
Fig. 9.
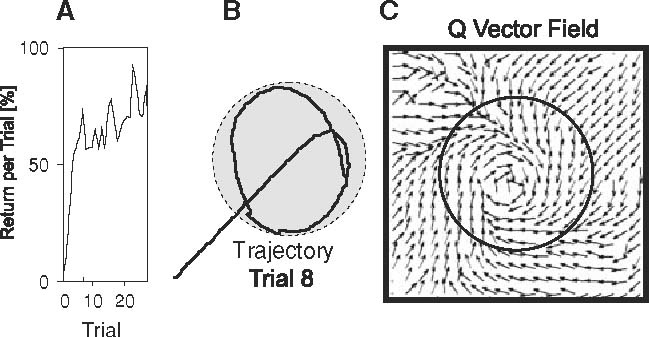
Example of a glass-filling RL task as mentioned in the Introduction, where the agent learns to recalibrate a prior learned target position. The simulated agent is supposed to learn approaching a glass (circles) to optimally pour liquid into it. The reward is defined as the amount of liquid filled into the glass. The agent starts exploring from a location close to the glass, reached for example by plain visual servoing or by learning from demonstration. a Return versus number of trials. b Example trajectory. c Q-vector field after 20 trials