

Abstract
Random graphs are useful models of social and technological networks. To date, most of the research in this area has concerned geometric properties of the graphs. Here we focus on processes taking place on the network. In particular we are interested in how their behavior on networks differs from that in homogeneously mixing populations or on regular lattices of the type commonly used in ecological models.
Keywords: complex networks, power-law degree distributions, contact process, random Boolean network, voter model
Introduction
The subject of random graphs dates to the late 1950s when Erdös and Renyi sat in Hungarian cafes and tried to imagine what a random pick from the collection of graphs with n vertices and m edges looks like. To answer this question it is easier to instead flip a coin with probability p = 2m/n(n - 1) of heads for each edge to determine if it is present. In this case there is interesting behavior when p = c/n: When c < 1 most connected components are small, with the largest of size O(log n) (in words, “of order log n”); when c > 1 there is a giant component of size asymptotically ρn. This phase transition inspired a lot of work in the subject, as did concepts from graph theory such as Hamiltonian circuits, matchings, chromatic number, Ramsey theory, etc. See Bollobás (1) or Janson et al. (2) for more on this.
The beginning of the twenty-first century saw a number of new motivations for the study of random graphs. The Kevin Bacon game taught us that the screen actors collaboration network was a “small world,” and made the phrase “six degrees of separation” famous. Statistical studies of the Internet (3), academic collaborations (4, 5, 6), and sex in Sweden (7) showed that the degree d of a randomly chosen vertex often followed a power law P(d = k) ∼ Ck -α rather than the Poisson distribution that occurs in the Erdös–Renyi model with p = c/n. For popular accounts see the books by Barabási (8) and Watts (9).
In the next section we will describe some of the random graphs at the center of this development. Their geometric properties, e.g., “Do they have a giant component?” and “What is the average distance between two points?,” are by now well-understood. See the books by Chung and Lu (10) and Durrett (11). Our focus will be on the behavior of processes (e.g., the spread of epidemics and opinions) on these networks.
Three Random Graphs
Small world graphs were first introduced by Watts and Strogatz (12). To construct their model, they take a one-dimensional ring Z mod n and connect all pairs of vertices that are distance m or less. They then rewire each edge with probability p by moving one of the ends at random, where the new end is chosen uniformly. This leads to a graph that has small diameter but, in contrast to the Erdös–Renyi model, has a nontrivial density of triangles. These are both properties that they observed in the collaboration graph of film actors, the power grid, and the neural network of the nematode C. elegans. The small world model has been extensively studied, although most investigators have found it more convenient to study the Newman and Watts (13) version in which all pairs of vertices that are distance m or less are connected, but in addition there is a density p of shortcuts that connect vertices to long-range neighbors chosen at random from the graph.
Barábasi and Albert (14) introduced the preferential attachment model. In this model, we successively add vertices. Each new vertex connects to m existing vertices, choosing them with probabilities proportional to their degrees. The fraction of vertices with degree k converges to a limit
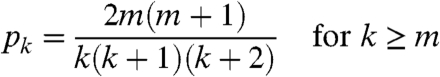 |
[1] |
If vertices are chosen with weight proportional to a + k with a > -1 then the limiting degree sequence has p k ∼ Ck -(3+a) [see Krapivsky, Redner, and Leyvrasz (15)]. When a≥0, this is equivalent to the rule: When a new edge is drawn, with probability a/(a + 1) we pick the vertex at random and with probability 1/(a + 1) we use preferential attachment. Cooper and Freize (16) show power-law degree distributions arise in a wide variety of related models.
The dynamic procedure used to grow the graphs provides an explanation for power-law behavior in some networks. However, if one only wants a graph with a power-law degree distribution, it is simpler to use the NSW recipe, see Newman et al. (17, 18). Given a degree distribution {p k: k≥0} we construct a random graph G n with vertex set {1,2,…,n} as follows: let d 1,…,d n be independent and have the distribution P(d i = k) = p k. We condition on the event E n = {d 1 + ⋯+d n is even} to have a valid degree sequence. If P(d i is odd)∈(0,1) then P(E n) → 1/2 as n → ∞, so the conditioning will have a little effect on the distribution of d i’s. Having chosen the degree sequence (d 1,d 2,…,d n), we allocate d i half-edges to the vertex i, and then pair those half-edges at random. This may produce self-loops or parallel edges, but when the degree distribution has finite variance, the probability these problems do not occur is bounded away from zero, so the reader who wants can condition on G n being a proper graph.
Two Epidemics
Epidemic models come in two basic flavors: the susceptible-infected-removed (SIR) in which suspectible individuals become infected at a rate equal to λ times the number of infected neighbors, remain infected for an exponentially distributed amount of time with mean 1, and then enter the removed class when they are no long susceptible to the disease. The SIR model on random graphs has a detailed theory due to its connection to percolation: Given neighbors x and y in the graph, we draw an edge from x to y with probability λ/(λ + 1), which is the probability that x (or y) will succeed in infecting the other during the time it is infected. The size of an epidemic starting with x infected is just the size of the component containing x in the new random graph. See Moore and Newman (19) for results on the small world, and Newman (20) for results on a graph with a fixed degree distribution.
We will be interested in the more difficult susceptible-infected-susceptible (SIS) epidemic model. In this model, at any time t each site x is either infected or healthy (but susceptible). An infected site becomes healthy at rate 1 independent of other sites and is again susceptible to the disease, while a susceptible site becomes infected at a rate λ times the number of its infected neighbors. Harris (21) introduced this model on the d-dimensional integer lattice and named it the contact process. See Liggett (22) for an account of most of the known results. In the SIS case, which we will usually refer to as the contact process, one typically cannot compute the critical value because the epidemic can backtrack and run into itself, whereas the SIR model is forced to move forward into the set of susceptibles and is essentially equivalent to a branching process.
Small Worlds
We consider the following version of the small world. Start with a circle Z mod n and connect x to all vertices x - m,…x + m where the addition is done modulo n. The number of sites n is required to be even so that one can partition the n vertices into n/2 pairs. Consider all such partitions and then pick one uniformly at random. When m = 1 this construction of a graph with diameter ∼ log 2 n dates back to Bollobás and Chung (23), 10 years before Watts and Strogatz (12). We will call this the BC small world.
The reason for insisting that all individuals have exactly one long-range neighbor is that we can define an associated big world graph 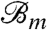 that is nonrandom. The graph can be succinctly described as the free product Z ∗ {0,1}, where the second factor is Z mod 2. Elements of the free product have the form z
01z
11…1z
k where z
i∈Z - {0} for 0 < i < k. In words, this is the point you reach by moving by z
0 in the first copy of Z, going down a long-range edge, moving sideways by z
1, going down a long-range edge, etc. The big world encapsulates the heuristic that in the beginning stages of the epidemic, an infection transmitted across a long-range edge brings it to a new uninfected part of the space.
that is nonrandom. The graph can be succinctly described as the free product Z ∗ {0,1}, where the second factor is Z mod 2. Elements of the free product have the form z
01z
11…1z
k where z
i∈Z - {0} for 0 < i < k. In words, this is the point you reach by moving by z
0 in the first copy of Z, going down a long-range edge, moving sideways by z
1, going down a long-range edge, etc. The big world encapsulates the heuristic that in the beginning stages of the epidemic, an infection transmitted across a long-range edge brings it to a new uninfected part of the space.
Following Durrett and Jung (24), who proved the three results we will state in this section, we will consider the discrete-time contact process. On either the small world or the big world, an infected individual lives for one unit of time. During its infected period it will infect some of its neighbors. All infection events are independent, and each site that receives at least one infection is infected at the next time step. A site infects itself or its short-range neighbors, each with probability α/(2m + 1)d. It infects its long-range neighbor with probability β. Let λ = α + β and r = α/β We are interested in the phase diagram as a function of (α,β), but in some cases we fix the ratio 0 < r < 1 and vary λ.
The number of sites within distance r of a given site in the big world grows exponentially fast, so it is natural to guess that its contact process will behave like the contact process on a tree. Consider a tree in which each vertex has the same degree, let 0 be a distinguished vertex (the origin) of the tree, and let 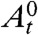 be the set of infected sites at time t on the tree starting from 0 occupied. For the contact process on the tree or on the big world, we can define two critical values:
be the set of infected sites at time t on the tree starting from 0 occupied. For the contact process on the tree or on the big world, we can define two critical values:
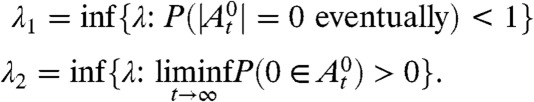 |
We call λ 1 the weak survival critical value and λ 2 the strong survival critical value. Pemantle (25) showed that for homogeneous trees where every vertex has at least four neighbors, λ 1 < λ 2. Liggett (26) then extended Pemantle’s result to trees with degree 3 by finding numerical bounds on the two critical values and thus showing that they are different. Later Stacey (27) found an elegant proof that did not rely on numerical bounds.
Theorem 1.
For each ratio r = α/β∈(0,1) there is an M such that for all m≥M, λ 1 < λ 2 for the contact process on
.
Durrett and Jung (24) were forced to take the range m to be large because the result is proved, as Pemantle did, by getting upper bounds on λ 1 and lower bounds on λ 2.
Having established the existence of two phase transitions on the big world, our next question is: How does this translate into behavior of the contact process on the small world? We will use B
t to denote the contact process on the big world and ξ
t for the contact process on the small world. Let 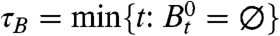 and
and 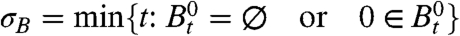 .
.
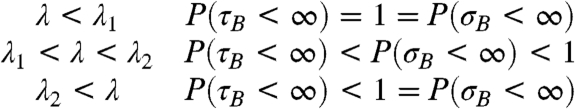 |
In words, there is positive probability that the process survives for all time when λ > λ 1, but only for λ > λ 2 are we certain that 0 will become infected when the process does not die out.
Let 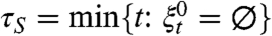 and
and 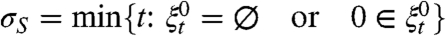 .
.
Theorem 2.
Writing ⇒ for convergence in distribution as n → ∞ we have
τ S is stochastically bounded above by τ B and τ S⇒τ B.
σ S is stochastically bounded above by σ B and σ S⇒σ B.
Combined with our table, this result shows that when λ 1 < λ < λ 2 the contact process survives with positive probability, but if it does it may take a time that grows with n until the origin is infected for the first time. Thus from the standpoint of an observer on the graph, the epidemic appears to die out, but then it comes back much later. To our knowledge this phenomenon has not been noticed by people simulating the process.
Because the small world is a finite graph, the infection will eventually die out. However, by analogy with results for the d-dimensional contact process on a finite set, we expect that if λ > λ 1 and the process does not become extinct quickly, it will survive for a long time. Durrett and Liu (28) showed that the supercritical contact process on the circle Z mod n survives for an amount of time of order exp(cn) starting from all ones, while Mountford (29) showed that the supercritical contact process on the torus (Z mod n)d survives for an amount of time of order exp(cn d).
On any graph with n nodes and ≤ Cn edges, the infection cannot persist for longer than O(e cn) because there is probability ≥e -γn that in the next unit of time all sites become healthy and no infections occur. Durrett and Jung (24) were only able to prove the last conclusion for a modification of the small world contact process where, in addition to the short- and long-range infections, at each time step each infected site it will with probability γ infect a vertex chosen uniformly random vertex from the entire grid.
From a modeling point of view, this mechanism is reasonable. In addition to long-range connections with friends at school or work, one has random encounters with people one sits next to on airplanes or meets while shopping in stores. The strategy for establishing prolonged survival is to show that if the number of infected sites drops below ϵn, it will with probability≥1 - C exp(-γn) increase to ≥2ϵn before dying out. To do this we use the random connections to spread the particles out so that they can grow independently. Ideally one would use the long-range connections (instead of the random connections) to achieve this. However, one has to deal with unlikely but annoying scenarios such as all infected individuals being long-range neighbors of sites that are respectively short-range neighbors of each other.
Theorem 3.
Consider the modified contact process on the small world described above. If λ > λ 1, the lower critical for the contact process on
and we start with all individuals infected, then there is a constant c > 0 so that the probability the infection persists to time exp(cn) tends to 1 as n → ∞.
Power-Law Degree Distribution
Pastor-Satorras and Vespignani (30, 31, 32) have made an extensive study of the contact process on graphs with power-law degree distributions, P(d i = k) ∼ Ck -α, using mean-field methods. Their nonrigorous computations suggest the following conjectures about λ c the threshold for “prolonged persistence” of the contact process.
If α ≤ 3, then λ c = 0.
If 3 < α ≤ 4, then λ c > 0 but the critical exponent β, which controls the rate at which the equilibrium density of infected sites goes to 0, satisfies β > 1.
If α > 4, then λ c > 0 and the equilibrium density ∼C(λ - λ c) as λ↓λ c, i.e. the critical exponent β = 1.
Gómez-Gardeñes et al. (33) have recently extended their arguments to the bipartite case, which they think of as a social network of sexual contacts between men and women. They define the polynomial decay rates for degrees in the two sexes to be γ M and γ F and argue that the epidemic is supercritical when the transmission rates for the two sexes satisfy
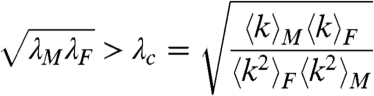 |
[2] |
where the angle brackets indicate expected value and k is shorthand for the degree distribution. Hence λ c is positive when γ M, γ F > 3. Chatterjee and Durrett (34) have shown that the conclusions described above are not correct: λ c = 0 for 3 < α < ∞. The argument extends easily to the bipartite case.
Theorem 4.
Consider a Newman, Strogatz and Watts random graphs G n on the vertex set {1,2,…,n}, where the degrees d i satisfy P(d i = k) ∼ Ck -α as k → ∞ for some constant C and some α > 3, and P(d i ≤ 2) = 0. Let
denote the infected sites in the contact process on the random graph G n starting from all sites infected. Then for any value of the infection rate λ > 0, there is a positive constant p(λ) so that for any δ > 0
[3]
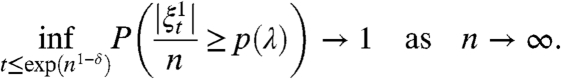
The assumption P(d i ≤ 2) = 0 is not really necessary but is convenient, because it implies that P(G n is connected) → 1 as n → ∞. Presumably λ c = 0 for 1 < α ≤ 3, but the geometry of the graph changes, so we restricted our attention to the range in which the conclusion is the most surprising. Berger, Borgs, Chayes, and Saberi (35, 36) proved a similar result for the preferential attachment model of Barábasi and Alberts with α = 3 and for the generalization mentioned above that is a combination of preferential and random attachment.
Physicists “mean-field” arguments are usually reliable when dimension is sufficiently large, and our locally tree-like random graph is essentially infinite dimensional, so what went wrong? Let ρ k denote the fraction of sites of degree k occupied in equilibrium, and let θ(λ) be the probability that a randomly chosen edge points to an infected site. The conclusions of Pastor-Satorras and Vespignani cited above are based on writing two equations:
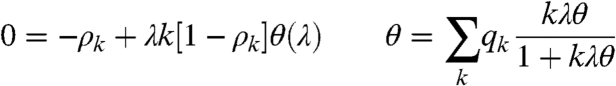 |
where q
k = kp
k/μ with 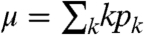 .
.
The second equation is a self-consistency equation. The “size-biased distribution” q k appears because when one picks an edge at random, vertices with degree k are k times as likely to be chosen. The first equation is the problem. It assumes that the state of a neighbor of a site is independent of the fact that it is vacant. This is rarely exactly true, but in high dimensions it is usually close enough to the truth to end up the right qualitative predictions. However, in this case it is not.
The proof of Theorem 4 is not difficult. One first shows that if λk 2≥50 and we consider a vertex with degree k and all of its neighbors to make a star graph then the infection persists for time exp(kλ 2/100) with high probability. Let ϵ > 0 and consider the vertices with degree ≥n ϵ, which we call stars. Infection at a star persists for time exp(n ϵ λ 2/100). The graph has diameter of order log n, so the probability a star can infect another by a chain of O(log n) events is ≥n -b for some b < ∞. These observations and comparison with simple random walk with positive drift imply that for time ≥ exp(cn -(1-δ)) most of the stars are infected.
To complete the proof we have to get a positive lower bound on the set of infected sites. To do this we will use the “self-duality” of the contact process. To state this relationship let 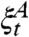 denote the process with
denote the process with 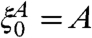 . In this notation, “self-duality” is
. In this notation, “self-duality” is
| [4] |
This is most conveniently proved by representing the process using a “graphical representation,” which is a sort of space-time percolation process, and noting that each side of the equation is the probability of a path from A × {0} to B × {t}. See Griffeath (37). We are mainly interested in the special case A = {1,…,n}, B = {x}. In this case, we have
| [5] |
To get a lower bound on the number of the density of occupied sites we show that if starting from x the process can infect a vertex with degree ≥λ
-(2+δ) then with high probability 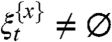 for a long time.
for a long time.
Having shown that the contact process survives for a long time, we can define a quasi-stationary distribution by the state of 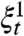 at t = exp(n
1/2). Let ρ
n(λ) be the expected value of the fraction of sites occupied in this measure. Berger et al. (35) show that for the contact process on their preferential attachment graphs, there are positive, finite constants so that
at t = exp(n
1/2). Let ρ
n(λ) be the expected value of the fraction of sites occupied in this measure. Berger et al. (35) show that for the contact process on their preferential attachment graphs, there are positive, finite constants so that
In the language of statistical physics, they are bounding the critical exponent β that describes the power at which ρ n(λ) goes to 0.
The powers c and C are not given explicitly in (35). In contrast, Chatterjee and Durrett (34) get reasonably good numerical bounds.
Theorem 5.
Suppose α > 3. There is a λ 0 > 0 so that if 0 < λ < λ 0 and 0 < δ < 1, then there exists two constants c(α,δ) and C(α,δ) so that as n → ∞
[6]
When α > 3 and δ is small, the power in the upper bound is > 2 so the critical value β never takes its mean-field value of 1. Based on the intuition that the infection will survive if, and only if, it reaches a vertex with degree λ -2, the correct power in Theorem 5 should be 1 + 2(α - 2), i.e., the upper bound needs some improvement.
Chaos in an Epidemic Model
The inspiration for this model arose more than 20 years ago. I had just moved to Ithaca, New York, and the Northeast was in the midst of a gypsy moth infestation that was killing many oak trees. For all of one summer, my wife and I destroyed egg masses, picked larvae off of trees, and put bands of sticky tape to catch them when they came down at night. When the next summer came, the outlook for the trees seemed bleak, but suddenly all of the larvae were dead, victims of an epidemic of the nuclear polyhedrosis virus.
To create a model, suppose that G n is a graph with n vertices. Thinking of upstate New York it would be most natural to consider G n to be a 2D lattice, and to resist the urge to identify the borders of the state to make a torus. Durrett and Remenik (38) have proved results for the d-dimensional case, but to keep with the theme of this paper and to allow us to do explicit calculations, we will suppose G n is a random 3-regular graph. We use discrete time, where t = years, because moths lay eggs that hatch the next year. Because the epidemic spreads quickly within a year, we formulate the process as an alternation of two mechanisms.
An occupied site gives rise to a Poisson mean β number of offspring sent to locations chosen at random from the entire graph.
Each site is infected with a small probability α n. If the site is occupied then the infection spreads and wipes out the connected component of occupied sites containing that vertex.
A similar system was considered earlier by Richards and coworkers (39, 40). They were primarily interested in the evolutionary response of individuals to this situation.
A random 3-regular graph looks locally like a tree. On this tree the critical probability for percolation is 1/2. If the fraction of occupied sites is < 1/2 then all components are small, while if p > 1/2 there is a “giant component” that contains a positive fraction of the graph, and the size of this component can be computed explicitly. This reasoning suggests that in the limit as n → ∞ the fraction of occupied sites in generation n, p n, will satisfy p n+1 = h(p n), where h(p) = g(f(p)) with f and g defined as follows:
Growth. If density of occupied sites is p before growth then density after is
| [7] |
Epidemic. Because the infection probability per site, α n, is small, if n is large then it is likely that only members of the giant component will be killed. A branching process calculation shows that if the density before infection is q the density after is
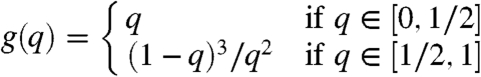 |
[8] |
Theorem 6.
Suppose α n → 0 and α n log n → ∞. If we start in product measure with density p, densities in process at times n≥0 on graph converge in probability to h n(p).
As β increases, the behavior of the process changes:
If β ≤ 1 then the concave function f(p) < p for all p > 0, so h n(p) → 0.
If 1 < β ≤ 2 log 2 then starting from a small positive p, f n(p) increases to a fixed point p ∗ ≤ 1/2.
If β > 2 log 2 then the fixed point p ∗ > 1/2 and the system becomes chaotic, in a sense that we will make precise.
Note that the system goes from having an attracting fixed point to chaos, and it does not follow the period doubling route to chaos found in the family of logisitic maps: x → βx(1 - x). This behavior is called a border collision bifurcation [see, e.g., Nusse et al. (41)].
To prove that the system is chaotic we use a result of Li and Yorke (42), which says “period 3 implies chaos.”
Theorem 7.
If there is a point with h 3(c) ≤ c < h(c) < h 2(c) then
For every k there is a point with period k.
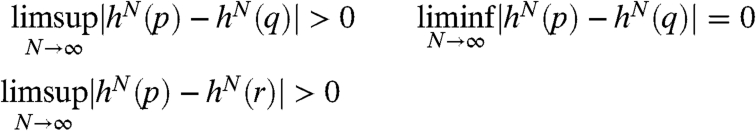
Using this result, we can easily show that
Theorem 8.
If β > 2 log 2 then the map is chaotic.
The proof is simple. Let a 0 = f -1(1/2) and c = f -1(a 0). Clearly c < f(c) = a 0 < f 2(c) = 1/2. We need only check f(1/2) < a 0.
A more satisfying notion of chaos is that the system has an absolutely continuous stationary distribution. Lasota and Yorke (43) have shown
Theorem 9.
There is an absolutely continuous invariant measure if
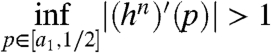
Using this result with some computer calculations we can show that the condition holds for n = 3 if β∈(2 log 2,2.48]. We believe that there is a stationary distribution for all β > 2 log 2, but we do not think that this result is sufficient to prove the desired conclusion.
Random Boolean Networks
Random Boolean networks were originally developed by Kauffman (44) as an abstraction of genetic regulatory networks. In our version of his model, the state of each node x∈V n ≡ {1,2,…,n} at time t = 0,1,2,… is η t(x)∈{0,1}, and each node x receives input from r distinct nodes y 1(x),…,y r(x), which are chosen randomly from V n∖{x}.
We construct our random directed graph G n on the vertex set V n = {1,2,…,n} by putting oriented edges to each node from its input nodes. To be precise, we define the graph by creating a random mapping ϕ: V n × {1,2,…,r} → V n, where ϕ(x,i) = y i(x), such that y i(x) ≠ x for 1 ≤ i ≤ r and y i(x) ≠ y j(x) when i ≠ j, and taking the edge set E n ≡ {(y i(x),x): 1 ≤ i ≤ r,x∈V n}. Thus our random graph G n has uniform distribution over the collection of all directed graphs on the vertex set V n in which each vertex has in-degree r. Once chosen the graph remains fixed through time. The rule for updating node x is
| [9] |
where the values f x(v), x∈V n, v∈{0,1}r, chosen at the beginning and then fixed for all time, are independent and = 1 with probability p.
A number of simulation studies have investigated the behavior of this model. See Kadanoff et al. (45) for survey. Flyvberg and Kjaer (46) have studied the degenerate case of r = 1 in detail. Derrida and Pommeau (47) have argued that for r≥3 there is a phase transition in the behavior of these networks between rapid convergence to a fixed point and exponentially long persistence of changes, and they identified the phase transition curve to be given by the equation r·2p(1 - p) = 1. The networks with parameters below the curve have behavior that is “ordered,” and those with parameters above the curve have “chaotic” behavior. Since chaos is not healthy for a biological network, it should not be surprising that real biological networks avoid this phase. See Kauffman (48), Shmulevich et al. (49), and Nykter et al. (50).
To explain the intuition behind the conclusion of Derrida and Pomeau (47), we define another process {ζ t(x): t≥1} for x∈V n, which they called the annealed approximation. The idea is that ζ t(x) = 1 if η t(x) ≠ η t-1(x), and ζ t(x) = 0 otherwise. If the state of at least one of the inputs y 1(x),…,y r(x) into node x has changed at time t, then the state of node x at time t + 1 will be computed by looking at a different value of f x. If we ignore the fact that we may have used this entry before, we get the dynamics of the threshold contact process
| [10] |
and ζ t+1(x) = 0 otherwise. Conditional on the state at time t, the decisions on the values of ζ t+1(x), x∈V n, are made independently.
We content ourselves to work with the threshold contact process, because it gives an approximate sense of the original model, and we can prove rigorous results about its behavior. To simplify notation and explore the full range of threshold contact processes we let q ≡ 2p(1 - p) and suppose 0 ≤ q ≤ 1.
As mentioned above, it is widely accepted that the condition for prolonged persistence of the threshold contact process is qr > 1. To explain this, we need to introduce the dual process, and for this it is convenient to rewrite our process as set-valued ξ t = {x: ζ t(x) = 1}. The dual coalescing branching process operates as follows: If x is occupied at time t, then with probability q it gives birth onto all of the sites y 1(x),…,y r(x), and with probability 1 - q no birth from x occurs. All sites that receive at least one birth will be occupied at time t + 1. The two processes satisfy the following duality relationship:
| [11] |
Again taking A = {1,2,…,n} and B = {x}, we see that the probability x is occupied at time t is equal to the probability that the dual process has not died out. At small times, the dual will behave like a branching process in which an individual has r children with probability q and no children with probability 1 - q. The mean number of children is qr. If qr > 1 the branching process is supercritical and the probability of no extinction is ρ = 1 - θ where the extinction probability θ is the root in [0,1) of
| [12] |
Theorem 10.
Let
be the threshold contact process with
. Suppose q(r - 1) > 1 and let δ > 0. Then there is a positive constant C(δ) so that as n → ∞
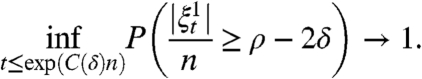 |
This result and Theorem 11 are from Chatterjee and Durrett (51). The key to studying the survival of the dual is an “isoperimetric inequality”. Let 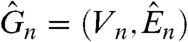 be the graph obtained from our original graph G
n = (V
n,E
n) by reversing the orientation of the edges. Given a set U⊂V
n, let
be the graph obtained from our original graph G
n = (V
n,E
n) by reversing the orientation of the edges. Given a set U⊂V
n, let
where x → y means 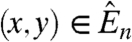 . Note that U
∗ can contain vertices of U. The idea behind this definition is that if U is occupied at time t in the coalescing branching process, then the vertices in U
∗ may be occupied at time t + 1.
. Note that U
∗ can contain vertices of U. The idea behind this definition is that if U is occupied at time t in the coalescing branching process, then the vertices in U
∗ may be occupied at time t + 1.
Lemma.
Let E(m,k) be the event that there is a subset U⊂V n with size |U| = m so that |U ∗| ≤ k. Given η > 0, there is an ϵ 0(η) > 0 so that for m ≤ ϵ 0 n
In words, the isoperimetric constant for small sets is r - 1. It is this result that forces us to assume q(r - 1) > 1 in Theorem 10. By using another strategy for guaranteeing persistence based on the locally tree-like nature of the graph, we are able to show:
Theorem 11.
Suppose qr > 1. If δ 0 is small enough, then for any 0 < δ < δ 0, there are constants C(δ) > 0 and B(δ) = (1/8 - 2δ) log(qr - δ)/ log r so that as n → ∞
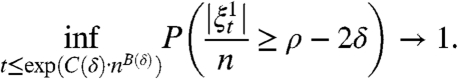
We believe the correct result is that the process persists for time O(e cn) when qr > 1, but this seems to be a difficult problem.
Voter Models
Diseases are not the only things that spread through networks. Opinions, gossip, and information do as well. A simple model for the dynamic evolution of two opinions 0 and 1 (think of Democrats and Republicans) was introduced 35 years ago by Clifford and Sudbury (52) and Holley and Liggett (53) on the d-dimensional integer lattice Z d. Each site at times of a rate one Poisson process decides to change its mind, and when it does, it adopts the opinion of a randomly chosen neighbor. One can also formulate a slightly different process in terms of the edges of the graph. Each edge becomes active at rate one. When it is active, one endpoint is chosen at random, and the voter there adopts the opinion at the other end. On a graph in which all vertices have the same degree, the two recipes give the same result (run on slightly different time scales), but in general they are different, and, as we will see, the edge voter model is considerably simpler than the vertex voter model.
The key to the study of the voter model is again duality. Let ζ
t(x) be the opinion of x at time t. Either of the two voter models can be constructed by having a Poisson process for each oriented edge (x,y), so that when a Poisson arrival occurs we draw an arrow from x to y and the voter at x imitates the one at y. In the vertex voter model, the rate for the (x,y) Poisson process is λ(x,y) = 1/d(x), where d(x) is the degree of x. In the edge voter model, it is λ(x,y) = 1/2. Given a starting point x and time t, we can define a dual process 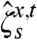 that starts at x and time t and works backwards in time, jumping when it encounters the tail of an arrow. It follows from the definition that
that starts at x and time t and works backwards in time, jumping when it encounters the tail of an arrow. It follows from the definition that
To convert this into the duality equation we have seen twice before, let 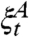 be the set of sites with opinion 1 at time t when initially
be the set of sites with opinion 1 at time t when initially 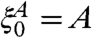 . Let
. Let 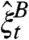 be the coalescing random walk system in which (i) a particle at x jumps to y at rate q(x,y), (ii) two particles on the same site coalesce to 1, and (iii)
be the coalescing random walk system in which (i) a particle at x jumps to y at rate q(x,y), (ii) two particles on the same site coalesce to 1, and (iii) 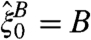 . With these definitions we again have:
. With these definitions we again have:
| [13] |
Thus to study the voter model it suffices to investigate the coalescing random walk.
To set the stage for the discussion of the voter model on random graphs, we will begin by considering the voter model on d-dimensional integer lattice with edges connecting each point to it 2d nearest neighbors. Holley and Liggett (53) have shown
Theorem 12.
In d ≤ 2 P(ζ t(x) ≠ ζ t(y)) → 0 while in d≥3 there is a one-parameter family of stationary distributions ν p, which can be obtained by taking the limit as t → ∞ starting from product measure, i.e., {ζ 0(x) = 1} are independent and have probability p.
This result follows from the behavior of simple random walk on Z
d. In d ≤ 2 two random walks will eventually hit, while in d≥3 there is positive probability that they never do. Letting |S| denote the number of points in a set S, and 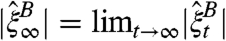 , which exists by monotonicity, duality tells us that
, which exists by monotonicity, duality tells us that
The voter model on the torus Λ = (Z mod L)d will eventually reach consensus. Let N = L
d and 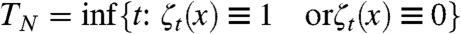 . Cox (54) has proved the following
. Cox (54) has proved the following
Theorem 13.
If we let
then T N/s N converges in distribution to a limit.
If we pick two sites x,y∈Λ at random then in d≥2 their coalescence time
has
where κ = 2/π in d = 2 and
in d≥3 where p n(x,y) is the transition probability of simple random walk.
In d≥3 if we start from product measure and observe the process at time t N with 1 ≪ t N ≪ N then the system looks like the stationary distribution ν p.
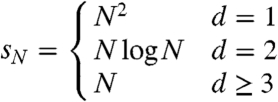
In the language of Markov chains ν p is a quasi-stationary distribution for the voter model on the torus.
Turning to random graphs, we begin with BC small world, 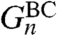 . All vertices have degree 3, so the two voter models have the same properties, and we study the site version. The first step in doing that is to consider what happens in the coalescing random walk when B = {x,y}. Let X
t and Y
t be independent random walks starting from x and y that jump at rate 1 and go to each of the three neighbors with probability 1/3. Let P
π×π denote the law of the process (X
t,Y
t) when X
0 and Y
0 are chosen independently at random from the graph according to the stationary distribution π(x) = 1/n. Let
. All vertices have degree 3, so the two voter models have the same properties, and we study the site version. The first step in doing that is to consider what happens in the coalescing random walk when B = {x,y}. Let X
t and Y
t be independent random walks starting from x and y that jump at rate 1 and go to each of the three neighbors with probability 1/3. Let P
π×π denote the law of the process (X
t,Y
t) when X
0 and Y
0 are chosen independently at random from the graph according to the stationary distribution π(x) = 1/n. Let 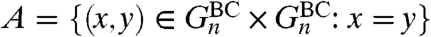 , and let P
A = P
π×π(·|X
0 = Y
0). Let T
A = min{t: X
t = Y
t} be the hitting time of A, and let
, and let P
A = P
π×π(·|X
0 = Y
0). Let T
A = min{t: X
t = Y
t} be the hitting time of A, and let 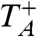 be the return time, i.e., the first time X
t = Y
t after the first jump occurs. Applying a theorem of Kac [see (3.3) in Chapter 6 of Durrett (55)] to the embedded discrete time chain and recalling that jumps in (X
t,Y
t) occur at rate 2,
be the return time, i.e., the first time X
t = Y
t after the first jump occurs. Applying a theorem of Kac [see (3.3) in Chapter 6 of Durrett (55)] to the embedded discrete time chain and recalling that jumps in (X
t,Y
t) occur at rate 2,
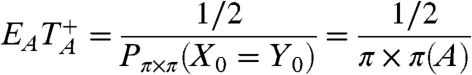 |
[14] |
From this we see that the for the BC small world, or any random graph with n vertices all of which have the same degree, 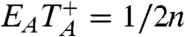 .
.
To get from this to the quantity that we really want, let T mix be the mixing time for the random walk:
where p
t(x,y) is the transition probability of the random walk and the total variation distance is 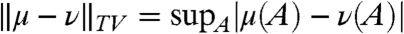 . I claim that
. I claim that
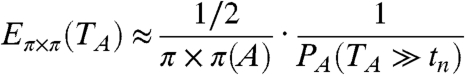 |
[15] |
This is the Poisson clumping heuristic of Aldous (56): The naive waiting time between returns is 1/(2π × π(A)), but this must be corrected for by multiplying by the clump size, i.e., the expected number returns that happen soon after the first one.
Locally the BC small world looks like a tree in which all vertices have degree 3, so
The mixing time for the random walk on the BC small world is O(log n) [see Theorem 6.3.4 in Durrett (11)]. Since T mix = o(n), Proposition 23 of Aldous and Fill (57) implies that
Intuitively, if the random walks have not hit by time ns and K n → ∞ slowly then at time ns + K n T mix the two walkers are distributed according to π, and so
which is the lack of memory property that characterizes the exponential. For more on this see the proof of Theorem 6.8.1 in Durrett (11).
By working harder with this argument one can show:
Theorem 14.
Pick m sites at random and start coalescing random walks at these locations. The number of particles at time nt converges to Kingman’s coalescent, which makes transitions from k to k - 1 at rate k(k - 1)/2.
Let q
i,j(t) be the transition probability of Kingman’s coalescent. Since 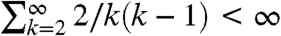 we can start Kingman’s process at infinity. In Cox’s work, T
N/s
N⇒τ where
we can start Kingman’s process at infinity. In Cox’s work, T
N/s
N⇒τ where
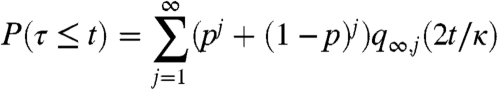 |
In words, if the dual coalescing random walk starting from all sites on the torus occupied has been reduced to k particles, then for consensus to hold all k walkers must sit on sites with the same value. This result is presumably true on the BC small world, but to finish the proof one must investigate the big bang that occurs in the coalescent starting with all sites occupied at time 0 [see Section 4 in Cox (54)].
Formula 14 in Sood and Redner (58) asserts that for the vertex random walk on a Newman Strogatz Watts (NSW) random graph with a power-law degree distribution p k ∼ Ck -α
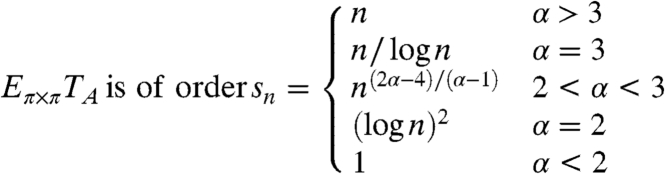 |
These graphs are rather ugly when α < 2. There are vertices of degree n 1/(α-1)≫n, so there are numerous self-loops and parallel edges. van der Hofstad et al. (59) have shown that the distance between two randomly chosen vertices is 2 with probability p and 3 with probability 1 - p. For this reason we will not consider the ultrasmall worlds with α < 2 or the borderline case α = 2.
To begin to prove Sood and Redner’s claims for α > 2, we note that the reasoning in refs. 14 and 15 applies in general.
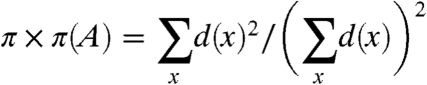 |
To determine the asymptotics of π × π(A) we note
If α > 2 then
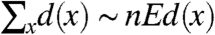
If α > 3 then Ed(x)2 < ∞ so
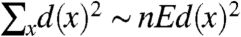 .
.If α = 3 then using (5.5) in Chapter 1 of Durrett (53) with b n = n log n shows that
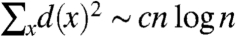
- When 2 < α < 3, Ed(x) < ∞ but P(d(x)2 > k) ∼ ck -(α-1)/2, so d(x) is in the domain of attraction of a stable law of index (α - 1)/2, and
where Y is a positive stable law with index (α - 1)/2.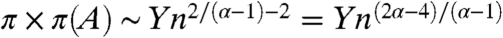
We will always suppose that the degree distribution has p
0 = 0. If p
1 = p
2 = 0 then the mixing time t
n = O(log n). [Combine Theorems 6.3.2, 6.2.1, and 6.1.2 in Durrett (11).] If p
2 > 0 then there are chains of vertices of degree 2 of length O(log n), and the mixing time t
n = O(log2
n). See Section 6.7 in Durrett (11). If, in addition, p
1 > 0 nothing bad happens, but we have to assume that 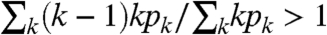 so that a giant component exists and then restrict our attention to the voter model on it.
so that a giant component exists and then restrict our attention to the voter model on it.
Suchecki et al. (60) claim, based on simulations, that on the Barabási–Albert preferential attachment graph, the vertex voter model reaches consensus in time n 0.88, while the edge voter model takes time asymptotically cn. However, as Sood and Redner (58) observe, the first quantity may just be the n/ log n given above. The result for the edge voter model is easy. π × π(A) = 1/n so as long as the mixing time is o(n), T A/n will converge to an exponential.
Lieberman et al. (61) and Sood and coworkers (62,63) have considered biased version of the edge voter model in which 0s always switch to 1s but 1s only switch to 0s with probability 1 - s. In genetic terms, 1s have a selective advantage over the 0s. Remarkably the fixation probability for a single 1 in a sea of 0s is independent of the structure of the graph, a result discovered much earlier by Maruyama (64). [See also Slatkin (65).] The proof is trivial. The embedded discrete-time chain is a biased random walk.
Discussion
Here we have presented a small sample of work concerning processes on random graphs, which is biased because it concentrates on topics to which I have contributed. A more extensive survey can be found in Barrat et al. (66). Most of the work cited there has been done by physicists and is not rigorous, but there is more for mathematicians to contribute than just dotting the i’s and crossing the t’s. In addition to occasionally correcting an error, rigorous analysis adds to our understanding of underlying mechanisms and in some cases identifies phenomena not found by simulation.
My philosophy about these models is that, like the Ising model of statistical physics, they are too simplified to make quantitative predictions reliable but are designed to give insights into how features of complex networks affect the qualitative behavior of processes that take place on them. Rigorous results, like simulations, must be interpreted carefully. Chatterjee and Durrett (34) proved that λ c = 0 for graphs with power-law degree distributions. If λ = 0.01 then one needs a vertex of degree 1/λ 2 = 104 to ensure prolonged persistence, but if p k ∼ 3p -4 then this requires n = 1012 vertices.
In all of the problems considered here, the network remains constant while the states of the vertices change. However, in reality, the connections between individuals change over time, and I think this is an important direction for research. Networks is one of two programs at the Statistical and Applied Mathematical Sciences Institute in 2010–2011. Evolving networks will be one of the several themes considered there.
Footnotes
This article is part of the special series of Inaugural Articles by members of the National Academy of Sciences elected in 2007.
The author declares no conflict of interest.
*This Direct Submission article had a prearranged editor.
References
- 1.Bollobás B. Random Graphs. 2nd Ed. Cambridge, U.K.: Cambridge Univ Press; 2001. [Google Scholar]
- 2.Janson S, Luczak T, Rucinski A. Random Graphs. New York: John Wiley and Sons; 2000. [Google Scholar]
- 3.Faloutsos M, Faloutsos P, Faloutsos C. On the power-law relationship of the internet topology; Proceedings of SIGCOMM ’99; New York: Association for Computing Machinery; 1999. pp. 251–262. [Google Scholar]
- 4.Redner S. How popular is your paper? An empirical study of the citation distribution. Eur Phys J B. 1998;4:131–134. [Google Scholar]
- 5.Newman MEJ. The structure of scientific collaboration networks. Proc Natl Acad Sci USA. 2001;98:404–409. doi: 10.1073/pnas.021544898. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Newman MEJ. Scientific collaboration networks. I and II. Phys Rev E. 2001;64:016131–016132. doi: 10.1103/PhysRevE.64.016131. [DOI] [PubMed] [Google Scholar]
- 7.Liljeros F, Edling CR, Amaral LAN, Stanley HE, Aberg Y. The web of human sexual contacts. Nature. 2001;411:907–908. doi: 10.1038/35082140. [DOI] [PubMed] [Google Scholar]
- 8.Barabási AL. Linked. The New Science of Networks. Cambridge, MA: Perseus; 2002. [Google Scholar]
- 9.Watts DJ. Six Degrees. New York: W.W. Norton and Co.; 2003. [Google Scholar]
- 10.Chung F, Lu L. Complex Graphs and Networks. Providence, RI: Am Math. Society; 2006. [Google Scholar]
- 11.Durrett R. Random Graph Dynamics. Cambridge, U.K.: Cambridge Univ Press; 2007. [Google Scholar]
- 12.Watts DJ, Strogatz SH. Collective dynamics of ‘small-world’ networks. Nature. 1998;393:440–442. doi: 10.1038/30918. [DOI] [PubMed] [Google Scholar]
- 13.Newman MEJ, Watts DJ. Renormalization group analysis of the small-world network model. Physics Lett A. 1999;263:341–346. [Google Scholar]
- 14.Barabási AL, Albert R. Emergence of scaling in random network. Science. 1999;286:509–512. doi: 10.1126/science.286.5439.509. [DOI] [PubMed] [Google Scholar]
- 15.Krapivsky PL, Redner S, Leyvraz F. Connectivity of growing random networks. Phys Rev Lett. 2000;85:4629–4632. doi: 10.1103/PhysRevLett.85.4629. [DOI] [PubMed] [Google Scholar]
- 16.Cooper C, Frieze A. A general model for web graphs. Random Struct Algor. 2003;22:311–335. [Google Scholar]
- 17.Newman MEJ, Strogatz SH, Watts DJ. Random graphs with arbitrary degree distributions and their applications. Phys Rev E. 2001;64:026118. doi: 10.1103/PhysRevE.64.026118. [DOI] [PubMed] [Google Scholar]
- 18.Newman MEJ, Strogatz SH, Watts DJ. Random graph models of social networks. Proc Natl Acad Sci USA. 2002;99:2566–2572. doi: 10.1073/pnas.012582999. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Moore C, Newman MEJ. Exact solution of bond percolation on small-world networks. Phys Rev E. 2000;62:7059–7064. doi: 10.1103/physreve.62.7059. [DOI] [PubMed] [Google Scholar]
- 20.Newman MEJ. Spread of epidemic disease on networks. Phys Rev E. 2002;66:016128. doi: 10.1103/PhysRevE.66.016128. [DOI] [PubMed] [Google Scholar]
- 21.Harris TE. Contact interactions on a lattice. Ann Probab. 1974;2:969–988. [Google Scholar]
- 22.Liggett TM. Stochastic Interacting Systems: Contact, Voter and Exclusion Processes. New York: Springer; 1999. [Google Scholar]
- 23.Bollobás B, Chung F. The diameter of a cycle plus a random matching. SIAM J Discrete Math. 1988;1:328–333. [Google Scholar]
- 24.Durrett R, Jung P. Two phase transitions for the contact on small worlds. Stoch Proc Appl. 2007;117:1910–1927. [Google Scholar]
- 25.Pemantle R. The contact process on trees. Ann Probab. 1992;20:2089–2116. [Google Scholar]
- 26.Liggett TM. Multiple transition points for the contact process on the binary tree. Ann Probab. 1996;24:1675–1710. [Google Scholar]
- 27.Stacey AM. The existence of an intermediate phase for the contact process on trees. Ann Probab. 1996;24:1711–1726. [Google Scholar]
- 28.Durrett R, Liu X. The contact process on a finite set. Ann Probab. 1988;16:1158–1173. [Google Scholar]
- 29.Mountford TS. Existence of a constant for finite system extinction. J Stat Phys. 1999;96:1331–1341. [Google Scholar]
- 30.Pastor-Satorras R, Vespigniani A. Epidemic spreading in scale-free networks. Phys Rev Lett. 2001;86:3200–3203. doi: 10.1103/PhysRevLett.86.3200. [DOI] [PubMed] [Google Scholar]
- 31.Pastor-Satorras R, Vespigniani A. Epidemic dynamics and endemic states in complex networks. Phys Rev E. 2001;63:066117. doi: 10.1103/PhysRevE.63.066117. [DOI] [PubMed] [Google Scholar]
- 32.Pastor-Satorras R, Vespigniani A. Epidemic dynamics in finite size scale-free networks. Phys Rev E. 2002;65:035108(R). doi: 10.1103/PhysRevE.65.035108. [DOI] [PubMed] [Google Scholar]
- 33.Gómez-Gardeñes J, Latora V, Moreno Y, Profumo E. Spreading of sexually transmitted diseases in heterosexual populations. Proc Natl Acad Sci USA. 2008;105:1399–1404. doi: 10.1073/pnas.0707332105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Chatterjee S, Durrett R. Contact processes on random graphs with power law degree distributions have critical value 0. Ann Probab. 2009;37:2332–2356. [Google Scholar]
- 35.Berger N, Borgs C, Chayes JT, Saberi A. On the spread of viruses on the internet; Proceedings of the 16th Symposium on Discrete Algorithms; New York: Association for Computing Machinery; 2005. pp. 301–310. [Google Scholar]
- 36.Berger N, Borgs C, Chayes JT, Saberi A. Weak local limits for preferential attachment graphs. 2009. Preprint can be found at http://www.stanford.edu/saberi/
- 37.Griffeath D. Additive and Cancellative Interacting Particle Systems. Vol. 724. Berlin: Springer; 1978. (Lecture Notes in Math). [Google Scholar]
- 38.Durrett R, Remenik D. Chaos in a spatial epidemic model. Ann Appl Probab. 2010 in press. [Google Scholar]
- 39.Richards SA, Wilson WG, Socolar JES. Selection for intermediate mortality and reproduction rates in a spatially structured population. Proc R Soc Lond B. 1999;266:2383–2388. doi: 10.1098/rspb.1999.0935. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Socolar JES, Richards S, Wilson WG. Evolution in spatially structure populations subject to rare epidemics. Phys Rev E. 2001;63:041908. doi: 10.1103/PhysRevE.63.041908. [DOI] [PubMed] [Google Scholar]
- 41.Nusse HE, Ott E, Yorke JA. Border-collision bifurcations: An explanation for observed bifurcation phenomena. Phys Rev E. 1994;49:1073–1076. doi: 10.1103/physreve.49.1073. [DOI] [PubMed] [Google Scholar]
- 42.Li TY, Yorke JA. Period three implies chaos. Am Math Mon. 1975;82:985–992. [Google Scholar]
- 43.Lasota A, Yorke JA. On the existence of invariant measures for piecewise monotonic transformations. Trans Amer Math Soc. 1973;186:481–488. [Google Scholar]
- 44.Kauffman SA. Metabolic stability and epigenesis in randomly constructed genetic nets. J Theor Biol. 1969;22:437–467. doi: 10.1016/0022-5193(69)90015-0. [DOI] [PubMed] [Google Scholar]
- 45.Kadanoff LP, Coppersmith S, Aldana M. Boolean dynamics with random couplings. 2002. arXiv:nlin.AO/0204062.
- 46.Flyvbjerg H, Kjaer NJ. Exact solution of Kaufmann’s model with connectivity one. J Phys A. 1988;21:1695–1718. [Google Scholar]
- 47.Derrida B, Pomeau Y. Random networks of automata: a simplified annealed approximation. Europhys Lett. 1986;1:45–49. [Google Scholar]
- 48.Kauffman SA. Origins of Order: Self-Organization and Selection in Evolution. New York: Oxford Univ Press; 1993. [Google Scholar]
- 49.Shmulevich I, Kauffman SA, Aldana M. Eukaryotic cells are dynamically ordered or critical but not chaotic. Proc Natl Acad Sci USA. 2005;102:13439–13444. doi: 10.1073/pnas.0506771102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Nykter M, et al. Gene expression dynamics in the macrophage exhibit criticality. Proc Natl Acad Sci USA. 2008;105:1897–1900. doi: 10.1073/pnas.0711525105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Chatterjee S, Durrett R. Persistence of activity in random Boolean networks. Random Struct Algor. 2010 in press. [Google Scholar]
- 52.Clifford P, Sudbury A. A model for spatial conflict. Biometrika. 1973;60:581–588. [Google Scholar]
- 53.Holley R, Liggett T. Ergodic theorems for weakly interacting systems and the voter model. Ann Probab. 1976;4:195–228. [Google Scholar]
- 54.Cox JT. Coalescing random walks and voter model consensus times on the torus in Z d . Ann Probab. 1989;17:1333–1366. [Google Scholar]
- 55.Durrett R. Probability: Theory and Examples. Belmont, CA: Duxbury Press; 2005. [Google Scholar]
- 56.Aldous D. The Poisson Clumping Heuristic. New York: Springer; 1989. [Google Scholar]
- 57.Aldous D, Fill J. Reversible Markov Chains and Random Walks on Graphs. 2002. Chap 3. http://www.stat.berkeley.edu/~aldous. [Google Scholar]
- 58.Sood V, Redner S. Voter model on heterogeneous graphs. Phys Rev Lett. 2005;94:178701. doi: 10.1103/PhysRevLett.94.178701. [DOI] [PubMed] [Google Scholar]
- 59.van der Hofstad R, Hooghiemstra G, and Znamenski D. Distances in random graphs with infinite mean degrees. Extremes. 2005;8:111–141. [Google Scholar]
- 60.Suchecki K, Eguuíluz VM, Miguel MS. Conservation laws for the voter model in complex networks. Europhys Lett. 2005;69:228–234. [Google Scholar]
- 61.Lieberman E, Hauert C, Nowak MA. Evolutionary dynamics on graphs. Nature. 2005;433:312–316. doi: 10.1038/nature03204. [DOI] [PubMed] [Google Scholar]
- 62.Antal T, Redner S, Sood V. Evolutionary dynamics on degree-heterogeneous graphs. Phys Rev Lett. 2006;96:188104. doi: 10.1103/PhysRevLett.96.188104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Antal T, Redner S, Sood V. Voter models on heterogeneous graphs. Phys Rev E. 2008;77:041121. doi: 10.1103/PhysRevE.77.041121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Maruyama T. The effective number of alleles in a subdivided population. Theor Popul Biol. 1970;1:273–306. doi: 10.1016/0040-5809(70)90047-x. [DOI] [PubMed] [Google Scholar]
- 65.Slatkin M. Fixation probabilities and fixation times in a subdivided population. Evolution. 1981;35:477–488. doi: 10.1111/j.1558-5646.1981.tb04911.x. [DOI] [PubMed] [Google Scholar]
- 66.Barrat A, Bathélemy M, Vespignani A. Dynamical Processes on Complex Networks. Cambridge, U.K.: Cambridge Univ Press; 2008. [Google Scholar]