
Figure 1.
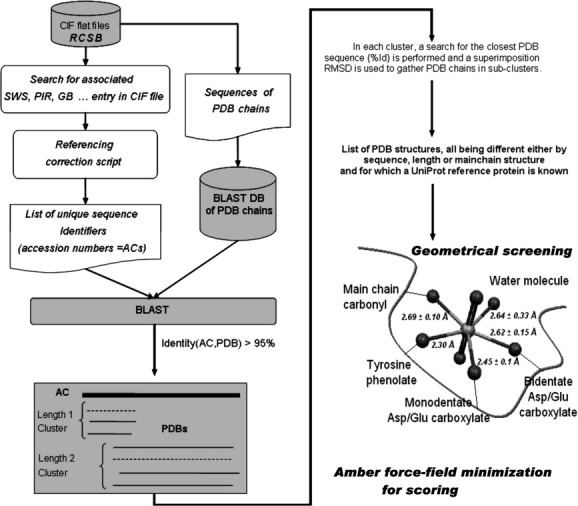
Selection of PDB subset, clustering, and docking. Selection of the least mutated PDB protein chains matching each portion of wild type protein sequences, after discarding chains of near identical structure. 12837 PDB unique IDs were selected as the database subset. A two-stage screening method identified and scored 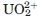 chelation sites in these structures.
chelation sites in these structures.