
Figure 4. The need for statistical validation of peptide identification data.
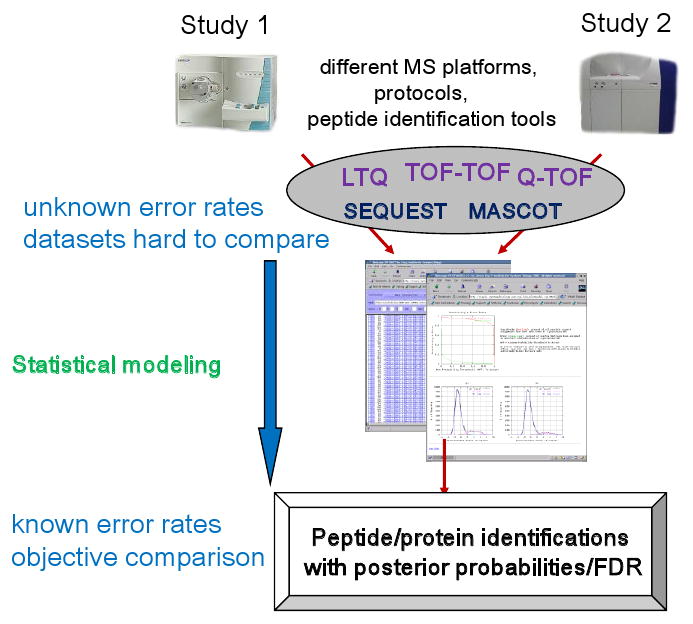
MS/MS data can be generated by different groups using different type of MS instruments, and peptides assigned to spectra using a number of different database search tools. Filtering of peptide and protein identification datasets using simple score cut-offs results in unknown error rates in each dataset, and prevents objective comparison of different datasets. Statistical modeling and conversion of the original search scores into posterior peptide and protein identification probabilities allows error rate estimation and cross-dataset comparison.