
Figure 2.
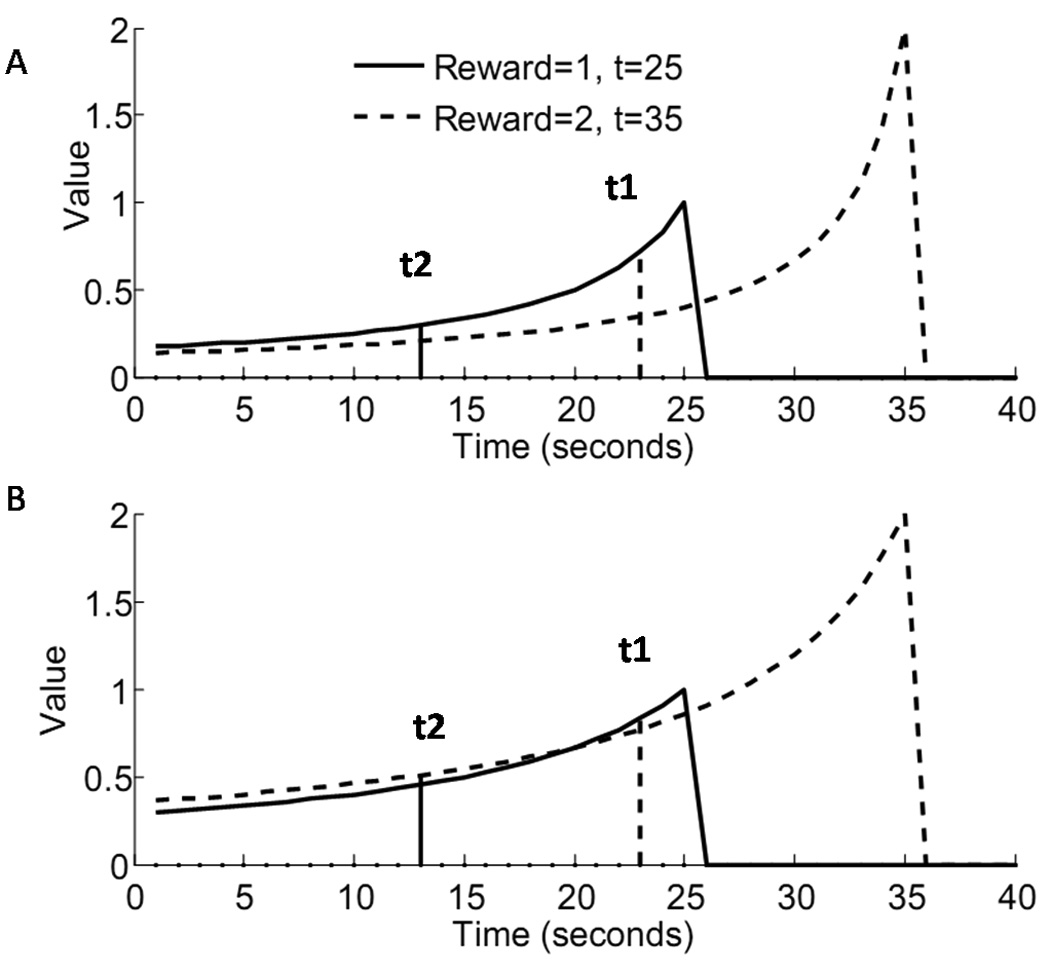
Behavior of the HDTD model (A) when the discounting factor is not scaled by estimated reward per trial (eq. 2.4, κ = 0.2), and (B) when the discounting factor is scaled by the estimated reward per trial(eq. 2.6, κ = 0.2, σ = 1). The HDTD model reverses preferences (B) depending on the temporal proximity of two unequal rewards. When a small reward is immediately available (t1), the value function for that reward (solid line) is higher than for a larger delayed reward (dashed line). However, when the distance to both rewards is increased (t2), the preferences reverse; the value function for the larger reward is higher than for the smaller.