
Fig. 7.
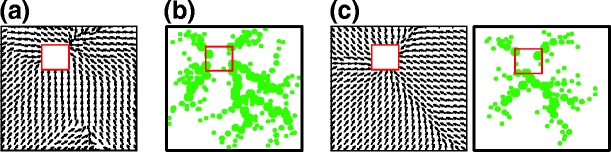
Results from single experiments using different navigation strategies to find a goal from random start position. (a) Q-learning: vector field representation of learned actions. (b) Self-marking navigation: environment with self-laid scent marks (marked by dots). (c) Combined navigation: vector field representation of learned actions (left) and corresponding self-laid scent marks (right)