

Abstract
English-learning toddlers of 21 and 22 months were taught a novel spatial word for four actions resulting in a tight-fit spatial relation, a relation that is lexically marked in Korean but not English (Choi & Bowerman, 1991). Toddlers in a control condition viewed the same tight-fit action events without the novel word. Toddlers’ comprehension of the novel word was tested in a preferential-looking paradigm. Across four videotaped pairs of action events, a tight-fit event was paired with a loose-fit event. Only toddlers who were taught the novel spatial word looked significantly longer at the tight-fit events during the test trials that presented the novel word than during control trials that presented neutral linguistic stimuli. The results indicate that toddlers can map and generalize a novel word onto actions resulting in a tight-fit relation, given limited experience with the novel word. The results provide insight into how young word learners begin to form language-specific semantic spatial categories.
Keywords: Language and cognition, language-specific semantic categories, spatial categorization, spatial language, word learning
When learning to label the spatial relation between two objects (e.g., a ball being placed in a box), young children cannot simply match their existing preverbal spatial concepts with a particular spatial morpheme because languages differ in how they organize spatial events into semantic categories (Bowerman, 1989, 1996). Young children nevertheless display little difficulty in acquiring the semantic spatial categories that are specific to their language (Bowerman, 1989, 1996; Sinha, Thorseng, Hayashi & Plunkett, 1994). They acquire the spatial morphemes of their language relatively quickly and with few errors (Choi & Bowerman, 1991; Choi, McDonough, Bowerman & Mandler, 1999). However, studies have yet to explore how much experience young word learners require when learning to form a novel semantic spatial category. The purpose of the current study is to explore this question by documenting whether young children are motivated by a novel spatial word to form a novel semantic spatial category.
Choi & Bowerman (1991) were among the first to outline crosslinguistic differences in young children’s descriptions of spatial events. They found that Korean- and English-learning children resembled the adult speakers of their respective languages more than each other in their early utterances of spatial events. For example, English-learning children, similar to adult English speakers, labeled containment events as in (e.g., a ball being placed in a box) and support events as on (e.g., a ball being placed on a box). In contrast, Korean children, similar to adult Korean speakers, labeled the same spatial events according to whether two objects were placed in a tight-fit or interlocking relation with one another, consistent with the Korean term kkita, a morpheme used to describe actions resulting in a tight-fit containment or a tight-fit support relation.
Similarly, Choi et al. (1999) found that toddlers’ comprehension of spatial terms is also consistent with the semantic pattern of their ambient language. They tested 18- to 23-month-old English- and Korean-learning toddlers in a preferential-looking paradigm during which toddlers viewed pairs of scenes. For every pair, one scene depicted an action that resulted in a tight-fit relation while the other scene depicted an action that resulted in a loose-fit relation. For two scene pairs, the tight-fit event depicted a containment relation (e.g., pegs being placed in a tight-fit relation into holes made to fit them, books being placed into a box cover); for the remaining two scene pairs, the tight-fit event depicted a support relation (e.g., a Lego block being placed on another Lego block, plastic rings being placed on a pole). During a control trial, children were encouraged to look at each scene in a pair. During two test trials, the spatial word in was provided for English-learning toddlers whereas kkita was provided for the Korean-learning toddlers. When the control and test trials were compared, the amount of time children looked at the matching scene (containment for the English-learning toddlers and tight-fit for the Korean-learning toddlers) was equivalent. However, the amount of time children looked at the non-matching scene differed from the control to the test trials: English-learning toddlers looked significantly less at the non-matching scene (i.e., the support event) when hearing the word in than during the control trial (which did not present the target word); likewise, Korean toddlers looked significantly less at the non-matching loose-fit scene when hearing kkita during the test trials than during the control (when the target word was not presented).
These research findings demonstrate that young children of 18–23 months of age have begun to acquire language-specific semantic spatial categories. In fact, young children appear to have such categories from the time that they begin to comprehend spatial words. Although research conducted so far has been instrumental in delineating when young children begin to acquire language-specific semantic spatial categories, research has yet to explore how quickly this learning can take place. Studies to date have focused on exploring children’s comprehension and production of the semantic categories to which they are exposed in their own language, making it difficult to know how much exposure to a particular morpheme young children receive prior to beginning to comprehend the linguistic term and forming the corresponding semantic spatial category.
There is some evidence that young children acquire spatial morphemes rather quickly. For example, Choi & Bowerman (1991) found that once a particular spatial morpheme appeared in a child’s speech, the child generalized the spatial term to novel instances fairly rapidly, with few errors. Tomasello (1987) reported a similar pattern of learning in a case study of his daughter’s early use of prepositions. Although these findings suggest that young children can acquire spatial morphemes quickly and easily, the studies were not designed to address how much exposure to a spatial morpheme is necessary for this learning to take place.
Research on the acquisition of object labels shows that infants as young as 13 and 14 months of age can quickly map a novel word for an object, given only limited experience with the novel word (e.g., Werker, Cohen, Lloyd, Casasola & Stager, 1998; Woodward, Markman & Fitzsimmons, 1994). Does the learning of spatial language proceed as rapidly? In addition, can young word learners quickly generalize a novel spatial word to new instances of an action resulting in a specific spatial relation?
In this study, English-learning toddlers of 21–22 months of age were tested on their ability to comprehend and generalize a novel spatial word for actions resulting in a tight-fit spatial relation, events which are labeled with kkita in Korean. Even though English-learning infants of 9–14 months are sensitive to the distinction between tight-fit and loose-fit containment (McDonough, Choi & Mandler, 2003; see also Hespos & Spelke, 2004), results from Choi et al. (1999) demonstrate that English-learning toddlers disregard this spatial distinction for the purposes of linguistic expression, grouping tight-fit and loose-fit containment into a single semantic category. Even in a nonlinguistic task, English-learning infants of 6 months can form a spatial category of containment that groups tight-fit containment and loose-fit containment into a single category (Casasola, Cohen & Chiarello, 2003). In contrast, English-learning infants of 10 and 18 months provide no evidence of being able to form a spatial category of tight-fit when habituated to examples of tight-fit containment and tight-fit support (Casasola & Cohen, 2002). Hence, a category of tight-fit, one that includes both tight-fit containment and tight-fit support, is not a spatial category that English-learning infants have been demonstrated to possess.
On a general level, the current experiment was designed to explore toddlers’ ability to comprehend a novel word for an action resulting in a particular spatial relation, given limited exposure to a novel word. On a more specific level, the study explored whether English-learning toddlers could be taught a novel spatial word for a tight-fit relation, consistent with the Korean semantic category expressed with kkita. That is, could English-learning toddlers be taught to behave in a manner similar to Korean-learning toddlers when tested in a preferential-looking paradigm if they are trained with a novel word for tight-fit action events? In order to acquire the novel spatial word, English-learning toddlers would have to learn to focus on the tight-fit relation, a spatial relation that is not lexically marked in English. Furthermore, toddlers would have to learn to group tight-fit containment and tight-fit support into a single semantic category, cross-cutting the English semantic categories of in and on (Choi & Bowerman, 1991).
Because English-learning toddlers of 21 and 22 months have already begun to acquire the English semantic categories of in and on (Choi & Bowerman, 1991), the toddlers in the current study may face a somewhat harder task than young Korean word learners learning the semantic category of kkita. That is, they have to learn to shift their focus from the distinction between containment and support in an action event to the distinction between tight-fit and loose-fit in the same action events. They would also have to learn to group tight-fit containment and tight-fit support into the same semantic category. Examining whether English-learning toddlers can acquire and generalize a novel word for actions resulting in a tight-fit relation would provide insight into how language-specific semantic categories are formed. The study also provides the opportunity to explore how readily toddlers generalize a novel spatial word to novel instances of tight-fit.
METHOD
Toddlers in the current study were exposed in a training setting to tight-fit relations between training objects. Some of the children heard the novel label keet in relation to this tight-fit relation; some did not. All children were then tested for their understanding of keet in a preferential-looking task to discern if those who had been trained with keet had developed a semantic representation for this word.
Participants
Thirty-two toddlers (16 males, 16 females) of 21–22 months (± 2 weeks) participated. Toddlers were at least 37 weeks gestational age, of normal birth weight, and had no reported visual or auditory problems. Seven of these 32 toddlers were excluded from the final sample because they demonstrated extreme looking times (N = 5)1 or a right or left monitor preference (N = 2)2 during the preferential-looking paradigm, resulting in a final sample of 25 toddlers (11 males, 14 females). Likewise, an additional 10 toddlers were tested but were not included in the analyses due to fussiness (N = 2) or failure to complete the procedure (N = 8).
Participants were recruited via a letter given to parents at the time of their child’s birth. If interested, parents were sent a subsequent letter and telephoned when their toddler was the appropriate age. Participants were given a T-shirt in appreciation.
Toddlers were randomly assigned to either a Novel Word or a No Word condition. All participants underwent a training session, followed by a preferential-looking session. Information on the participants’ productive and receptive vocabularies was collected from parents using the MacArthur-Bates Communicative Development Inventories: Words and Sentences, as well as the Places and Locations section of the MacArthur-Bates Communicative Development Inventories: Infants (Fenson, Dale, Reznick, Thal, et al., 1993b).
Stimuli
Training session
For the training session, four pairs of objects were selected to depict actions resulting in a tight-fit relation. Each of these training objects was easy for both the experimenter and the toddlers to manipulate, and each object in a pair could easily be placed in a tight-fit relation to the second object in the pair. The four training object pairs are depicted in Fig. 1 as they were seen after being joined together in a tight-fit relation. Two of the joined, training object pairs depicted a tight-fit containment relation (a cork placed in a bottle and a green peg placed in a plastic yellow block), and two depicted a tight-fit support relation (a spotted Lego dog placed on a blue Lego block and a purple plastic lid placed on a pink plastic cup). An independent sample of six native-speaking Korean adults described all four actions with kkita.
Figure 1.

The object pairs used to depict the actions resulting in a tight-fit relation during the training session; although each object in a pair was presented individually to toddlers, the pairs are depicted joined together in their tight-fit relation
Preferential-looking session
For the preferential-looking session, eight dynamic action events were videotaped. In each action event, two objects were side by side, with the smaller object in a pair situated to the left of the larger (or referent) object. A hand appeared from the left, lifted the closer (and smaller) object and placed it in a spatial relation to the referent (larger) object. The event pairs for the preferential-looking session were created so that the object moved by the hand resulted in a tight-fit relation in one action event but in a loose-fit relation in an alternate action event in the pair (see the Appendix for selected frames of each action event in a pair). Events within a pair were synchronized with respect to each aspect of the event (e.g., when the hand entered, when the first object was lifted, when the object was placed in its spatial relation to the referent object and when the hand withdrew). In each event, the hand exerted equal amounts of pressure when placing the object in its spatial relation, to prevent toddlers from discriminating between tight-fit and loose-fit events on this basis.
A peg, a chicken, a cup and a colored ring were used to depict the videotaped tight-fit and loose-fit action events. For example, a green peg was placed in a yellow plastic block as the tight-event and the peg was placed on the block as the loose-fit event. This particular tight-fit event was a videotaped version of the last training event presented by the experimenter during the training session. Hence, the peg being placed in a tight-fit relation to the block was a familiar action event to toddlers.
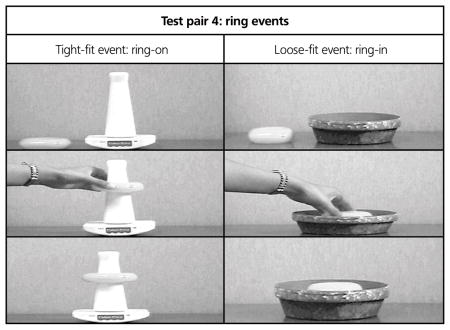
The remaining tight-fit and loose-fit events presented objects that toddlers had not viewed during the training session: the chicken, cup and colored ring. For example, a second event pair depicted a Duplo chicken being placed on a purple Duplo block as the tight-fit event versus the chicken being placed in a purple plastic bowl as the loose-fit event. The event pairs with the cup depicted a red plastic cup being placed in a plastic green cup as the tight-fit event versus the red cup being placed on an inverted blue plastic bowl as the loose-fit event. Finally, the event pairs with the colored ring depicted an orange plastic ring being placed on a white pole as the tight-fit event versus the ring being placed in a green ceramic bowl as the loose-fit event. Native Korean speakers confirmed that the action of placing the peg, chicken, cup and ring in a tight-fit spatial relation, but not in the loose-fit spatial relation, would be labeled as kkita.
These events were chosen to resemble the visual events employed by Choi et al. (1999). The events also were chosen so that half were tight-fit containment events and half were tight-fit support events. In this manner, toddlers would be unable to simply map keet onto either containment or support but rather would have to focus on the tight-fit relation and treat both tight-fit containment and tight-fit support as instances of the novel word keet.
Auditory stimuli were recorded for the preferential-looking session. For each object, phrases specific to that object were spoken by a female voice in infant-directed speech for two familiarization trials, a control trial and two test trials, e.g., ‘See the peg’, ‘What happens? Where does she put the peg?’ The visual and auditory stimuli were recorded using a Canon ZR10 digital video camera, transferred to and edited on a Macintosh G4 computer with Final Cut Pro software, then converted into QuickTime digital movies for use in the preferential-looking paradigm.
Apparatus
For the training session, toddlers, their parent and an experimenter were in a 12 m × 10 m room with a child-size table (66 cm × 66 cm × 54 cm). A Panasonic video camera, used to record the training session, was 45 cm from the table. For the preferential-looking session, toddlers and their parents were taken to a 3 m × 3 m testing room. The toddler was seated on the parent’s lap approximately 127 cm in front of the center monitor of three 20-inch color monitors. The monitors were on a table so that they would be at a toddler’s eye level and were arranged side by side, approximately 23 cm apart. Approximately 22 cm below the center monitor was a 9-cm opening for the lens of a Panasonic camera. This camera was connected to a Panasonic VCR and a 15-inch monitor in an adjoining 6 m × 6 m control room. The experimenter used the camera and 15-inch monitor to observe toddlers’ looking times to the events. A specially designed software program, Habit 2000 (Cohen, Atkinson & Chaput, 2000), and a Macintosh G4 computer were used to present the auditory and visual stimuli and record toddlers’ looking time to the visual events.
Procedure
Toddlers were randomly assigned to either the Novel Word or the No Word condition.
Training session
During training, toddlers sat at the table with the experimenter while parents sat to one side and completed the MacArthur-Bates Communicative Development Inventories: Words and Sentences as well as the Places and Locations section of the MacArthur-Bates Communicative Development Inventories: Words and Gestures (Fenson, Dale, Reznick, Thal, et al., 1993a). To begin, the experimenter handed the toddler an object pair (e.g., the Lego dog and the Lego block) and allowed him/her to briefly play with the pair of objects before demonstrating how the objects fit together in a tight-fit relation. The experimenter demonstrated the tight-fit relation twice and invited the toddler to produce the action resulting in the tight-fit relation twice. If a toddler was unwilling to join the objects in the tight-fit relation, the parent was invited to do so. To encourage toddlers’ participation, the experimenter and parent clapped enthusiastically when the toddler joined the objects in the tight-fit relation.
In the Novel Word condition, the experimenter labeled the tight-fit relation as ‘keet’, prior to and immediately after joining the objects within a pair (e.g., ‘Watch, I am going to put the doggie keet’ … ‘See? I put the doggie keet!’ or ‘Can you put the doggie keet? … Yea! You put it keet!’).3
In the No Word condition, the experimenter described the event, prior to and after each demonstration of the relation, but did not provide a novel word (e.g., ‘I am going to put the doggie right here … See I put the doggie right there!’ or ‘Can you put the doggie there? … Yea! You put the doggie there.’).
Once toddlers had viewed the four demonstrations of the action resulting in a tight-fit relation with one pair of objects, the experimenter removed that object pair and presented the next object pair. The same procedure was used with all training object pairs. All toddlers viewed the training actions in a fixed order: the Lego dog being placed on the Lego block, the cork being placed in the bottle, the lid being placed on the cup, and the peg being placed in the block. For each action, toddlers in the Novel Word condition heard the novel word 8 times and toddlers in the No Word condition had their attention directed to the action 8 times. In sum, toddlers in the Novel Word heard the novel word 32 times, whereas toddlers in the No Word condition had their attention drawn to the action 32 times.
Preferential-looking session
Following the training session, toddlers were taken across the hall and tested, using a preferential-looking paradigm (Golinkoff, Hirsh-Pasek, Cauley & Gordon, 1987; Naigles, 1990). The toddler sat on his or her parent’s lap in front of the three computer monitors. To facilitate parent neutrality, the parent was seated facing a side wall, away from the monitors, while the toddler was seated sideways on the parent’s lap directly facing the monitors.
Toddlers in both conditions were presented with identical auditory and visual stimuli from this point forward. Before each trial, an attention-getter (a green, flashing, chiming circle) was presented on the middle monitor to center toddlers’ attention. Once toddlers attended to the center monitor, the experimenter, who was in the adjoining control room, depressed a computer key to start a trial. For each object (i.e., the peg, chicken, cup, ring), toddlers viewed two familiarization trials, a control trial, then two test trials. Toddlers viewed the events with the four objects in a fixed order during the preferential-looking session: peg, chicken, cup, ring.
The first familiarization trial began with a 2-s interval in which the monitors were blank while auditory input was presented from the center speaker (e.g., ‘See the peg.’). Next, the first event of a pair was presented on a side monitor (e.g., left monitor shows the peg being placed tightly in the block) while the auditory stimulus directed the toddler’s attention to the event (e.g., ‘What happens? Where does she put the peg?’). The second familiarization trial began with a slightly different 2-s auditory stimulus (e.g., ‘Another peg.’). The alternate event in the pair was presented on the opposite monitor (e.g., right monitor shows the peg being placed loosely on the block) while auditory input directed the toddler’s attention to this alternate event (e.g., ‘What happens now? Where does she put it?’). Each familiarization trial was approximately 10 s in duration.
Following the second familiarization trial, a control trial, approximately 10 s in duration, was presented to obtain toddlers’ baseline looking time to each action event in a pair. The control trial began with a 2-s auditory-only stimulus (e.g., ‘Both pegs.’). Both events in a pair were then presented simultaneously, appearing on the same monitor as they had during the familiarization trials, while auditory input encouraged toddlers to look at both events (e.g., ‘Oh, look – both pegs. What happens?’).
After the control trial, toddlers viewed a test trial. A 2-s auditory-only stimulus (e.g., ‘She puts it keet’) preceded the simultaneous presentation of both events in a pair. New auditory input followed: ‘Where does she put it keet? Keet. Look, she puts it keet.’ This 10-s test trial was presented a second time.
The monitor on which each event in a pair appeared was counterbalanced across participants. For one group of toddlers, the tight-fit event matching the novel word keet appeared on the left monitor for the peg and ring events and the right monitor for the chicken and cup events. For a second group of toddlers, the events matching the novel word appeared on the right monitor for the peg and ring events and on the left monitor for the chicken and cup events. In addition, which event in a pair was presented first during familiarization was also counterbalanced across participants.
Coding
The same experimenter (MPW) who recorded all toddlers’ online looking also coded toddlers’ looking time offline with a second program, SuperCoder for X (Hollich, 2003). Because the SuperCoder for X program allows frame-by-frame analysis of toddlers’ looking time to the two events in a pair, the offline looking times generated from the SuperCoder for X program were used in the analyses rather than the online looking times. The only exception were looking times from 6 toddlers, 4 in the Novel Word condition and 2 in the No Word condition, whose videos were too faded to transfer to the computer for coding. The average correlation of toddlers’ looking times during the control and two test trials for these two coding systems for a random sample of 5 toddlers was 0.873 with a range of 0.798–0.919. A second observer recoded a random sample of 8 toddlers (4 from each condition) using the SuperCoder for X program. The average correlation between the two observers was 0.97, with a range of 0.87–0.995.
RESULTS
Although 16 toddlers were originally assigned to both conditions, the removal of toddlers with extreme looking times or a side preference resulted in a final sample of 12 toddlers (6 males, 6 females) in the Novel Word condition and 13 toddlers in the Novel Word Control condition (5 males, 8 females). To ensure that toddlers in each condition were equivalent to one another with respect to language development, toddlers’ total production vocabulary, as reported by their parents on the MacArthur-Bates Communicative Development Inventories: Words and Sentences (Fenson et al., 1993b) was analyzed in a 2 (Condition: Novel Word vs. No Word) × 2 (Sex: Male vs. Female) between-subjects univariate analysis of variance (ANOVA). There was no significant difference in the number of words produced by toddlers in the Novel Word condition (M = 210.92, SE = 39.85) and those in the No Word condition (M = 194.77, SE = 38.29), F (1,21) = 0.10, p = ns. There were also no effects with sex, Fs < 0.13, ps = ns. Likewise, there was not a significant difference in the number of spatial words comprehended or produced by toddlers in the two conditions, Fs < 1.5, ps = ns, as reported by their parents on the Places and Locations section of the MacArthur-Bates Communicative Development Inventories: Words and Gestures. Similar numbers of toddlers in each condition were reported to comprehend in (N = 11 in the Novel Word condition, N = 11 in the No Word condition) and on (N = 12 and N = 10, respectively). An equal number of toddlers in each condition were reported to say in (N = 7, N = 7, respectively) and on (N = 7, N = 7, respectively). In sum, there was no evidence that toddlers in the Novel Word condition differed from those in the No Word condition in total productive vocabulary or in how much spatial language they had acquired in comprehension or production.
During the preferential-looking session, the familiarization trials were presented only to give toddlers an opportunity to examine each event in a pair individually, and for this reason toddlers’ looking time during these trials was not analyzed. Rather, the analyses were based on toddlers’ looking time during the control trial and the two test trials. In particular, the amount of time toddlers visually attended to the tight-fit action events during the control and test trials was compared across the four objects (i.e., peg, chicken, cup, ring). Toddlers’ looking time to the tight-fit event during a trial was converted to a proportion score by dividing their looking time to the tight-fit event by their total looking time during a trial. For the two test trials, the proportion score was calculated by computing the sum of toddlers’ looking time to the tight-fit event across the two test trials and dividing this sum by their total looking time during the two test trials. Thus, toddlers had a single proportion looking score for the two test trials for a given object. To normalize the data, toddlers’ proportion looking scores were converted to arcsine scores.
Toddlers’ proportion looking to the tight-fit event was analyzed in a 2 (Condition) × 2 (Sex) × 4 (Object: peg vs. chicken vs. cup vs. ring) × 2 (Trials: control vs. test) mixed-model ANOVA. Condition and sex were between-subject variables while object and trials were within-subject variables. Table 1 presents the mean and standard error proportion looking times to each tight-fit event during the control and test trials for toddlers in each condition. The analysis yielded a significant main effect of trials, F (1,21) = 12.53, p < 0.01, ηp2 = 0.37, but also a significant condition × trials interaction, F (1,21) = 6.91, p < 0.02, ηp2 = 0.25. As can be seen in Fig. 2, toddlers in the Novel Word condition demonstrated a significant increase in proportion looking time to the tight-fit events from the control trial (M = 0.49, SE = 0.004) to the test trials (M = 0.62, SE = 0.004), F (1,10) = 22.19, p < 0.01, ηp2 = 0.69. In contrast, toddlers in the No Word condition looked an approximately equal proportion of time to the tight-fit events during the control trial (M = 0.50, SE = 0.002) and test trials (M = 0.52, SE = 0.003), F (1,11) = 0.37, p = ns. Thus, only toddlers in the Novel Word condition attended significantly longer to the tight-fit event when hearing the novel word (i.e., during the test trials) than when only neutral linguistic input was presented (i.e., during the control trial). This result indicates that toddlers in the Novel Word condition had mapped the novel spatial word onto the tight-fit relation, looking significantly longer to the tight-fit event in a pair when hearing the novel word than when no novel word was presented. Thus, toddlers in the Novel Word condition provided evidence of learning to comprehend the novel word as referring to the tight-fit relation.4
Table 1.
Mean proportion looking time and (SE) to each novel tight-fit event during the control and the test trials for toddlers in the Novel Word and No Word conditions
| Novel Word condition |
No Word condition |
|||
|---|---|---|---|---|
| Control | Test | Control | Test | |
| Peg in block | 0.43 (0.08) | 0.55 (0.08) | 0.37 (0.06) | 0.40 (0.05) |
| Chicken on block | 0.44 (0.05) | 0.67 (0.06) | 0.37 (0.05) | 0.45 (0.07) |
| Cup in cup | 0.48 (0.09) | 0.56 (0.07) | 0.55 (0.05) | 0.61 (0.06) |
| Ring on pole | 0.61 (0.07) | 0.68 (0.09) | 0.70 (0.07) | 0.63 (0.06) |
Figure 2.

The proportion looking time to the tight-fit action events during the control and test trials for toddlers in the Novel Word and No Word conditions
The analysis also yielded a significant main effect of object (F (1,21) = 8.27, p < 0.01, ηp2 = 0.28) because toddlers demonstrated a longer proportion looking time to the ring events (M = 0.66, SE = 0.04) than to the peg (M = 0.44, SE = 0.05), chicken (M = 0.48, SE = 0.03) and cup tight-fit events (M = 0.55, SE = 0.04), all ps < 0.05. However, there were no significant interactions involving object, including no significant condition × trials × object interaction, F = 0.09, p = ns. Toddlers simply demonstrated longer proportion looking time to the ring tight-fit event across both types of trials than to other tight-fit events, perhaps because toddlers found the ring event to be more interesting than the events with the peg, chicken and cup. The analysis did not yield any other significant main effects or interactions.
DISCUSSION
The purpose of the current study was to explore whether English-learning toddlers have the ability to acquire and generalize a novel spatial word to an action resulting in a tight-fit spatial relation, given only limited experience with the novel word. The videotaped version of the peg tight-fit training event was included in the preferential-looking session to explore whether, at the very least, toddlers had learned to map the novel word onto one of the tight-fit training events. Novel tight-fit events were also presented to test toddlers’ ability to generalize the novel word.
The results indicate that only toddlers in the Novel Word condition, but not those in the No Word condition, exhibited a statistically longer proportion of looking to the tight-fit events from the control to the test trials. That is, only toddlers who had been trained with the novel word demonstrated a significant preference for the tight-fit event when hearing the novel word than when hearing general linguistic input without the novel word. Because toddlers in the No Word condition did not significantly increase their looking time during the test trials, the results cannot be due to a simple preference for tight-fit actions when hearing ‘keet’. Rather, the results are consistent with the claim that toddlers had learned to map the novel word onto a tight-fit event and had learned to generalize the novel word to novel instances of this relation.
These results are the first to provide direct evidence that toddlers of 21 months can learn to comprehend a novel word for a tight-fit action event when provided with only limited exposure to the novel word. The results are particularly impressive given that tight-fit is not lexically marked in English and that the tight-fit containment and tight-fit support events are described with in and on, respectively, in English. Nearly all the toddlers were reported by their parents to comprehend in and on, and seven of the twelve toddlers in the Novel Word condition produced these spatial words. The parental reports suggest that toddlers possessed the semantic categories of in and on, indicating that they came to the task with different labels for the training actions (i.e., in for the peg placed in the block and the cork placed in the bottle, and on for the Lego dog placed on the Lego block and the lid placed on the cup) than the novel word provided by the experimenter. Thus, in learning to map the novel word onto both tight-fit containment and tight-fit support action events, toddlers had to disregard the distinction between containment and support – relations that in English correspond to different semantic categories (i.e., in and on, respectively) –and focus instead on the tight-fit relation. Even though they may have had to relearn how to describe the training actions, toddlers displayed little difficulty in learning the novel word for the tight-fit relation and generalizing the novel word on this basis.
The results of the current study are consistent with other studies that have examined young children’s acquisition of spatial language. These previous reports show that young children can generalize a novel spatial term soon after first producing the term. The current results demonstrate that children’s comprehension of spatial language follows a similar developmental pattern as their production of spatial language. In addition, the current study is unique in demonstrating that toddlers can acquire and generalize a novel spatial word, given only a few minutes’ exposure to the word. Because toddlers generalized the novel word to tight-fit containment as well as tight-fit support events, toddlers were not simply substituting the novel word for spatial words they already possessed. Rather, toddlers provided evidence of attending to how the experimenter was using the novel word and learned that the novel word referred to an action resulting in a tight-fit spatial relation. Thus, by about 21–22 months, toddlers are at a developmental point at which they can readily learn and generalize words for spatial relations, even when they have not had experience with labeling a particular spatial relation.
Did toddlers in the Novel Word condition provide evidence of acquiring a novel semantic category consistent with the Korean semantic category of kkita? Toddlers did demonstrate the ability to map a novel word onto a specific instance of a tight-fit relation and to generalize the novel word to novel instances of tight-fit actions involving both containment and support relations. However, given the scope of the study, it is difficult to pinpoint the extent to which toddlers did actually acquire a semantic category of tight-fit consistent with the Korean semantic category of kkita. As can be seen in Table 1, even though there was no significant difference across items, toddlers in the Novel Word condition tended to demonstrate more of an increase in looking from control to test for some of the novel tight-fit events than other tight-fit events. The fixed presentation order of the objects may have influenced toddlers’ pattern of looking, explaining why toddlers demonstrated greater increases to the tight-fit event from control to test for some objects. What is more, toddlers demonstrated longer looking times to the ring events, suggesting a possible a priori preference for this event. Had the test order of the peg, chicken, cup and ring events been varied, toddlers might have demonstrated a different pattern of looking across the three novel tight-fit events. The results suggest that toddlers may have generalized the novel word more readily to some instances of tight-fit than to others. Such a result would not be surprising, given reports that young children produce errors when generalizing a novel spatial term (e.g., Choi and Bowerman, 1991) or that infants are more likely to map spatial terms onto typical examples of a relation prior to atypical examples of the relation (Meints, Plunket, Harris & Dimmock, 2002). The use of only three novel tight-fit events paired with the small sample size leads us to take a conservative stance: that English-learning toddlers of 21–22 months can map and generalize a novel word given relatively little experience with a novel word and thus possess the necessary precursors required for acquiring a novel semantic spatial category.
An additional question that arises from the results is how toddlers’ ability to generalize the novel word to novel instances of tight-fit actions relates to their existing semantic categories of in and on. Possibly, toddlers may have reorganized their semantic categories of in and on to accommodate the novel word for tight-fit events. Alternatively, toddlers may simply have added the novel word for tight-fit actions as a separate lexical item to their existing semantic spatial categories for in and on. In their everyday experiences, it is not uncommon for children to learn to classify the same object on a number of different bases (e.g., a yellow pen can be classified on the basis of color, shape or function). Findings reported by Clark (1997) show that young children display little difficulty in providing one label for an object in one setting but a different label for the same object in a different setting. Given the many ways in which an action event may be labeled (Gentner & Boroditsky, 2001), it seems critical that young children remain flexible in the labels they apply to an action. The current results provide experimental evidence that, given a novel word, children also are willing to reclassify actions and not only objects. The current findings also reveal that children can carry out such a reclassification given a few minutes’ training with different examples of the same relation. Thus, the current results demonstrate that young children require minimal experience to map and generalize a novel spatial term.
In addition to providing insight into how young children acquire language-specific semantic spatial categories, the results also point to the powerful effect of language on infants’ attention to and categorization of action events. The results show how a novel word presented in a naturalistic environment motivated toddlers to attend to a spatial relation that they normally disregard in their descriptions of the actions depicted. When English-learning infants of 10 and 18 months were tested on their ability to form a spatial category of tight-fit – one that grouped tight-fit containment and tight-fit support into the same category – they provided no evidence of forming a spatial category of tight-fit (Casasola & Cohen, 2002). In contrast, the toddlers in the current study provided evidence of treating tight-fit containment as equivalent to tight-fit support as referents for the novel spatial word. Thus, language appears to motivate young children to recognize as equivalent those actions that they previously were unable to group into a single category, supporting the notion that language can facilitate the acquisition of a particular concept (Bowerman & Choi, 2001; Casasola, 2005; Choi & Bowerman, 1991; Vygotsky, 1962).
Although the results begin to shed light on how young children acquire spatial language, the findings also raise a number of questions about this process. For one, toddlers in the current study were provided with abundant exposure to the novel word. The purpose of the study, however, did not center on toddlers’ ability to comprehend a novel spatial word given only a certain number of exposures. Rather, the study was designed to explore whether toddlers could simply comprehend a novel spatial word for a tight-fit relation when taught the novel spatial word. However, recent findings suggest that toddlers could have learned the novel word with less exposure to the novel word. Casasola & Wilbourn (2004) found that 14-month-old infants learn to link one novel word with a containment relation and a second novel word to a support relation with minimal experience, demonstrating that the ability to associate novel words to a spatial relation quickly is in place by 14 months, the same age at which infants learn to associate novel words to objects (Werker et al., 1998; Woodward et al., 1994). The current results also raise the question of how long toddlers might retain the novel word. Anecdotally, one parent reported that their child produced keet for several weeks following participation in the study. Although the parent’s comment suggests that toddlers’ production of the novel word extended beyond the testing session and laboratory, retention of the novel word across time should be examined systematically. This line of research could also address whether young children incorporate the novel word into their existing vocabulary. Finally, future research should explore how many and what types of examples of a spatial relation are optimal for toddlers to generalize a novel spatial word. Findings from infants’ categorization of objects demonstrate that the type of object categories that infants form is influenced by the types of exemplars presented during familiarization (Oakes, Coppage & Dingel, 1997; Quinn, Eimas & Rosenkranz, 1993). More recently, research on toddlers’ acquisition of adjectives also demonstrates that the exemplars provided during training influence how well the novel term is acquired (Waxman & Klibanoff, 2000). It seems reasonable then that the type of semantic spatial category formed by a child may also be influenced by the specific exemplars provided during training. In sum, although the current study begins to provide insight into how young children form language-specific semantic categories, additional research is still needed to further our understanding of this aspect of language acquisition.
Acknowledgments
This research was supported by NIH grant R03 HD43941-01 and a Hatch Grant from the College of Human Ecology at Cornell University to Marianella Casasola. We thank Jui Bhagwat, Amanda Drake, Kim Ferguson and Geunwon Kim for their help in offline coding of toddlers’ looking time, and the native Korean speakers for providing their ratings of ‘kkita’ for the training and test actions. We also wish to thank Virginia Gathercole and two anonymous reviewers for their helpful comments on an earlier version of the manuscript. We extend our deepest gratitude to the parents and toddlers for their time and willingness to participate and to A. W. and John Carlos Casasola for their help in piloting the study.
A portion of this research was presented at the 2003 Biennial Meeting of the Society for Research in Child development in Tampa, FL and at the Tenth International Congress for the Study of Child Language, Berlin, Germany, July 2005.
APPENDIX
Depicted below are selected frames of each event across the four objects used in the preferential-looking paradigm. Which event in a pair, the tight-fit or the loose-fit, was presented as the first familiarization trial was counterbalanced across participants. The monitor on which each event in a pair appeared was also counterbalanced across participants.



Footnotes
After transforming the data to arcsine scores, a box plot analysis indicated that these 5 toddlers (3 in the Novel Word condition, 2 in the No Word condition) still had extreme scores compared with the rest of the sample. These infants were removed from the final sample.
Because these infants did not attend to both events during the control and test trials, their looking times were not included in the analyses.
Note that although kkita is a main verb in Korean, the decision was made to present the novel word as a preposition (e.g., ‘I put the dog keet the block’) in order to use a syntactic structure that would be analogous to how English speakers normally describe these events (e.g., put the dog on the block).
When looking times to the peg and novel objects are analyzed separately, the same statistically significant effect of trial and condition x trial interaction are obtained. That is, for trials with only the peg or those with only the novel objects, toddlers in the Novel Word condition look significantly longer during the test trials than in control trials whereas toddlers in the No Word condition do not.
Contributor Information
Marianella Casasola, Cornell University.
Makeba Parramore Wilbourn, Cornell University.
Sujin Yang, Cornell University.
References
- Bowerman M. Learning a semantic system: What role do cognitive predispositions play? In: Rice M, Schiefelbusch R, editors. The teachability of language. Baltimore, MD: Paul H. Brookes; 1989. pp. 133–169. [Google Scholar]
- Bowerman M. Learning how to structure space for language: A cross-linguistic perspective. In: Bloom P, Peterson MA, Nadel L, Garrett MF, editors. Language and space. Cambridge, MA: MIT Press; 1996. pp. 385–436. [Google Scholar]
- Bowerman M, Choi S. Shaping meanings for language: Universal and language-specific in the acquisition of spatial semantic categories. In: Bowerman M, Levinson SC, editors. Language acquisition and conceptual development. Cambridge: Cambridge University Press; 2001. pp. 475–511. [Google Scholar]
- Casasola M. Can language do the driving? The effect of linguistic input on infants’ categorization of support spatial relations. Developmental Psychology. 2005;41:183–192. doi: 10.1037/0012-1649.41.1.183. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Casasola M, Cohen LB. Infant categorization of containment, support, and tight-fit spatial relationships. Developmental Science. 2002;5:247–264. [Google Scholar]
- Casasola M, Cohen LB, Chiarello E. Six-month-old infants’ categorization of containment spatial relations. Child Development. 2003;74:679–693. doi: 10.1111/1467-8624.00562. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Casasola M, Wilbourn MP. Fourteen-month-old infants form novel word-spatial relation associations. Infancy. 2004;6:385–396. doi: 10.1207/s15327078in0603_4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Choi S, Bowerman M. Learning to express motion events in English and Korean: The influence of language-specific lexicalization patterns. Cognition. 1991;41:83–121. doi: 10.1016/0010-0277(91)90033-z. [DOI] [PubMed] [Google Scholar]
- Choi S, McDonough L, Bowerman M, Mandler JM. Early sensitivity to language-specific spatial categories in English and Korean. Cognitive Development. 1999;14:241–268. [Google Scholar]
- Clark EV. Nonlinguistic strategies and the acquisition of word meanings. Cognition. 1974;2:161–182. [Google Scholar]
- Clark EV. Conceptual perspective and lexical choice in acquisition. Cognition. 1997;64:1–37. doi: 10.1016/s0010-0277(97)00010-3. [DOI] [PubMed] [Google Scholar]
- Cohen LB, Atkinson DJ, Chaput HH. Habit 2000: A new program for testing infant perception and cognition [Computer software] Austin: The University of Texas; 2000. [Google Scholar]
- Fenson L, Dale PS, Reznick JS, Thal D, Bates E, Pethick S, Reilly JS. MacArthur-Bates Communicative Development Inventories: Words and Gestures. Baltimore, MD: Paul H. Brookes Publishing; 1993a. [Google Scholar]
- Fenson L, Dale PS, Reznick JS, Thal D, Bates E, Pethick S, Reilly JS. MacArthur-Bates Communicative Development Inventories: Words and Sentences. Baltimore, MD: Paul H. Brookes; 1993b. [Google Scholar]
- Gentner D, Boroditsky L. Individuation, relativity, and early word learning. In: Bowerman M, Levinson S, editors. Language acquisition and conceptual development. Cambridge: Cambridge University Press; 2001. pp. 215–256. [Google Scholar]
- Golinkoff RM, Hirsh-Pasek K, Cauley KM, Gordon L. The eyes have it? Lexical and syntactic comprehension in a new paradigm. Journal of Child Language. 1987;14:23–45. doi: 10.1017/s030500090001271x. [DOI] [PubMed] [Google Scholar]
- Hespos SJ, Spelke ES. Conceptual precursors to language. Nature. 2004;430:453–456. doi: 10.1038/nature02634. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hollich G. SuperCoder (Version 1.5) [Computer software] 2003 Retrieved from http:/hincapie.psych.purdue.edu/Splitscreen/SuperCoder.dmg.
- McDonough L, Choi S, Mandler JM. Understanding spatial relations: Flexible infants, lexical adults. Cognitive Psychology. 2003;46:229–259. doi: 10.1016/s0010-0285(02)00514-5. [DOI] [PubMed] [Google Scholar]
- Meints K, Plunkett K, Harris PL, Dimmock D. What is ‘on’ and ‘under’ for 15-, 18-, and 24-month-old infants? Typicality effects in early comprehension of spatial prepositions. British Journal of Developmental Psychology. 2002;20:113–130. [Google Scholar]
- Naigles L. Children use syntax to learn verb meanings. Journal of Child Language. 1990;17:357–374. doi: 10.1017/s0305000900013817. [DOI] [PubMed] [Google Scholar]
- Oakes LM, Coppage DJ, Dingel A. By land or by sea: The role of perceptual similarity in infants’ categorization of animals. Developmental Psychology. 1997;33:396–407. doi: 10.1037//0012-1649.33.3.396. [DOI] [PubMed] [Google Scholar]
- Quinn PC, Eimas PD, Rosenkranz SL. Evidence for representation of perceptually similar natural categories by 3-month-old and 4-month-old infants. Perception. 1993;22:463–475. doi: 10.1068/p220463. [DOI] [PubMed] [Google Scholar]
- Sinha C, Thorseng LA, Hayashi M, Plunkett K. Comparative spatial semantics and language acquisition: Evidence from Danish, English, and Japanese. Journal of Semantics. 1994;11:253–287. [Google Scholar]
- Tomasello M. Learning to use prepositions: A case study. Journal of Child Language. 1987;14:79–98. doi: 10.1017/s0305000900012745. [DOI] [PubMed] [Google Scholar]
- Vygotsky LS. Thought and language. Cambridge, MA: MIT Press; 1962. [Google Scholar]
- Waxman SR, Klibanoff RS. The role of comparison in the extension of novel adjectives. Developmental Psychology. 2000;36:571–581. doi: 10.1037/0012-1649.36.5.571. [DOI] [PubMed] [Google Scholar]
- Werker JF, Cohen LB, Lloyd VL, Casasola M, Stager CL. Acquisition of word-object associations by 14-month-old infants. Developmental Psychology. 1998;34:1289–1309. doi: 10.1037//0012-1649.34.6.1289. [DOI] [PubMed] [Google Scholar]
- Woodward AL, Markman EM, Fitzsimmons CM. Rapid word learning in 13–18-month-olds. Developmental Psychology. 1994;30:553–566. [Google Scholar]