
Fig. 1.
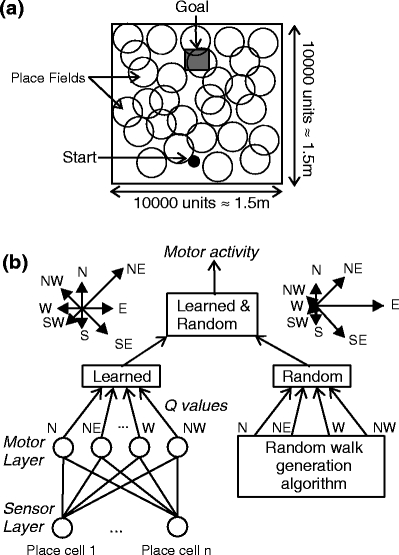
Model environment: the start is shown as a circle, and the goal is a rectangular area of the size 15 cm×15 cm, located opposite to the start 15 cm away from the upper border. Big circles schematically show place fields covering the arena. (b) Neural network of a model animal where motor activity is obtained as combination of learned direction values (Q-values, Learned) and path straightening components (Random). The stars show examples how these components could look like. The two components are combined summing learned and random components for each direction with appropriate coefficients (Learned & Random), and then choosing the prevailing direction for a motor action