
Fig. 3.
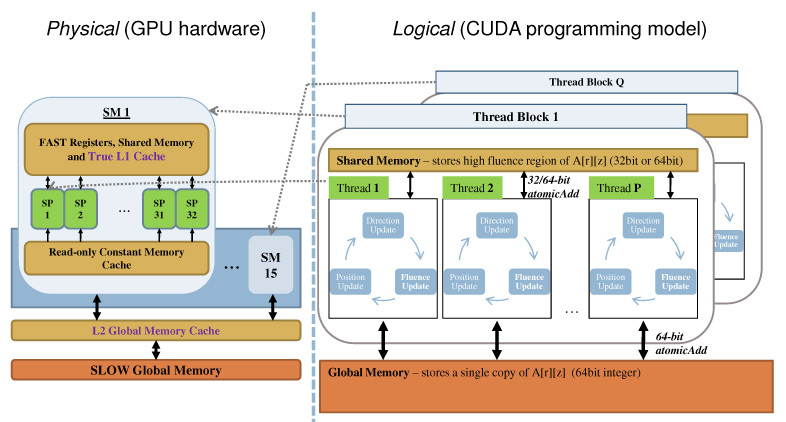
Parallelization scheme of the GPU-accelerated MCML code. Note that the number of thread blocks Q is matched to the number of SMs available and the number of threads P in each block is a many-to-one mapping (in this case, Q=15 and P=896 for GTX 480).