
Figure 1.
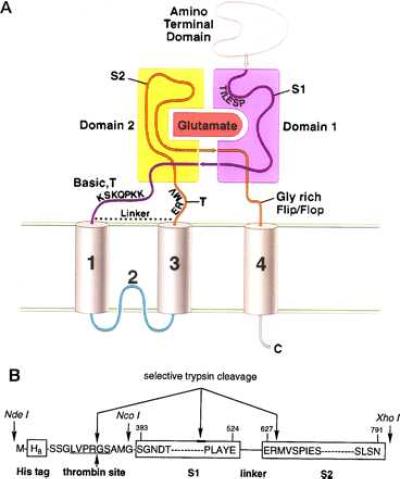
(A) Working model for the domain organization of the glutamate receptor derived from previous experimental, sequence analysis, and molecular modeling studies (20, 28, 31). Indicated are the amino-terminal domain, the S1 and S2 regions, and the proposed transmembrane and membrane-associated segments. Domains 1 and 2 are primarily composed of polypeptide segments S1 and S2, respectively. However, the carboxyl terminus of S1 probably crosses over into domain 2, and the carboxyl terminus of S2 may compose a portion of domain 1. In HS1S2, there is a trypsin site (T) after membrane segment 3, and the locations of trypsin sites before membrane segment 1 are probably within the basic region. The glycine-rich flop sequence before membrane segment 4 is also indicated. (B) Schematic of the HS1S2 construct using the single amino acid code. Sites of proteolytic reactivity are indicated as are three of the key restriction sites present in the corresponding DNA sequence. The numbers above the amino acid residues refer to the residue numbers of the full-length receptor.