
Table 1. Selection of the optimal weight matrix by core genes and evaluation by the genome-wide association (GWA) p-values.
| Parameter seta | Total number of weight matrices | Number of weight matrices met criteriab | Selection by core genes | Selection by GWA p-valuesf | ||||
| ϕ (%) | η (%) | Weight matrixc | Position j d | Positionl e | Mean | sd | ||
| 90 | 3 | 4,663 | 1 | [2,1,1,8,1,1,7] | 150 | 1053 | 966.6 | 5.4 |
| 4 | 11,916 | 13 | [2,1,1,8,1,1,7] | 150 | 1053 | 963.9 | 4.1 | |
| [2,1,1,8,1,1,8] | 153 | 738 | 933.8 | 5.5 | ||||
| [3,1,1,8,1,1,7] | 153 | 1054 | 952.6 | 7.2 | ||||
| [3,1,1,8,1,1,8] | 155 | 738 | 930.2 | 9.4 | ||||
| [4,1,1,8,1,1,7] | 157 | 1054 | 948.2 | 7.2 | ||||
| ‵ | [4,1,1,8,1,1,8] | 159 | 739 | 922.2 | 9.3 | |||
| [5,1,1,8,1,1,7] | 157 | 1054 | 944.2 | 4.5 | ||||
| [5,1,1,8,1,1,8] | 159 | 739 | 928.7 | 6.5 | ||||
| [6,1,1,8,1,1,7] | 159 | 1054 | 949.4 | 8.1 | ||||
| [7,1,1,8,1,1,7] | 159 | 1054 | 952.4 | 7.1 | ||||
| [8,1,1,8,1,1,7] | 159 | 1054 | 955.3 | 7.5 | ||||
| [7,1,1,6,1,3,7] | 159 | 1159 | 922.3 | 12.7 | ||||
| [8,1,1,6,1,3,7] | 159 | 1159 | 927.4 | 6.2 | ||||
| 5 | 20,285 | 13 | [2,1,1,8,1,1,7] | 150 | 1053 | 963.0 | 5.4 | |
| [2,1,1,8,1,1,8] | 153 | 738 | 931.9 | 10.5 | ||||
| [3,1,1,8,1,1,7] | 153 | 1054 | 955.2 | 8.4 | ||||
| [3,1,1,8,1,1,8] | 155 | 738 | 931.1 | 6.5 | ||||
| [4,1,1,8,1,1,7] | 157 | 1054 | 942.9 | 9.6 | ||||
| [4,1,1,8,1,1,8] | 159 | 739 | 925.3 | 7.4 | ||||
| [5,1,1,8,1,1,7] | 157 | 1054 | 945.2 | 9.6 | ||||
| [5,1,1,8,1,1,8] | 159 | 739 | 925.0 | 10.6 | ||||
| [6,1,1,8,1,1,7] | 159 | 1054 | 948.9 | 4.1 | ||||
| [7,1,1,8,1,1,7] | 159 | 1054 | 956.0 | 5.8 | ||||
| [8,1,1,8,1,1,7] | 159 | 1054 | 951.2 | 7.9 | ||||
| [7,1,1,6,1,3,7] | 159 | 1159 | 922.2 | 8.9 | ||||
| [8,1,1,6,1,3,7] | 159 | 1159 | 921.7 | 17.6 | ||||
Note:
ϕ and η denote threshold proportion in the core gene set and the candidate gene set.
Selection criteria: position j≤160, position l≤1200 and mean≥900. Definition of j and l is shown in footnote d and e below. The weight matrices with mean 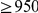 marked in bold.
marked in bold.
Weight matrix is ordered by ωassociation, ωlinkage, ωexpression_human, ωliterature_human, ωkegg, ωexpression_rat, ωliterature_animal.
Position j represents the position of the ϕ-th core gene locates in the η-th top ranked candidate genes.
Position l represents the position of the last core gene locates in the ranked candidate genes.
Mean: total number of random subsets having significant different p-value distribution from the top ranked candidate genes (Wilcoxon rank-sum test, p<0.05); sd: standard deviation.