, so that, because n = m, the unobserved Z
can be obtained. The variance-covariance matrix of Z is now given by matrix Λ, which contains eigenvalues of Σ on the diagonal, i.e.,
with the implication that the new transformed variables
are uncorrelated and have the respective eigenvalues of V(X) = Σ as their variances, i.e.,
Note that sums of the variances of Z1, Z2,…, Zn and X1, X2,…, Xn are identical:
From a geometric point of view, metric properties of both the transformed variables Z1, Z2,…, Zn and the original variables X1, X2,…, Xn are identical. For instance, |Z| =(XtQtQX)1/2= |X|, which means the vectors X and Z have identical lengths. Furthermore, inner products in both spaces are identical: XitXj = (QZi)t(QZj)= ZitQtQZj = ZitZj. Hence, both XitXj = ZitZj and |Z| = |X| imply that the pairs (Xi, Xj) and (Zi, Zj) have the same positions with respect to each other in both the original and transformed spaces because XitXj = cos θ × |Xi|×|Xj| and ZitZj = cos ρ×|Zi|×|Zj| result in θ = ρ. Similarly, the corresponding areas and volumes are identical in both spaces. Because multiplication from the left of the vector X by an orthogonal matrix Qt or multiplication of Z by the orthogonal Q yields rotations of these vectors, the original X and the transformed Z are but rotated vectors with all other metric properties being left intact (i.e., they are so-called rigid motions of each other). For that reason, PCA is sometimes presented as a simple rotation. All of the above discussion applies to sample counterparts that result from replacing A with Q̂ except, of course, for relevant statistical inferential issues.
If these eigenvalues are ranked as λ(n) ≤ λ(n−1) ≤…≤ λ(2) ≤ λ(1) and the corresponding eigenvectors Q(n), Q(n−1),…, Q(1) are ordered accordingly, then the uncorrelated transformed variables Z(n)= Qt(n)X, Z(n−1) = Qt(n−1)X,…, Z(1) = Qt(1)X can be ordered in terms of the magnitude of their variances. The same ordering also holds for the factorized matrices
which can be ordered in a decreasing fashion for k=1,2,…,n
Practically, this means that some reduction of dimension can be obtained on the basis of the magnitude of decomposed variances by cutting out small-ordered ones as negligible. For instance, the number of significant Z(i)’s can be restricted to the first k variables, k < n, satisfying for some predetermined δ level of variance. There are some inferential issues on determination of the number k of significant variables (Anderson, 1984, pp. 468–479).
The decomposition in (5) is sometimes referred to as eigen decomposition to distinguish it from other decompositions such as Cholesky decomposition, etc. (Anderson, 1984, p. 586; Press et. al., 1992). When matrices are defined over complex numbers, orthogonal matrices become unitary matrices and their transposes naturally are conjugate transposes of these matrices. Because the matrix Σ is symmetric, resulting eigenvalues will always be real.
The formal setup of the PCA analysis is based on a structural model such as the model (1) above. Therefore, its validity depends on the validity of the model as compared with the real phenomenon that it models. For instance, data that do not involve a location parameter and/or a scale factor are hardly suitable for a framework like (1). Also, as an alternative to a complex unmanageable system based on X1, X2,…, Xn, the analysis aims at obtaining some system based on variables Z1, Z2,…, Zk that are smaller in number (k < n), simpler in nature, and bear the same information (eigenvalues). However, this is achieved at the expense of orthogonality and/or un-correlatedness restrictions imposed on Z1, Z2,…, Zk. These impositions may not be realistic for some applications areas such as biological systems. Application of the technique is restricted to phenomena with distributions tracing non-spherical contours in their domains because little will be gained in the spherical case. Finally, the mathematical tool on which standard PCA is based applies to nonsingular decompositions, which requires that n = m in the model (1). Most real-life phenomena, however, seem to present a singular structure. The last restriction is alleviated by the next technique in the sequel: SVD. PCA does not seem to have lost its attractiveness despite prevailing high-dimensionality problems observed recently (Hastie et al., 2000). It is interesting further to note that PCA can be used for such a theoretical issue as construction of bivariate distributions (Gurrera, 2005). The use of Q̂ for A invites further inferential issues such as sampling distributions of eigenvalues and eigenvectors of Σ̂ (Anderson, 1984, pp.465–468, pp. 473–477, Chapter 13; Seber, 1984, pp. 35–38; Joliffe, 2002; Kendall, 1975, Chapter 2; Johnson and Wichern, 2002, Chapter 8).
Singular Value Decomposition
SVD is based on a matrix factorization technique that dates from the 19th century and was developed by several mathematicians in linear algebra and differential geometry (Stewart, 1993; Eckart. and Young, 1936). The technique warrants factorization of any real matrix in a way similar to spectral decomposition of square matrices. As such, given an (n×m) rectangular matrix C, SVD is actually a spectral decomposition of symmetric square positive semi-definite matrices CtC and CCt. For any (n×m) rectangular matrix C, the products CtC and CCt are known to be symmetric and positive semi-definite (Scheffe, 1959, p. 399) with real non-negative eigenvalues, and these products are thus suitable for spectral decomposition explained above in connection with PCA. Assume hence that an (n×m) matrix C is factored out the way that the matrix Σ is decomposed as in (5) above with Q now being represented by U when it is positioned on the left of the diagonal matrix and Qt by V when it is on the right:
| (7) |
where Ui ’s and Vi ’s are orthonormal columns of U and V, respectively, and D is diagonal with real nonnegative entries λi’s. The factorization (7) is sometimes interpreted as C being orthogonally (unitarily) equivalent or similar to the diagonal matrix D. There are various modes of SVD for the dimensions of the matrices involved. For instance, (i) the matrix U can be (n×n) with n orthonormal (unitary) columns Ui, called left singular (eigen array) vectors, and V is an (m×m) matrix with m orthonormal columns Vi, called right singular vectors (eigen genes in the biological example considered above) such that
D is an (n×r), r = min{n,m}, diagonal matrix with positive diagonal entries called singular values (eigen expressions) of C. (ii) A second mode corresponds to the case where the dimensions of the matrix U are (n×m) with n orthonormal left singular vectors and the (m×m) matrix V itself is orthogonal with m right singular vectors, such that
Hence, D becomes a (m×m) diagonal matrix with non-negative real singular values of C on its diagonal. The thin, compact, and truncated types of SVD are not discussed here because of space considerations.
To explain technicalities in SVD, we denote the real non-negative eigenvalues of the matrices CtC and CCt with κ1, κ2, …,κr with r being min{n,m}. Given the decomposition C = UDVt as in (7) with dimensions given for instance as in (i) above, we obtain
from which, by multiplication with V on the right, we have
| (8) |
Setting G= CtC and noting that V= [V1, V2, …, Vm] and D2 = diag (κ1, κ2, …, κr), (8) yields
which suggests that eigenvectors Vi of the matrix G = CtC are the right singular vectors of the matrix G, and the singular values of C are given by absolute square roots of the corresponding eigenvalues of G = CtC. When these non-negative singular values are ranked in terms of their descending magnitudes, i.e., , then corresponding singular vectors can also be ordered in descending degree of importance such as ,…,U(1),…, U(r−1), U(r) and V(1),…,V(r−1), V(r). For clarity, matrix D can be rearranged, i.e., for n < m and m<n, giving respectively
Note also that (7) can also be re-expressed as
| (9) |
with C(i) Ct(j) = 0 for i ≠ j, i.e., the matrices C(i) and C(j) are orthogonal and hence matrix C can be decomposed in an additive way as well. The matrices C(i) in (9) are uncorrelated “modes” of the original matrix C. Because of the ordering of singular values, the modes (C(i)’s) in (9) are also ordered, so that C(i)’s corresponding to negligible (small) singular values are sometimes loosely defined as noise and can thus be ignored in the analysis.
Simple arithmetic reveals, on the other hand, that the eigenvalues and eigenvectors of the matrix F= CCt will now be κ1, κ2,…, κm and U1,U2, ,Um, respectively. Accordingly, by definition of these values and vectors, we will have
The decomposition will then be
| (9) |
Note that the matrices Y(i) of the decomposition (9) are orthogonal in the sense that for all i ≠ j, we have
Furthermore, as it is the case with spectral decomposition in PCA, it is possible to obtain a pseudo (Monroe-Penrose) inverse C− of C as
where D− is the corresponding pseudoinverse of D. Because D is a diagonal matrix, its pseudoinverse will be also diagonal and will correspond thus to its transposition. So that, for the matrix D given earlier, i.e.,
the generalized inverse looks like
where , i = 1,2,…,n.
This much SVD algebra is suffient for this brief review. There are various applications of SVD in different areas of statistical analysis, but its main use is in general regression analyses yielded by
where the noiseless version of the model (3) above is considered and the norm is the Frobenius (Euclidean) matrix norm defined for any rectangular matrix M as
This particular use shows how SVD was first used (Lawson and Hanson, 1995).
Another use of SVD in the sense of three-matrix factorization as in (7) relates to decomposition of the observation matrix X and is usually observed in biology, where the matrix U is used for bioassay, elements of the matrix D are called singular values, and elements of the matrix V are interpreted as eigen genes. Matrix X is broken thus down to orthogonal summands, i.e.,
Matrix U is thus functionally identical to matrix A of the structural models in (1) and (2).
One of the main uses of SVD in the current context is for decomposition of covariance matrices. Because the covariance matrix of two differing vectors of distinct dimensions is rectangular, it is decomposable in the sence of SVD. Let a pair of vectors such as the (n×1) vector X and the (m×1) vector Y be given. Their covariance
is an (n×m) rectangular matrix and is therefore decomposable singularly as
Consequently, as in PCA, the variance-covariance matrix of any transformed vector Z = UtX will then be
where
with r = min {n,m}. We then use the spectral decomposition QΛQt for V(X), and in the last equality, we utilize the fact that multiplication of two orthogonal matrices such as Ut and Q yields again an (m×n) matrix Φ with orthonormal columns:
so that a typical element of ΦΛΦt becomes
The latter conclusion is obviously identical to the result that can be obtained from PCA.
In sum, SVD is more general than PCA because it is applicable to cases where PCA is applied but the converse is not valid. Furthermore, as mentioned earlier, an appropriate type of SVD (thin, compact, and truncated) can be chosen for a problem. Like PCA, SVD is also used for data reduction. As is the case with PCA, the application of SVD is restricted to phenomena that have statistical distributions with non-spherical contours. All in all, SVD has the same drawbacks as PCA because it is based on the same structural approach, which may be restrictive in some application areas. Also, the orthogonality restriction imposed by the analysis may not be suitable for some types of data. An interesting illustrative application is in Chung and Seabrook (2004). The next approach that we discuss goes to a further extreme in the last direction.
Independent Component Analysis (Blind Source Separation)
ICA seems to have been proposed by several authors from various disciplines in the last quarter of a century (Comon, 1994). However, the main areas of origin are signal processing and neural network analyses. ICA is also known as blind (myopic) source separation. The qualifiers “blind” or “myopic” are used to point out the property that the sole observable of the system is its output, i.e., the vector X of the model (1). “Independence” is affixed to the name, because of technical reasons concerning input, i.e., the vector Z of the model can satisfy certain contrast functions in signal processing when its coordinates are independent. The name “independent component analysis” seems to have been suggested by Jutten and Herault (1991) with respect to “principal component analysis”; they also refer to it as “blind source separation”.
In model (1) and/or (2) the variables X1, X2,…, Xn represent random observable variables and the variables Z1, Z2,…, Zm represent unobservable (latent) variables with A being a mixing matrix. When the matrix A is orthogonal as in PCA and SVD, the variables Z1, Z2,…, Zm become orthogonal transformations (projections) of the variables X1, X2,…, Xn. The orthogonality property results in mutual uncorrelatedness of Z1, Z2,…, Zm (see covarience matrix Λ above). Uncorrelatedness does not imply independence, which is obviously a stronger requirement than orthogonality. In terms of the method-of-moments terminology, orthogonality relates only to second moments (or cumulants) whereas independence also involves higher moments (or cumulants). ICA is based on the assumption that the generating sources for the variables X1, X2,…, Xn are independent. The joint distribution of X1, X2,…, Xn may be known or unknown. The objective of the analysis is to determine an unknown A and the corresponding unobservable vector Z=(Z1, Z2,…, Zm)t through some observations on X = (X1, X2,…, Xn)t.
Gaussian distributions are not appropriate for that objective, because, A cannot be identified and is therefore not estimable by these distributions. In fact, when X and Y are two vectors with each being an orthogonal transformation of the other, their metrics |X| and |Y| will thus be identical, i.e., |X| = |Y|. When both X and Y are assumed further to be Gaussian distributions with identical means and variances (for instance, when they have zero mean vectors and when their variances are equal to identity matrices of the same dimension), their densities will look like
Setting X = AZ and Y = AZ as in the model (1),
which shows that neither A nor Z can be identified by these densities.
Furthermore, Gaussian distributions are proved to have the largest entropy among the distributions of random variables with identical means and variances (Papoulis and Pillai, 2002, p.669). If we set H(X) for the entropy of a random vector X with coordinates Xi’s and H(S) stands for a system S with components Xi’s, the entropy corresponding to the whole vector X or to the system S is then given as
where P stands for the joint probability density function (pdf) for the discrete X, f denotes the joint pdf in the continuous case, and the logarithm is with respect to 2 or e base. The concept of entropy discussed here corresponds to Schroedinger’s (1944, p.73) concept of negative entropy. As such, it is an information measure. Thus, if H(XGaus) stands for the entropy of a random vector XGaus, which has a Gaussian distribution, and H(X) denotes the entropy of a distribution of non-Gaussian random variables represented by the vector X, then the non-negative magnitude
yields the discrepancy of entropies between the Gaussian-distributed XGaus and any other X supposed to be different from XGaus. Accordingly, the larger J(X) is the more different XGaus will be from X. One method for checking non-normality of the distribution involved consists of maximizing J(X) = J((X1, X2, …, Xn). Obviously, J(X) is a variation of negentropy (not to be confused with Schroedinger’s concept), which is shown to be invariant under linear transformations. The negentropy function J(X) can be considered as the initial technical process for estimating matrix A in the model (1) on the basis of joint distribution of X1, X2,…, Xn. However, if this estimation requires prior knowledge on the relevant pdf or its estimate, then this technique will be computationally difficult.
Before matrix A is estimated, statistically independent components of or statistically independent sources for the rows (or columns) of the matrix X in (1) must be checked (Lee et. al., 1998). A method used for that purpose is based on minimization of the mutual information function of Papoulis and Pillai (2002, p.647) or the transmission function of Conant (1968, p.11) defined as
| (10) |
where H(Xi) is the entropy of each individual random variable Xi of an n-dimensional column vector X = (X1, X2,…,Xn)t. T(X) is a non-negative quantity indicating discrepancy between entropies of the dependence case, i.e., H(X1, X2,…,Xn), and the n independence case, i.e., ; the latter is always larger than the former (Papoulis and Pillai, 2002, p.646). (The proof given by these authors corresponds to the two-subsystem [two-variable] case but can be easily extended to the n-variable case as well.) The larger the quantity T(X) in (10), the more dependent X1, X2,…,Xn become, in which case X1, X2,…,Xn are not appropriate for estimating matrix A. Obviously, to be able to minimize T(X), marginal and joint distributions of X1, X2,…,Xn must be known and, as previously remarked, estimation of pdf values is difficult. Methodological developments by Conant (1968 and 1972) allow all computations involved in T(X) to be easily based on empirical frequencies.
The essential method for estimating matrix A in (1) is a maximum likelihood technique that is applicable when the relevant densities are known (Hyvarinen and Oja, 2000; Comon, 1994; Hyvarinen et al., 2001). Before the application of this method, to be on the safer side, the required non-normality of the distribution involved and the necessary independence conditions used for estimation must be checked through the two methods previously discussed.
In sum, ICA has a well-founded statistical basis. The analysis displays the same drawbacks as PCA and SVD because its foundation is a structural approach that may not fit the data of some areas of the application. ICA evidently eliminates the orthogonality requirement of PCA and SVD by introducing the independence condition, but the latter actually is stricter than the former (for an illustrative comparative review of the above three techniques, see, Srinivasan et. Al.). Application of this technique seems to be restricted to non-Gaussian distributions. All three previous decomposition techniques are designed to choose matrix A of model (1) from among the matrices that satisfy orthogonality and independence properties imposed on real data. Such matrices may not be appropriate for biological data. We have thus another technique as proposed by the decomposition approach: NCA.
Network Component Analysis
Some recent discussions (Liao et. al., 2003) concerning PCA, SVD, and ICA note that the hypothesized relationship between Z and X (assumed to exist by these three techniques for the models (1) or (3)) imposes some statistical constraints on data; for example, orthogonality (orthonormality) and independence of unobservable variables are not warranted in some applications, such as biological experimentation. These methods obtain a (random) value of matrix A from a class of all real (complex)-valued matrices satisfying the hypothesized relationship. In an actual case, X is maintained to be produced by Z according to a bipartite network system between two distinct groups of phenomena such as phenotype and genotype (Figure 1).
FIGURE 1. A Pictorial Example for Network Design.

Depicted in the upper part is a bipartite network between four regulatory agents (gene knock-outs, drugs etc.) denoted by R1 through R4 and five outputs (e.g., growths of certain organisms) designated with O1 through O5. Connections between regulatory nodes and output nodes are shown as usual. The rectangular table just underneath the network represents the connectivity matrix B with columns corresponding to regulatory agents and rows to outputs. The regulatory matrix C is not shown in the picture. When there are no connections between output nodes (rows) and regulatory nodes (columns), the corresponding cells contain zero. Obviously, all other cells are composed of ones for the network shown here.
The (n×N) observation matrix X on the left side of (3) can be reconstructed as
| (11) |
where the (m × N) matrix C, which replaces matrix Z in (3) above and is now called ‘regularity matrix’, consists of N samples of m signal inputs (genotypes) with the condition m < N. The (n × m) connectivity matrix B, which replaces matrix A in (3) above, indicates the number of ways by which input signals (genotypes) are connected to signal outputs (phenotypes) in X so that each input may or may not be connected to each output. Thus, a typical entry (bij) of B shows how many times the jth signal input is connected to the ith output; it is zero when there is no connectivity between the relevant inputs and outputs. Regularity matrix C is assumed to be of full row rank (i.e., r(C) = m); connectivity matrix B is of full column rank (i.e., r(B) = m) with each column of B containing at at least (m − 1) zeros. By (3) and (10), we have
| (12) |
As follows from (12), the statistical assumptions concerning orthogonality or independence on the constituent factors Z work through the regularity matrix C on the right side of (11) in such a way as to make C comply with these orthogonality and/or independence criteria. The decompositions corresponding to the right side of (11) are unique up to a nonsingular transformation P such as A*=AP; Z*=P−1Z, B*=BP and C*= P−1C, which yields
As is proven in Liao et al. (2003, Appendix 1), when on the conditions C is of full row rank, the rank of B equals the number of its columns, and each column of B contains at least (m − 1) zeros, the transformation matrix P can only be a diagonal matrix so that the decomposition X = BC is unique up to a diagonal scalar. This ensures identifiability of a system up to diagonal scalar in the sense that, corresponding to certain regularity C, only one connectivity (network) matrix B produces the observations X.
From a computational standpoint, the matrix decomposition BC of X is obtained through an iterative optimization (minimization with respect to matrices B and C), an algorithm applied to the square of Frobenius (Euclidean) matrix norm mentioned earlier, e.g.,
of the rectangular matrix M = X − BC. Hence, B and C are estimated from X by using a two-step least-squares algorithm using the objective function
subject to the side condition that the connectivity pattern B belongs to a manifold of matrices with a certain pattern (e.g., entries representing connectivity are arbitrary non-zero natural numbers initially and non-connectivity is represented by zero). The detailed algorithm of estimation itself is summarized and can be found in Liao et al. (2003, Appendix 2).
To sum up, NCA has fundamentally the same foundation as the previous analyses: It has a structural and therefore a parametric approach, the only difference being the estimate of matrix A from a narrower class of matrices satisfying a certain network configuration. It therefore displays the same drawbacks as PCA, SVD, and ICA.
Decomposition by Information Transfer
As it is the case with the previous approaches, the idea behind the decomposition by ITF is to find a much simpler system than a given system, simplicity being defined as lack of complexity of systems (especially for hierarchical systems that are composed of some layers of subsystems). Unlike PCA, SVD, ICA, and NCA, ITF does not specify a structural model and analysis is not carried out in terms of such a model. Ignoring the specific natures of components that make up a system, a measure of complexity of a system can be related to the earlier-defined entropy H(S) and transmission T(S) functions for a system S = {X1, X2,…,Xn} with n ordered components X1, X2,…,Xn.. For technical reasons, S is not necessarily a vector with coordinates X1, X2,…,Xn but represents a system with ordered components in the sense that, unless stated otherwise, all permutations of {X1, X2,…,Xn} stand for distinct systems. Thus, because complexity is related to information (actually, a lack of information), the following non-negative magnitude, which is in fact a measure of information,
can be used to measure lack of complexity of a system when n individuals (components) are taken one by one and their inherent potentials (measured in terms of entropy) are added up arithmetically. The underlying assumption for such measure is that individuals act independently and do not exhibit a coherent body. Similarly,
is also a measure of information (lack of complexity) when interactive behavior of n components is taken into account, i.e., when individuals form a coherent body of a system.
The transfer function T(X) already defined as a difference of the two foregoing measures of information in (10) is now designated by T(S, p) and will be defined in terms of the components of S:
| (13) |
This obviously is a non-negative measure of change in information between a system composed of a random collection of n independent individuals and a system composed of an integrated body of these n individuals. In a way, the transfer function indicates useable information that exists in components for the system. The larger the magnitude, the more remote the system S will be from the chaotic case of n components being unable to form a system. The symbol p, expressed precisely as p {X1, X2,…,Xn}, represents a partition of S. The notation T(S, p) hence emphasizes that information transformation depends on the given system S as well as the specific partition p of S under consideration. Roughly, the contribution of p to T(S, p) n corresponds to the sum on the right side of (13), and that of the S-part is given by H(X1, X2,…,Xn) on the same side of the equation. Because we now are dealing with a system rather than the vector X, we now bring in the system symbol S into (10) to have the notation in (13). By a partition p {S1, S2,…, Sq} of S, we mean a collection of disjoint subsets S1, S2,…, Sq, (q ≤ n) of S that exhaust S, i.e., . The simplest partition is p {X1, X2,…, Xn} as in (13), where q = n with Si ={Xi} and is called the element partition. A trivial partition is p {S}, i.e., p {S}=S with q=1 whereas numerous partitions correspond to 1< q < n, the well known of which is the dichotomous partition p {S1,S2}. With partition notation p {S1, S2,…, Sq}, the ITF becomes
| (14) |
where H(S1,S2,…,Sq) is equal to H(X1, X2,…,Xn) because and H(S1), H(S2), …, H(Sq) are the corresponding entropies of the individual elements of the partition. Equation (14) can be interpreted as unused information in p {S1, S2,…, Sq} for the system S. As noted earlier, (10) and its variations as in (13) and (14) are specifically discussed in Papoulis and Pillai (2002) and Conant (1968, 1972). For applications in classical statistical inference, a parallel information theoretic approach is adopted by Kullback (1959, Chapters 1 through 3).
To emphasize the interaction between these two sets when a dichotomous partition p {S1, S2} and their transmission is involved, the function T is sometimes indexed by the subscript B, i.e.,
Similarly, to emphasize interaction within the system S ={X1, X2,…,Xn} with an element partition p, the magnitude T(S, p) can also be tagged as TW(S, p), where the subscript W stands for the interaction within the system S. Because a coherent system can only be composed of a series system, a parallel system, or a mixture of both (Barlow and Prochan, 1975, Chapter 2), then the probability corresponding to the partition can range from the probability of the former, i.e., P(S1, S2) = P(S1) × P(S2) with its entropy being H(S1,S2) = H(S1) + H(S2), to the probability of the latter, i.e., P(S1, S2) = min{P(S1), P(S2)} with the corresponding entropy of the latter being H(S1, S2) = min{H(S1), H(S2)}. We have thus a maximum value for T(S1,S2, p) that is obtained when H(S1, S2) = min{H(S1), H(S2)} and the minimum value of TB(S1,S2, p) is reached when H(S1,S2) = H(S1) + H(S2), in which case TB(S1,S2, p) = 0. The minimum value of the transfer function indicates that S1 and S2 are independent in statistical terms. If we let TUB(S1:S2) stand for the maximal value of TB(S1,S2, p),
| (15) |
For all systems partitioned as S1 and S2 and having joint distributions with fixed marginal distributions for S1 and S2 (i.e., systems with the given marginal distributions of S1 and S2), T12 will be closer to one as the underlying sub-systems S1 and S2 get more and more integrated to form a whole system and will approach to zero as S1 and S2 become disintegrated to form separate systems. T12 is actually some version of the absolute value of the usual correlation coefficient when S1 and S2 are singletons like S = {X1}and S2 = {X2}. Hence, T12 = 0 means non-relatedness of subsets S1 and S2, and T12 = 1 implies that S1 and S2 depend completely on each other. This latter aspect of transfer functions is amply emphasized in Conant (1968, 1972).
For comparison of the complexities of pairs of subsystems, Conant (1968) introduced an additional instrumental index called the interaction measure:
| (16) |
which is useful in detecting a change in the complexity of Sj when it is integrated into the subsystem Si, so that the interdependence among the components of Sj are evaluated against their joint conditional interdependence, given the integration of the elements of Si. TSi (S j, p) in (16) denotes the conditional transmission over Sj ={Xj1, Xj2,…, Xjr} and given the interrelatedness of the elements of Si, and is defined as
where
Unlike the T(.) transfer functions that are always positive, the interaction measure Q(.) in (16) can be negative (i.e., the sets Si and Sj interact negatively), positive (i.e., Si and Sj interact positively), or zero (i.e., Si and Sj are stochastically independent).
The usefulness of the information transfer function in (13) or (14) for applications of systems is two-fold. When we have no usable information or conversely when we have full information on both S and p, the function T(S, p) ceases to be useful. Its use becomes accentuated when we have partial information on S and/or p. In fact, we may be in a position to obtain a system with some given subsystems or to derive some subsystems from a given system. The former problem is composition (integration) and latter is decomposition. In composition, p is known but we have no information on S. In decomposition, we have information on S but none about p. Information on p and/or S means knowledge about the distributions involved as well; “information” as used here is either in the theoretic sense, e.g., the information transfer function, or is in the daily usage sense, i.e., knowledge. Thus, for solution of the integration problem, the information transfer function is maximized over all possible systems 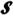 ={S|S• } that yield the given common partition p. In other words, H(S)= H(S1,S2,…,Sq) or H(X1, X2,…,Xn) is minimized. Conversely, a solution for decomposition (partition p) is obtained by minimizing the transfer function over all possible partitions π = { p: p • π } of the given system S. In other words,
or
is minimized. Composition is not simply a reversal of decomposition because, in addition to the required knowledge on relevant partition, the so-called blueprint of composition must also be known, i.e., compatibility of all marginal distributions with the given joint distribution of S must be checked (Dall’Aglio, 1972; Butterfly et. al., 2005; Arnold et al., 1999). However, the current work is only interested in decomposition.
={S|S• } that yield the given common partition p. In other words, H(S)= H(S1,S2,…,Sq) or H(X1, X2,…,Xn) is minimized. Conversely, a solution for decomposition (partition p) is obtained by minimizing the transfer function over all possible partitions π = { p: p • π } of the given system S. In other words,
or
is minimized. Composition is not simply a reversal of decomposition because, in addition to the required knowledge on relevant partition, the so-called blueprint of composition must also be known, i.e., compatibility of all marginal distributions with the given joint distribution of S must be checked (Dall’Aglio, 1972; Butterfly et. al., 2005; Arnold et al., 1999). However, the current work is only interested in decomposition.
All foregoing discussions and indices are undoubtedly relevant when distributions are known. When such information is unavailable, empirical distributions can be used as consistent estimates. Collecting observations for this purpose is costly and difficult. This is basically true for empirical assessment of joint distributions when we are interested in obtaining estimates of multivariate distributions for large sets of components. The following illustrate the initial stages where observations on element partition and pair-wise partition of the system are available:
Illustration One
A simple empirical case corresponds to the availability of observations on each individual component. Let S ={Y1, Y2,…,Yn} hence be a system with n ordered components and with the given matrix X of discrete observations
where yij denotes the ith functional value (i=1,2,…, κ) taken up by the jth component of the system S = {Y1, Y2,…,Yn}. The number (say, κ) of functional values is identical for each random component for the convenience of notation. The values yij are not necessarily identical for all components. Assume further that these values are observed with the frequencies in Table 1:
Table 1.
Observations on element partitioning
| Y1 | Y2 | … | Yn | ||
| yi1 | m11 | m12 | … | m1n | |
| yi2 | m21 | m22 | … | m2n | |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | |
| yiκ | mκ1 | mκ2 | … | mκn | |
| Marginal Sums | m ∘1 | m ∘2 | … | m ∘n | m |
By definition, the magnitudes m∘j and m in Table 1 are and . These observations are sufficient for obtaining estimates for marginal distributions of the individual components Y1, Y2,…,Yn. A real-life example for this case corresponds to frequency of long-distance phone calls mij placed at a certain geographical location Yi at some given time unit yij.
Consider the element partition p {S1, S2,…,Sn}of S where Sj={Yj} for each component Yi. Thus, the marginal probability of each component Sj={Yj} is P(Sj) = πj, which can be consistently estimated by . For each component Yi,, the probability of the event {Yj=yij} is represented by P(Yj=yij|Sj) = πi|j, which will, similarly be estimated by . However, after observing the system S, the probability for the same event {Yj=yij} becomes P(Yi=yij|S) = πij and is estimated with . Accordingly, estimates for the entropies of individual components are
and the estimate for the system entropy is given by
By (11), the estimated information transfer will be
| (17) |
A vanishing value of this non-negative real number in (17) provides some evidence that the partition p {S1, S2,…,Sn} conforms well with the given system S, so that the degree of its divergence from zero is a clue that there is still some unused information in p {S1, S2,…,Sn} for S. When Tr(Ŝ,P)= 0, observations suggests that the system cannot be decomposed further than the element decomposition p {S1,S2,…,Sn}. A non-vanishing value of the empirical information transfer function Tr(Ŝ,P)thus suggests that it is worthwhile to seek decompositions other than p {S1,S2,…,Sn}. We can partition S in some other way such as p {S1, S2,…,Sq} where 1< q < n. The foregoing analysis can be repeated using (14) to check whether p {S1, S2,…,Sq} has some information for S. In that case, the system entropy estimate will stay put, but estimates of entropies H (Ŝℓ) of individual subsets Sℓ will change.
The given observations in the Table 1 are clearly not sufficient for obtaining a conclusion beyond the result obtained above. For further conclusions we need more sophisticated observations and experiments. Hence, we have the next illustration:
Illustration Two
The second illustration relates to a case where empirical data for pairs of components are available. This case is more general in the sense that availability of empirical observations (frequencies) on pairs of random variables also implies availability of observations on individual variables. Assume again, for simplicity of exposition, that the random components Y1, Y2,···, Yn−1 and Yn are discreet and the number of functional values taken by each Yi is ri, (i=1,2,…,n) with these values ranging over the whole numbers
For notational convenience and without a loss of generality, we can assume that ri = r for all i=1,2,…,n. In accordance with a certain pattern, the joint event {Yi=yih, Yj=yjk}, i• j, takes values in the discrete (r(n−1))× (r(n − 1)) matrix layout set up as in Table 2. This layout is now our observational system T, which is a proper subset of S×S.
Table 2.
Pair-wise observations
| Y1 | Y2 | … | Yi | … | Yj | … | Yn | ||
| Y1 | |||||||||
| Y2 | |||||||||
| ⋮ | |||||||||
| Yi | |||||||||
| ⋮ | |||||||||
| Yj | |||||||||
| ⋮ | |||||||||
| Yn | |||||||||
Because we are interested in cross pairs of variables like Yi and Yj with i ≠ j, the diagonal cells (darker gray) are irrelevant and we therefore have (n−1) rows and (n−1) columns of interest. Hence, off-diagonal cells become a center of interest. Each off-diagonal cell is composed of an (r×r) matrix of observations on the bi-variable event such as {Yi=yih, Yj=yjk}, i ≠ j = 1,2,…,n and h,k = 1,2,…,r. When the two events {Yi=yih, Yj=yjk} and {Yj=yjk,Yi=yih} are identical, i.e., when they are symmetrical, only the upper or lower off-diagonal part of the table can be used. For convenience of visualization, the unused part (for instance, the lower part) is shaded in light gray. In this latter case, the upper off-diagonal block cells become the system T of observations to be considered below. The bottom row and the last column shaded in blue are empty and the cell in the southeast corner contains one single element marked m representing total number of observations.
To aid exposition, the cell corresponding to the observational frequencies on the ith and jth variables (orange) is reproduced in Table 3 with the same color. For the specific pair of Yi and Yj, the symbol m i(h)j(k) in stands for the frequency with which the bi-variable event {Yi=yih, Yj=yjk} is observed empirically. The last column and the bottom row present marginal frequencies involved (column-wise and row-wise sums of the frequencies in the table): For observations on
Table 3.
Frequencies of {Yi=yih, Yj=yjk} in Table 2 for the highlighted pair of i and j
| mi(1)j(1) | mi(1)j(2) | … | mi(1)j(r) | mi(1)j |
| mi(2)j(1) | mi(2)j(2) | … | mi(2)j(r) | mi(2) j |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| mi(r)j(1) | mi(r)j(2) | … | mi(r)j(r) | mi(r) j |
| mi j(1) | mi j(2) | … | mi j(r) | mi j |
{Yi=yis} corresponding to a certain s =1,2,…,r we have
and similarly, for a certain t =1,2,…,r we have
Thus,
with
As it is designated in Table 2, m is located in the southeast cell of the table.
The upper off-diagonal block cells of Table 2 can now be labeled T1, T2, …,Tq. p {T1, T2, …,Tq} is a proper partition of T. Labeling starts from the top leftmost cell of the table and then goes to the leftmost off-diagonal block cell of the second row and so on as in the lexicographical ordering: T1 for {Y1,Y2}, T2 for {Y1,Y3},…, Tq for {Yn−1,Yn}. For each partition ℓ= (i,j), i < j, estimates of the marginal probabilities
are given by
For the whole system the same estimate becomes
so that, as before,
The estimated transfer function
will have small values close to zero when a pair-wise partition is enough for decomposition whereas its higher values will produce evidence that there is further information to be utilized in T for a further partition p {T1, T2, …,Tr}, q ≠ r.
ITF seems to be free from restrictions of structural modeling and does not depend on the type of distribution of the random variables involved. It also does not require any restriction on the type of interaction of variables such as their uncorrelatedness, independence, etc. It therefore is a flexible technique but need a great deal of care and designing efforts before being applied empirically. As it is the case with previous approaches, high dimensionality of data may at times be a deterrent factor in its application.
Concluding Remarks
This work is an attempt to provide a uniform body of exposition for available techniques of decomposition in the literature. Because of prevailing high-dimensionality issues, these techniques have increased in importance for the past two decades. Except for some comments and the two illustrations of the use of information transfer and for our efforts to present a unified standpoint, we do not claim originality. Our unifying framework has been probability theory and multivariate statistics as well as information theory. We have not dwelt on inferential issues concerning use of statistical estimates because of our intension to provide a general text that will apply to a large spectrum of application areas.
Regarding the applicability of the five techniques reviewed: All of the four techniques PCA, SVD, ICA, and NCA are based on structural modeling of a real-life phenomenon; they are dependent upon some assumptions concerning interactive nature of real-life events such as uncorrelatedness or independence which may be restrictive for data; they are analytically well-founded, which paves the way for their preference; and they have dimension reduction properties in their favor. The last technique, ITF, is free from all such drawbacks but requires challenging tasks of design and computation. Unlike the first three techniques, it is not particularly used for data reduction purposes. All five techniques confront high-dimensionality problems and seem to need care in applications involving Gaussian distributions.
Acknowledgments
We would like to acknowledge and are thankful for some constructive comments and suggestions of two anonymous referees with whose contributions the manuscript was substantially improved. The first two authors would also like to express their gratitude to the Department of Electrical and Computer Engineering of University of Alabama at Birmingham for providing a convenient administrational setting for cooperation.
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
Contributor Information
Yalcin Tuncer, Professor Emeritus, Middle East Technical University and Ankara University, Ankara, Turkey.
Murat M. Tanik, Department of Electrical and Computer Engineering, U.A.B., Birmingham, Alabama 35294-4461, USA.
David B. Allison, Department of Biostatistics, School of Public Health, U.A.B., Birmingham, Alabama
References
- Anderson TW. An Introduction to Multivariate Statistical Analysis. John Wiley and Sons; New York: 1984. [Google Scholar]
- Arnold B, Sarabia J-M, Castillo E. Conditional Specification of Statistical Models: Models and Applications, Springer Series in statistics. Springer-Verlag; New York: 1999. [Google Scholar]
- Ash RB. Information Theory. Dover; New York: 1990. [Google Scholar]
- Barlow RE, Prochan F. Statistical Theory of Reliability and Life Testing. Holt, Rinehart and Winston; New York: 1975. [Google Scholar]
- Browning TR. Applying the design structure matrix to system decomposition and integration problems: A review and new directions. IEEE Transactions on Engineering Management. 2001;48 (3):292–306. [Google Scholar]
- Butterfly P, Sudbery A, Szule J. Compatibility of subsystem states. Quantum Physics. 2005;3 (arXiv:quant-ph/0407227 v 3 22 Apr 2005) [Google Scholar]
- Chung S, Seabrook C. A singular value decomposition: analysis of grade distributions. Georgia Institute of technology; VIGRE REU: 2004. http://www.its.caltech.edu/~mason/research/carstep.pdf. [Google Scholar]
- Comon P. Independent component analysis, a new concept? Signal Precessing. 1994;36:287–314. [Google Scholar]
- Conant RG. Information transfer in complex systems with applications to regulation. University of Illinois; 1968. unpublished Ph.D. dissertation. [Google Scholar]
- Conant RG. Detecting subsystems of a complex system. IEEE Transactions on Systems, Man, and Cybernetics. 1972 September;:550–553. [Google Scholar]
- Dall’Aglio Frechet classes and compatibility of distribution functions. Symposia Math. 1972;9:131–150. [Google Scholar]
- Donoho S. High-dimensional data analysis: the blessings and curses of dimensionality. AMS special conference “0n mathematical challenges of the 21st century”; UCLA, Los Angeles. 6–11 August 2000.2000. [Google Scholar]
- Eckart C, Young G. Approximation of one matrix by another of lower rank. Psychometrika. 1936;1:211–218. [Google Scholar]
- Fan J, Li R. Statistical challenges with high dimensionality: feature selection in knowledge discovery. The Mathematics Arxive: math. 2006 ST/0602133. [Google Scholar]
- Gurrera MDC. Construction of bivariate distributions and statistical dependence operations. University of Barcelona Department of Statistics; 2005. Ph. D. Dissertation. [Google Scholar]
- Hastie T, Tibshirani R, Eisen ME, Alizadeh A, Levy R, Staudt L, Chan WC, Botstein D. “Gene shaving” as a method for identifying distinct sets of genes with similar expression patterns. Genome Biology. 2000:1. doi: 10.1186/gb-2000-1-2-research0003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hotelling H. Analysis of a complex of statistical variables with principal components. Journal of Educational Psychology. 1933;24:417–441. 498–520. [Google Scholar]
- Hyvarinen A, Oja E. Independent component analysis: algorithms and applications. Neural Networks. 2000;13:411–430. doi: 10.1016/s0893-6080(00)00026-5. [DOI] [PubMed] [Google Scholar]
- Hyvarinen A, Karhunen J, Oja E. Independent Component Analysis. John Wiley and Sons; New York: 2001. [Google Scholar]
- Johnson RA, Wichern DW. Applied Multivariate Statistical Analysis. 5. Prentice-Hall, Inc; Englewood Cliff, New Jersey: 2002. [Google Scholar]
- Jolliffe IT. Principal Component Analysis. 2. Springer-Verlag; New York: 2002. [Google Scholar]
- Jutten C, Herault J. Blind separation of sources, Part 1: An adaptive algorithm based on neuromimatic architecture. Signal Processing. 1991;24:1–10. [Google Scholar]
- Kendall M. Multivariate Analysis. Charles Griffin & Company; London: 1975. [Google Scholar]
- Kullback S. Information and Statistics. John Wiley and Sons; New York: 1959. [Google Scholar]
- Lawson CL, Hanson RJ. SIAM: Classics in Applied Mathematics. 3. Vol. 15. Philadelphia: 1995. Solving Least Squares Problems. [Google Scholar]
- Lee TW, Girolami M, Bell AJ, Sejnowski TJ. A unifying information theoretic framework for independent component analysis. International Journal on Mathematical and Computer Modeling 1998 [Google Scholar]
- Liao R, Boscolo Y-L, Yang LM, Tran CS, Roychowdhury VP. Network component analysis. PNAS. 2003;100:15522–15527. doi: 10.1073/pnas.2136632100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Papoulis A, Pillai SU. Probability, Random Variables and Stochastic Processes. 4. McGraw-Hill; 2002. [Google Scholar]
- Pearson K. On lines and planes of closest fit to systems of points in space. Philosophical Magazine. 1901;2:559–572. [Google Scholar]
- Press WH, Teukolsky SA, Vetterling WT, Flannery BP. Numerical Recipes in C. 2. Cambridge University Press; Cambridge: 1992. [Google Scholar]
- Scheffe H. The Analysis of Variance. John Wiley and Sons; New York: 1959. [Google Scholar]
- Schroedinger E. What Is Life ? Cambridge University Press; Cambridge: 1944. [Google Scholar]
- Seber GAF. Multivariate Observations. John Wiley and Sons; New York: 1984. [Google Scholar]
- Srinivasan SH, Ramakrishnan KR, Budhlakoti S. Character decompostions. www.ee.iitb.ac.in/~icvgip/PAPERS/292.pdf.
- Stewart GW. On the early history of the singular value decomposition. SIAM Review. 1993;35(4):551–566. [Google Scholar]