
Figure 1.
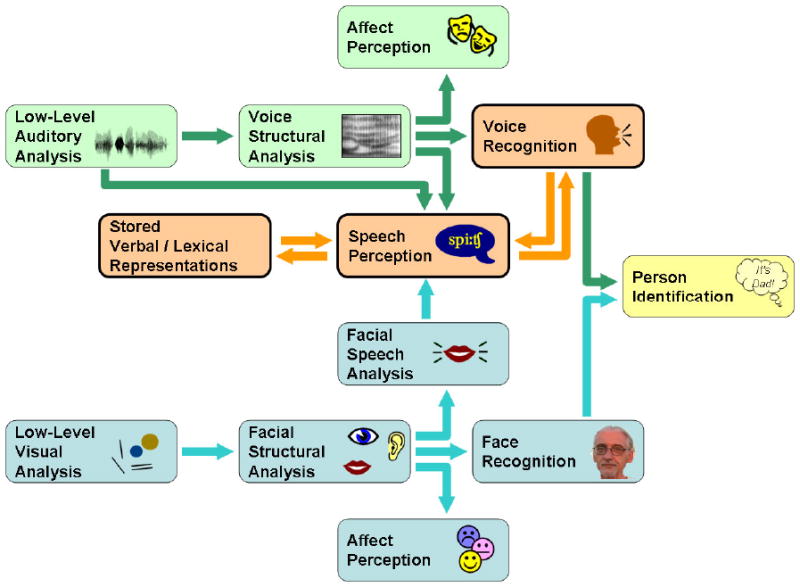
An integrated model of person perception from face and/or voice. Boxes represent perceptual, computational, or mnemonic modules. Arrows represent major directional pathways of shared information. Blue boxes and arrows denote the face-perception system. Green boxes and arrows denote the voice-perception system. Orange arrows indicate important routes of shared information in the voice-perception system lacking analogous connections in the face-perception system. Boxes with bold borders are those modules that rely on shared connections unique to the voice-perception system. The “Speech Perception” component should be broadly construed to represent all idiosyncratic features of the talker independent from the structure of his or her vocal tract. (This model illustrates only empirically supported pathways relevant to person identification).