
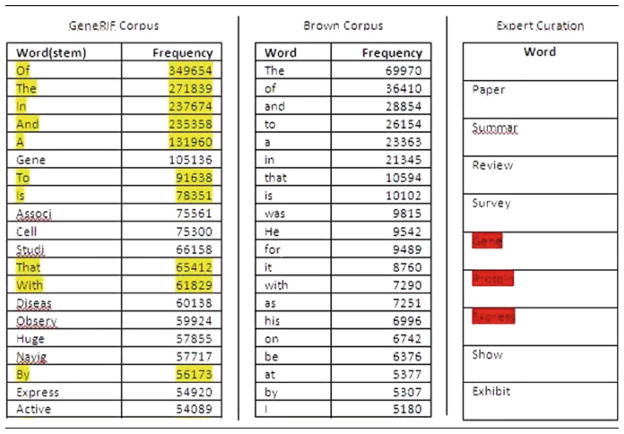
Table 79.1.
Stopwords. The 20 most frequently occurring words (after stemming) in the entire GeneRIF dataset (left) and the Brown Corpus (center) are shown, and the overlaps between the two lists are highlighted. On the right is a list of manually identified stopwords, and its overlaps with the GeneRIF-corpus-list are highlighted
 |