
Figure 1. Model Architecture.

Our animat (artificial animal) “lives” on a circle and
performs the following task. We place the animat randomly to one
position on the circle. The animat then chooses a direction, the
decision, 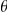 . At each
position there is one “correct” direction
. At each
position there is one “correct” direction
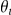 . Choices
. Choices
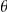 close to
the correct direction
close to
the correct direction 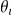 receive
some reward, according to a Gaussian reward function. This processes
(the setting of the animat at a location, selection of a decision,
receiving a reward and updating of the feed-forward weights) constitutes
a single trial. After completion of a trial the animat is placed
randomly at a new position and the task is repeated. The task will be
fully learned if the animat chooses the correct direction at each
position on the circle. A: Shows a schematic overview of our two layer
model architecture consisting of Place Cells (red) and Action Cells
(blue). Place Cells (modelled as Poisson neurons) are connected to
Action Cells (Integrate-and-Fire neurons) using an all-to-all feed
forward network (not all connections are shown). In addition Action
Cells may be interconnected via lateral Mexican hat-type connections
(not all connections are shown). The layer of Place Cells is arranged in
a ring like topology with each neuron
receive
some reward, according to a Gaussian reward function. This processes
(the setting of the animat at a location, selection of a decision,
receiving a reward and updating of the feed-forward weights) constitutes
a single trial. After completion of a trial the animat is placed
randomly at a new position and the task is repeated. The task will be
fully learned if the animat chooses the correct direction at each
position on the circle. A: Shows a schematic overview of our two layer
model architecture consisting of Place Cells (red) and Action Cells
(blue). Place Cells (modelled as Poisson neurons) are connected to
Action Cells (Integrate-and-Fire neurons) using an all-to-all feed
forward network (not all connections are shown). In addition Action
Cells may be interconnected via lateral Mexican hat-type connections
(not all connections are shown). The layer of Place Cells is arranged in
a ring like topology with each neuron 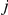 having a
preferred angle, and firing with maximum probability if the location of
the animat happens to coincide with this preferred angle. In the example
shown the animat is placed at the location that corresponds to the
preferred direction of neuron index
having a
preferred angle, and firing with maximum probability if the location of
the animat happens to coincide with this preferred angle. In the example
shown the animat is placed at the location that corresponds to the
preferred direction of neuron index 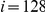 . The top
layer, also arranged in a ring topology, codes for the location the
animat will choose. B: Shows the output spike train of the Action Cells
demonstrating a bump formation around neuron
(
. The top
layer, also arranged in a ring topology, codes for the location the
animat will choose. B: Shows the output spike train of the Action Cells
demonstrating a bump formation around neuron
(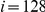 ) with a
resulting decision angle
) with a
resulting decision angle 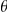 matching
the preferred angle of
matching
the preferred angle of 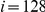 . In this
example the target angle
. In this
example the target angle 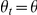 , and
therefore the animat has made the correct decision. C: Shows the spike
train of the input layer (Place Cells) when the animat is placed at the
location encoded by neuron
, and
therefore the animat has made the correct decision. C: Shows the spike
train of the input layer (Place Cells) when the animat is placed at the
location encoded by neuron 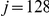 .
.