
Table 1.
Diversity indices computed for each of the seven genetic loci analyzed.
| FSC | FCT | FST | P (FSC) | P (FCT) | P (FST) | Dintra | Dinter | P (Dintra) | P (Dinter) |  |
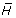 |
||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ABO | Allele Freq | 0.007 (0.002) |
0.010 (0.010) |
0.017 (0.012) |
0.331 (0.000) |
0.437 (0.000) |
0.697 (0.000) |
0.007 (0.005) |
0.017 (0.017) |
0.061 (0.329) |
0.128 (0.660) |
3.00 ± 0.02 (3.00) |
0.475 ± 0.015 (0.48) |
| MNSs | Allele Freq | 0.006 (0.005) |
0.004 (0.004) |
0.010 (0.009) |
0.401 (0.000) |
0.231 (0.001) |
0.983 (0.000) |
0.011 (0.008) |
0.011 (0.011) |
0.079 (0.205) |
0.156 (0.346) |
4.00 ± 0.01 (4.00) |
0.696 ± 0.005 (0.690) |
| RH | Allele Freq | 0.022 (0.011) |
0.047 (0.042) |
0.068 (0.052) |
0.986 (0.000) |
0.997 (0.000) |
1.000 (0.000) |
0.021 (0.014) |
0.066 (0.072) |
0.226 (0.473) |
0.709 (0.945) |
4.79 ± 0.19 (5.56) |
0.664 ± 0.009 (0.657) |
| GM | Allele Freq | 0.012 (0.010) |
0.039 (0.040) |
0.051 (0.049) |
0.814 (0.000) |
0.989 (0.000) |
1.000 (0.000) |
0.014 (0.011) |
0.051 (0.053) |
0.103 (0.292) |
0.522 (0.871) |
3.97 ± 0.18 (4.97) |
0.54 ± 0.019 (0.538) |
| HLA-DBR1 | Allele Freq | 0.009 (0.008) |
0.002 (0.003) |
0.011 (0.010) |
0.983 (0.000) |
0.135 (0.000) |
0.997 (0.000) |
0.010 (0.009) |
0.011 (0.011) |
0.239 (0.396) |
0.253 (0.567) |
9.79 ± 0.26 (11.86) |
0.872 ± < 0.004 (0.872) |
| Y-STR | STRs | 0.085 (0.031) |
0.222 (0.192) |
0.288 (0.217) |
1.000 (0.000) |
1.000 (0.000) |
1.000 (0.000) |
0.110 (0.084) |
0.359 (0.299) |
0.330 (0.468) |
0.963 (1.00) |
11.83 ± 0.60 (42.59) |
*0.863 ± 0.031 *(0.874) |
| Y-SNP | SNPs | 0.0511 (0.049) |
0.470 (0.446) |
0.497 (0.473) |
0.734 (0.000) |
1.000 (0.000) |
1.000 (0.000) |
0.065 (0.054) |
0.723 (0.710) |
0.425 (0.308) |
0.681 (1.00) |
5.334 ± 1.60 (8.30) |
*0.592 ± 0.193 *(0.574) |
| mt-HVS1 | DNA seq | 0.022 (0.027) |
0.022 (0.020) |
0.044 (0.047) |
0.988 (0.000) |
0.963 (0.000) |
1.000 (0.000) |
0.021 (0.025) |
0.043 (0.045) |
0.203 (0.386) |
0.553 (0.844) |
19.03 ± 4.45 (32.96) |
*0.92 ± 0.070 *(0.938) |
The first line represents the mean value for 10,000 resamplings while the second line (in brackets) represents the statistics computed using the whole dataset. P(x) represents the proportion of indices statistically significant at 1% level or the exact P value for the whole dataset. D stands for Reynolds genetic distances, for the average number of alleles over the samples and for the average heterozygosity (*gene diversity) over the samples