

Abstract
Most theories of semantic memory characterize knowledge of a given object as comprising a set of semantic features. But how does conceptual activation of these features proceed during object identification? We present the results of a pair of experiments that demonstrate that object recognition is a dynamically unfolding process in which function follows form. We used eye movements to explore whether activating one object’s concept leads to the activation of others that share perceptual (shape) or abstract (function) features. Participants viewed four-picture displays and clicked on the picture corresponding to a heard word. In critical trials, the conceptual representation of one of the objects in the display was similar in shape or function (i.e., its purpose) to the heard word. Importantly, this similarity was not apparent in the visual depictions (e.g., for the target “frisbee,” the shape-related object was a triangular slice of pizza – a shape that a frisbee cannot take); preferential fixations on the related object were therefore attributable to overlap of the conceptual representations on the relevant features. We observed relatedness effects for both shape and function, but shape effects occurred earlier than function effects. We discuss the implications of these findings for current accounts of the representation of semantic memory.
Keywords: semantic memory, semantic features, semantic attributes, spoken word recognition, eye movements
Introduction
Look around you. You are likely faced with numerous and various objects, most of which you know quite a bit about. For example, there might be a plate with a slice of pizza on it left over from dinner. If asked, you would be able to easily retrieve a great deal of semantic information about pizza (e.g., its shape, color, smell, what it is used for, how it is cooked, and so on). In fact, these attributes might be considered to constitute the concept pizza. Broadly speaking, different attributes of objects can be classified into those that are perceptual (e.g., round, red, hot) and those that are abstract (e.g., food, Italian, cheap). However, when we look at an object like pizza, there is a further distinction, in that we have access to both the immediate sensory perceptual information (reflecting the current input to our senses), and long-term (i.e., conceptual) knowledge about an object’s typical perceptual features (which are generalized across different experiences with that object). Thus, the slice of pizza across the room may be triangular, red and greasy, but from this sensory information we can retrieve not only the abstract knowledge that it is a food (knowledge that is abstracted across the various contexts in which pizzas are experienced), but also the long-term perceptual knowledge that pizza is usually round (a feature that is often, but not currently, grounded in sensory experience). The focus of the current work is on this long-term conceptual knowledge (both perceptual and abstract) about concrete objects.
One consequence of the description of concepts as including a set of independent attributes (or features) is that it allows for the possibility that they can have different time courses of activation. For example, when identifying that the thing on the plate across the room is leftover pizza, the initial input is primarily sensory; if the activation of the concept pizza begins with sensory input, it may spread to long-term perceptual information more quickly than to more dissimilar abstract features. In the current work, we contrast perceptual with more abstract features to explore whether different attributes of an object have distinct time courses of activation during object identification. Finding that perceptual and abstract information become available over different time courses would indicate that these features are at least partially distinct components of semantic knowledge. It would also have interesting and perhaps surprising implications: Although we typically think about our mental representation of concrete objects as static (there is something that pizza “means,” and this doesn’t vary), if there are differences in the time course over which different conceptual features of pizza are activated, then in a sense, pizza can “mean” something different as the process of object identification unfolds. In other words, an architecture that allows different attributes to be activated at different times would suggest that the process of conceiving of a concept is a dynamically unfolding process.
Using Eye Movements to Explore Semantic Activation During Object Identification
Recently, eye movements in the “visual world paradigm” have been used to explore semantic activation. In visual world paradigm studies, participants are typically presented with a multi-picture display, one of the objects is named, and participants are asked to touch (or click on) the named object (the target). Recent studies have shown that if the target is semantically related to one of the other objects, participants are more likely to fixate on this related object than on unrelated objects (Huettig & Altmann, 2005; Yee & Sedivy, 2001). For example, when instructed to click on the lock, one is more likely to fixate on a picture of a key than on unrelated objects. This effect cannot be attributed solely to visual confusability, simple lexical co-occurrence, or attention being drawn to objects in the display that are related (irrespective of the acoustic input).
Why then do participants fixate on semantically related objects? To answer this question it may be useful to provide a step-by-step account of what we assume is occurring when semantic effects are observed in the visual world paradigm: When the pictures appear, participants scan all of the depicted objects, and begin to identify them. During this process, many different attributes become active. To continue with the lock-key example, if the key is depicted in gold and in a capital letter P -ish shape, then upon seeing that object, the remainder of its semantic representation, including non-depicted perceptual features (e.g., hard, flat) and abstract features (e.g., used for security) become active. Later, when a target word is heard (e.g., “lock”), its semantic representation, including its various perceptual and abstract features (e.g., shiny, hard, used for security) also becomes active. Subjects’ visual attention is drawn to a picture to the extent that there is a match between any of the currently active attributes of that picture and the semantic representation of the target (cf. Altmann & Kamide, 2007). Thus, if there is a key in the display and the target word is “lock,” and if abstract information about key (e.g., used for security) has become active, visual attention will be drawn to the key (due to the similarity between the abstract features of lock and key). This sensitivity to overlap on even non-depicted semantic features makes the visual world paradigm an excellent candidate for exploring the activation of conceptual features during object identification.
Studies using eye movements to explore the activation of semantic information have provided evidence that partial semantic overlap between a heard word and a displayed object is sufficient to draw visual attention to the displayed object (Huettig & Altmann, 2005, Yee & Sedivy, 2001), and also that the degree of semantic overlap predicts how much visual attention is drawn (Huettig & Altmann, 2005; Huettig et al., 2006; Mirman & Magnuson, 2009). However, these initial studies made no attempt to explore which of the shared semantic attributes produced that partial activation (e.g., if lock activates key, is this due to overlap on the perceptual feature hard? The abstract feature used for security? Both?). By explicitly manipulating the semantic relationship between the target and the related object, it is possible to use eye movements to reveal if and when a particular semantic attribute is activated during object identification. Critically, for the purposes of the current work, by isolating different semantic relationships, it is possible to test whether different kinds of semantic attributes are activated differentially during object identification.
A few recent studies have begun to explore specific semantic relationships. These studies have demonstrated that visual attention is drawn to objects whose sensory shapes match the long-term (hereafter “conceptual”) shape properties of a spoken word’s referent (e.g., visual attention is drawn to a picture of a rope when the word “snake” is heard; Dahan & Tanenhaus, 2005; Huettig & Altmann, 2007; Huettig & McQueen, 2007; cf. Myung, Blumstein & Sedivy, 2006 for an investigation of conceptual activation of a different perceptual feature, manipulation). This finding provides additional evidence that visual attention is drawn to a picture when there is a match between the currently active attributes of that picture and the (conceptual) semantic representation activated by the heard word (in this case, there is a match in shape, rather than the undifferentiated semantics in the lock-key example). However, these prior studies did not attempt to discriminate between sensory vs. conceptual shape of the displayed objects. As a result, it is unclear whether the displayed object’s conceptual shape played any role in the diversion of visual attention (see Huettig & Altmann, 2010, for evidence that this depicted vs. conceptual distinction is significant). In other words, from these studies it is not possible to determine whether subjects fixated on the rope when searching for a snake because the long-term shape knowledge activated by the word “snake” matched the depicted shape of the rope, or whether they fixated on the rope because of the match with the conceptual shape of rope (i.e., independent of its current sensory instantiation).
In the current work, we explicitly manipulated the semantic relationship between the target word and the displayed related object in order to independently explore the activation of two types of semantic features during object identification: a perceptual feature (shape) and a more abstract feature (function). We use the term “function” because it is the most specific way to refer to the abstract feature (i.e., purpose of use) we test. Our intent is not to make claims about function in particular, in contrast to other abstract features that might be correlated with function (e.g., functionally related pairs are often also members of the same taxonomic category and thus might also be called “semantically” or “conceptually” related). Instead, we aim to distinguish between semantic features that can be apprehended through a single perceptual modality (like shape) vs. those that cannot (i.e., between sensorimotor-based features and abstract features). We use the term “function,” rather than “conceptual” or “semantic” because, as demonstrated above, “semantic” and “conceptual” may be considered umbrella terms which can comprise both abstract and perceptual features – the very things we are distinguishing between.
We had two goals: First, to determine whether similarity in conceptual shape can affect visual attention. Second, if it can, to determine whether it is possible to dissociate the time course of shape’s activation from that of a more abstract feature (function). For example, when you are faced with a triangular slice of pizza, does information about its conceptual shape [round] become active before information about its purpose of use [food]? To address this second question, we manipulated the amount of time that subjects had to identify the objects in the display prior to hearing the target word. If abstract and perceptual information become available over different time courses, this would suggest that these features are at least partially distinct components of semantic knowledge. It would also indicate that conceiving of an object is a dynamically unfolding process.
Experiment 1
In Experiment 1 we used the visual world paradigm described above to test whether hearing the name of an object draws visual attention to objects that share a perceptual feature (shape) and/or an abstract feature (function). For example, for function, since tape and glue are both used for sticking things together, a function-related display might include pictures of glue and tape, as well as two unrelated objects. Preferential fixations on the glue when the word “tape” is heard would indicate that information about the function of glue is active. Using pictures to investigate shape is more complicated: To demonstrate that fixations on the shape-related object are a consequence of partial activation of that object due to conceptual overlap on shape, it is necessary to avoid depicting the shape similarity between the target and the related object. For example, to avoid the possibility that hearing “Frisbee” causes participants to fixate on a picture of a pizza because the feature [round] activated by “Frisbee” matches the roundness of the pizza-pie in the display, it is necessary for the pizza to be depicted in a non-round shape. That is, pizza must be depicted in a shape that a Frisbee cannot take (e.g., a triangle). Thus, an increase in fixations to the triangular slice of pizza upon hearing the word Frisbee must reflect the similarity between the conceptual representations of Frisbees and (typical) pizzas.
Methods
Participants
Thirty-eight male and female undergraduates from the University of Pennsylvania were tested after giving informed consent. All participants were native speakers of English and had normal or corrected-to-normal vision and no reported hearing deficits. They were given course credit or paid a rate of $10/hour for participating.
Apparatus
A SR EyeLink II head-mounted eye tracker was used to monitor participants’ eye movements. A camera imaged the participant’s right eye at 250 Hz. Stimuli were presented with PsyScript, a freely available language for scripting psychology experiments (Bates & Oliveiro, 2003) on a 15 inch ELO touch-sensitive monitor.
Materials
Stimulus selection and norming
We constructed initial lists of over 100 pairs of objects that have similar shapes or similar functions but that do not share other characteristics. Each pair (presented as words) was rated on a 1-7 scale for similarity of shape, function, color, or manipulation. (See Table 1 caption for rating instructions.) Although color and manipulation similarity are not examined in the current work, we control for them because manipulation information has been found to be activated during concept retrieval (Myung et al., 2006), and we are currently exploring the possibility that color is as well (cf. Huettig & Altmann, 2010). Ratings were obtained from at least 12 participants per attribute (each participant rated only one attribute), none of whom participated in the eyetracking experiments. Based on these ratings, we selected 24 shape-related and 32 function-related pairs. Table 1 shows mean attribute ratings for these two conditions.
Table 1.
| shape similarity |
function similarity |
color similarity |
manipulation similarity |
|
|---|---|---|---|---|
| shape condition (24 pairs) |
6.2 (0.8) | 1.1 (0.3) | 2.8 (1.4) | 2.0 ( 0.9) |
| function condition (32 pairs) |
1.7 (0.9) | 6.3 (0.7) | 4.0 (1.7) | 4.0 (1.3) |
Mean relatedness ratings for pairs used in Experiments 1 & 2. Standard deviations are in parentheses. Instructions were as follows: shape: “Picture the things that the words refer to and rate them according to how likely they are to be the same shape”; function: “Rate the following pairs of objects according to how similar their functions (i.e., purposes) are”; color: “Picture the objects that the words refer to and rate them according to how likely they are to be the same color”; manipulation: “Consider the typical movements you make when you use these objects and rate how similar the movements are.”
These ratings provide a measure of how similar the conceptual representations of the paired objects are on the attributes of interest. However, as noted above, because the objects during the eye-tracking experiments were depicted as pictures, we must also be concerned about the immediate sensory similarity of the paired objects, which we will refer to as the picture-based visual similarity. Ensuring that the particular pictures used to represent the objects are not visually confusable will allow us to attribute any relatedness effects to conceptual, rather than picture-based visual similarity. We controlled for picture-based similarity in two ways. First, as described above, in constructing the shape-related pairs we selected only those for which one of the objects could be presented (and easily recognized) in a way that the other object could not be represented (e.g., for the pair frisbee-pizza, pizza can be represented as a triangular slice, but a frisbee cannot be triangular). Second, we gathered picture-based visual similarity ratings for all pairs. We return to these ratings, which were collected in such a way as to take into account the experiment’s design, after we introduce the design below.
Association between words in related pairs was very low according to University of South Florida free association norms (Nelson, McEvoy, & Schreiber, 1998). Shape-related pairs were completely unassociated, with an average association of 0.0% in both the forward and backward directions (data were unavailable for 5 of our 24 shape pairs). Function-related pairs had an average forward association of 0.3% and an average backward association of 0.4% (data were unavailable for 10 of the 32 function pairs). By comparison, in a visual world paradigm study that did not attempt to minimize association of semantically related pairs, association values were much higher, ranging from 0-80%, with a mean forward association of 14.5% and backward association of 12.7% (Yee & Sedivy, 2006).
Two lists, each 88 trials long, were created. Related object pairs appeared (together) as target and related object on one list and as objects unrelated to the target on the other. (See Appendix.) Each participant was presented with only one list so that no participant saw or heard any object more than once. Figures 1a and 1b show sample displays. A female speaker (E.Y.), in a quiet room, recorded each target word in isolation with sentence-final intonation. A full list of experimental items is given in the Appendix. For the displays, we selected color line drawings from a commercial clip art collection and from a collection based on the black and white Snodgrass picture library (Rossion & Pourtois, 2004; based on Snodgrass & Vanderwart, 1980).
Figure 1.

Example displays from Experiment 1 and 2 (shape, left panel, function, right panel). The target word (Frisbee or tape) is related in shape or function to one of the other objects in the display (pizza or glue). The other two objects are semantically and phonologically unrelated to the target and the related object.
Shape condition
In the shape-related condition, one of the objects in the display was related in shape to the target (e.g., pizza was related in shape to the target frisbee). As described above, this shape-related object was represented in a shape in which the target cannot be represented (e.g., pizza was presented as a triangular slice – a shape which a frisbee cannot take). The other two objects (e.g., pitcher and thimble) were semantically and phonologically unrelated to the target. The name of one of these unrelated objects was matched for frequency with the shape-related object (e.g., pitcher was frequency-matched with pizza). The name of the other unrelated object was frequency matched with the target (e.g., thimble was matched with the target frisbee). The same displays that were used in the shape-related condition in one list appeared in the shape-control condition on the other list (and vice-versa), but the target in the control condition was the object that was frequency-matched with the target in the shape-related condition (e.g., in Figure 1a, the target in the shape-control condition was thimble). Average number of syllables and duration of targets were also similar across shape-related and control conditions (2.0 and 592 ms vs. 2.0 and 583 ms, respectively).
Because the same displays were used (between subjects) in both the shape-related and the shape-control conditions, one of the non-target objects in the control condition served as the related object in the shape-related condition. This made it possible to determine whether the images that served as related objects drew fixations regardless of their relationship to the target (e.g., because the pictures were more inherently interesting than the others in the display). Another benefit of this design was that in the control condition, although two of the objects in the display were related to each other (albeit in conceptual, not depicted shape), neither one was related to the target. Therefore, if any participants noticed that some of the objects were related, they could not then predict over the course of the experiment that the target would be one of the related objects; of the 88 total trials in each list, in 12 the target was related in shape to one of the objects in the display and in 12 two objects in the display were related to each other, but neither one was the target. Of the remaining 64 trials, 16 were function-related, and 16 were function-control (conditions described below), and 32 were fillers in which no objects in the display were related in any way. Object positions were balanced so that each object type was equally likely to appear in each corner of the display.
Function condition
The design of the function condition was analogous to that of the shape condition. In the function-related condition one of the objects in the display was related in function to the target (e.g., glue was related in function to the target tape). The other two objects were semantically and phonologically unrelated to the target. Object names were frequency-matched in the same way as in the shape condition. Likewise, as in the shape condition, the same displays that were used in the function-related condition in one list appeared in the function-control condition in the other list (and vice-versa), but the target in the control condition was the object that was frequency-matched with the target in the function-related condition. Average number of syllables and duration of targets were also similar (1.7 and 581 ms in related vs. 2.0 and 571 ms in control). Thus, of the 88 total trials in each list, in 16 the target was related in function to one of the objects in the display, and in 16 two objects in the display were related to each other in function, but neither one was the target.
Picture-based visual similarity ratings
The ratings in Table 1 provide a measure of how similar the conceptual representations of the paired objects are on the attributes of interest. However, because the objects were depicted as pictures, we must also be concerned about picture-based visual similarity. Carefully controlling for picture-based visual similarity allows us to attribute any relatedness effects to conceptual, rather than picture-based visual similarity. Although we took great care to avoid picture-based visual similarity in the construction of shape-related pairs (as described above, shape-related stimuli were limited to pairs in which the competitor object could be presented in a way that the target object could not be represented), in the interest of prudence, we also gathered picture-based visual similarity ratings for both the function- and the shape- related conditions.
We presented 24 participants (who did not participate in the eyetracking experiments) with the name of the target object from either the related or the control condition, and then the picture of the related object or its control. For example, for the display that included the shape-related pair frisbee-pizza, we obtained visual similarity ratings for the target-related object pair frisbee-pizza, the control target-related object pair thimble-pizza, and the target-control object pair frisbee-pitcher. The instructions were as follows “You will see a word on the screen. Form a mental image of the object that the word refers to. Next you will see a picture. Rate the picture’s shape according to how similar it is to the mental image you formed.” The word appeared on the screen for one second before the picture appeared, and both the word and the picture remained on the screen until the participant responded. Ratings were from 1 (very different) to 7 (very similar). There were three lists and no participant saw any word or picture more than once. Presentation order was randomized for each participant.
For both the shape and the function conditions, picture-based visual similarity ratings for targets and related objects were low (means of 2.8 and 2.3, respectively for shape and function) indicating that the selected pairs of objects were not visually similar. Problematically, though, ratings for control target-related object pairs were even lower (1.2 and 1.3 for shape and function, respectively), as were ratings for target-control object pairs (1.3 for both conditions). Further, the difference between the ratings for the related vs. the unrelated pairs was highly significant (p ≤ .001) in both cases. To adjust for this disparity, we use these ratings as co-variates in our analyses. It is important to note, however, that despite being instructed to perform the ratings with respect to the shapes of the specific pictures being displayed, it is possible that participants’ knowledge of a pair’s conceptual (shape or function) similarity may have affected their ratings. If true, these ratings overestimate the picture-based visual similarity of related pairs, which would mean that including them is overly conservative – i.e., if long-term knowledge about an object’s shape or function leaks into the ratings, then when covarying these ratings out, some of the effects of function or shape will be covaried out. Because there is no perfect solution, in the text and figures we report the more conservative data set, i.e., with picture-based similarity co-varied out and for the subset of items for which picture-based similarity was perfectly matched. For completeness, in footnote 2, we also report results of analyses that do not include the covariate.
Procedure
Picture labeling phase
To ensure that participants knew what the pictures were supposed to represent, immediately before the eyetracking experiment subjects completed a picture labeling phase in which they viewed each picture and its label. Each label appeared alone on the screen for 300 ms before the picture appeared above the label. After reading the label and looking at the picture, subjects pressed a key to go on to the next label and picture. All pictures that would appear in the eyetracking phase were presented, including those from filler trials.
Eyetracking phase
Participants were presented with a 3×3 array with four pictures on it, one in each corner (see Figure 1). Each cell in the array was approximately 2 × 2 in. Participants were seated at a comfortable distance (about 18 inches) from a touch-sensitive monitor, with the monitor at eye height. Therefore, each cell in the grid subtended about 6.4 degrees of visual angle. (The eye tracker is accurate to less than one degree of visual angle.) 1000 ms after the display appeared, a sound file named one of the objects in the display. This exposure duration was selected because pilot work using the same configuration of objects suggested that 1000 ms gives participants just enough time to scan the objects. After the participant selected one of the pictures by touching it on the screen, the trial ended and the screen went blank. At this point the experimenter could either press a key to go on to the next trial, or check the calibration before continuing. The experimenter continuously monitored the participants’ eye movements and recalibrated as necessary. There were 2 practice trials. Trial order was randomized for each participant.
Eye movements were recorded starting from when the array appeared on the screen and ending when the participant touched the screen to select a picture. Only fixations that were initiated after target word onset were included in the analyses (i.e., fixations that were already on-going at target word onset were not included). We defined 4 regions, each corresponding to a 2″ × 2″ corner cell in the array. The EyeLink software parses the eye movement data into fixations, blinks and saccades. We defined a fixation on a particular region as starting with the beginning of the saccade that moved into that region and ending with the beginning of the saccade that exited that region. (Therefore, any region-internal saccades that occurred in the interim were counted as part of a single fixation on that region.) As is customary in visual world paradigm studies, the eyes had to remain on an object for at least 100 ms for a fixation to be judged to have occurred. Fixations under 100 ms were treated as continuations of prior fixations.
Results and Discussion of Experiment 1
We analyze the results of the shape and function conditions separately for ease of exposition. Analyzing them separately also has another advantage: Although ratings of shape similarity for shape pairs were very similar to ratings of function similarity for function pairs, because the ratings are on different attributes, it may not be appropriate to equate them. Although we ultimately include the two attributes in a single analysis, we limit our interpretation to how they are differently impacted by time, rather than comparing their relative sizes.
Shape
In all trials the correct picture was selected. Seven percent of trials did not provide any data because there were no eye movements after the onset of the target word (most of these were trials in which the participant was already fixating on the picture of the target at word onset). For the remaining trials, we computed the proportions (across trials) of fixations on each picture type (e.g., target, shape-related, control) over time in 100 ms bins. Fixations anywhere inside the cell that contained a picture were counted as fixations on that picture. Fixation proportions more than 2.5 standard deviations from the mean (across subjects/items) for a given time bin in a given condition were replaced with the mean of the remaining fixation proportions for that bin of that condition (3.5% by participants, 2.4% by items).
Figure 2 (left panel) plots the mean proportion (over time) of fixations on the shape-related object, and on the same object in the shape-control condition (for the picture-based similarity matched subset of items [see below]). For the purpose of analyzing the data we defined a trial as starting at 200 ms after target onset (since it takes an average of about 180 ms to initiate a saccade to a target in response to linguistic input when the specific target is not known ahead of time, but the possible locations of the target are known, [Altmann & Kamide, 2004]) and ending at the point at which the probability of fixating on the target reached asymptote (operationally defined as the first of two 100 ms bins in a row in which looks to target increased by 1% or less). In these data the end of the trial occurred at about 1000 ms after target onset.
Figure 2.

Experiment 1 (1000 ms exposure), picture-based similarity matched items. Proportion of fixations over time on the shape- (left panel) or function- (right panel) related object vs. the same object in the control condition (when it is not related to the target).
We submitted the binned data (the 8 bins corresponding to time slices 200-900 ms after target onset in Figure 2, left panel) to a repeated measures ANOVA, with condition (related or unrelated) and time bin as the repeated measures, and with the picture-based visual similarity ratings difference between the target-related object pair and the control target-related object pair as the covariate. When the assumption of sphericity was violated a Greenhouse-Geisser correction was applied, in this and all analyses reported in this manuscript. (Main effects of time bin were obtained in all of the analyses that we report. This is unsurprising because the heard word continues to unfold as eye movements are recorded; hence, eye movements in early bins reflect the processing of only a small amount of the acoustic input, while eye movements later in the trial converge on the target object. We therefore limit our discussion to main effects of condition and to condition by time interactions.)
This analysis revealed a significant effect of relatedness, with more fixations on the shape-related object compared to the same object in the control condition (related: M = .090, SE = .008; control: M = .065, SE = .008), F(1, 211) = 14.0, p = .001, ηp2 = .29. (We will refer to this difference between fixations on the shape-related object and the control object as the conceptual shape effect.) There was only a trend towards an effect of the picture-based visual similarity covariate F(1, 21) = 2.9, p = .10, ηp2 = .09. There was a condition by time interaction F(3.7, 78.1) = 4.0, p < .01, ηp2 = .12, reflecting that the effect of condition is larger in the middle time bins. We also measured the shape effect by comparing fixations on the related object with fixations on the control picture in the same display (M = .060, SE = .007). This comparison yielded a very similar pattern: a conceptual shape effect, F(1, 21) = 8.5, p = .01, ηp2 = .34, and a non-significant effect of the picture-based visual similarity covariate F(1, 21) = 2.3, p = .15, ηp2 = .11). The interaction of time with relatedness was not significant. Next, we tested whether the conceptual shape effect also appeared in the subset of items (12 in the between trial comparison, 8 in the within trial comparison) for which picture-based visual similarity was perfectly matched. These analyses revealed the same pattern: there was a significant conceptual shape effect when fixations on the shape-related object were compared to the same object in a different trial (related: M = .093, SE = .010; control: M = .056, SE = .007), F1(1, 37) = 10.5, p < .01, F2(1, 11) = 7.6, p = .02, ηp2 = .22, and also when compared to the control object in the same trial (related: M = .100, SE = .013; control: M = .047, SE = .008), F1(1, 37) = 10.4, p < .01, F2(1, 7) = 11.7, p = .01, ηp2 = .22.
A post-test questionnaire explicitly asked whether participants noticed any relationships between the objects in any of the displays, and if so, what relationships were noticed. Responses indicated that most participants (29 of 38) did not notice any relationships at all. Nine participants did report noticing that some objects were related (6 noticed function, 2 shape, and 1 both), but the pattern of results was unchanged when these participants were removed from the analysis.
These results indicate that pictures of objects that are related in shape to a heard word draw more fixations than pictures of unrelated objects. Unlike the visual world paradigm shape effects reported previously, (Dahan & Tanenhaus, 2005; Huettig & Altmann, 2007; Huettig & McQueen, 2007 [Experiments 1 & 2]), the shape effect in this study occurs when the shape-related object was depicted in a shape that the target could not take. The control condition ruled out a possible alternative explanation for the results; the same pictures were fixated on more frequently when they were related to the target in shape than when they were not related to the target, indicating that the pictures we used to represent the shape-related objects were not inherently more interesting than other pictures in the display.
In the analyses described so far, shape similarity was treated as a binary variable – pairs were either similar (shape-related condition) or not (shape control condition). However, one might predict a more continuous relationship. We tested whether the degree of shape relatedness (according to the conceptual shape relatedness ratings obtained during stimuli selection) was predictive of the shape effect. The dependent variable was the average (over the entire trial) probability of fixating on the shape-related object or its control (in a different trial), and the predictor was the similarity in (conceptual) shape of the target and the related object or control. This regression revealed that after co-varying out picture-based visual similarity F(1, 45) < 1, conceptual shape similarity ratings accounted for 16% of the variability in fixations on the shape-related object relative to the control, F(1, 44) = 8.3, R2 = .16, p < .01. This relationship provides additional support for attributing the preference for shape-related objects to their similarity in shape with the target.
The partial activation of the shape-related object demonstrates that when searching for a named object, the (undepicted) conceptual shape of a shape-related object can become active enough to divert visual attention. Hence in a context that is similar to many real life scenarios, visual attention can be diverted by long-term knowledge about an (otherwise dissimilar) object’s typical shape. More generally, the partial activation of the shape-related object is consistent with theories of semantic memory that predict that objects that share shape should have overlapping representations.
Function
Data were analyzed the same way as for the shape condition. In all trials the correct picture was selected. Ten percent of trials did not provide any data because there were no eye movements after the onset of the target word (as for shape, most of these were trials in which the participant was already fixating on the target).
Figure 2 (right panel) plots the mean proportion of trials across time that contained a fixation on the function-related object, and on the same object in the function-control condition (for the picture-based similarity matched subset of items). The repeated measures ANOVA (as for shape, incorporating all items, and with picture-based visual similarity as a covariate) revealed that when fixations on the function-related object were compared to the same object in a different trial (related: M = .089, SE = .007, control: M = .070, SE = .006), the function effect was not significant F(1, 30) < 1 and there was a significant effect of the picture-based visual similarity covariate F(1, 30) = 6.9, p = .01, ηp2 = .19. When fixations on the function-related object were compared to the control object in the same trial (M = .055, SE = .006), however, the function effect was reliable F(1, 30) = 7.4, p = .01, ηp2 = .19 and the effect of the picture-based visual similarity covariate was not significant F(1, 30) = 1.5, p = .23, ηp2 = .05. In neither comparison was there an interaction of time with relatedness. Like for shape, we also tested for a function effect in the subset of items (19 in the between trial comparison, 19 in the within trial comparison) for which picture-based visual similarity was perfectly matched. These analyses revealed the same pattern: there was no function effect when function-related objects were compared to the same object in a different trial (related: M = .076, SE = .008; control: M = .071, SE = .007), F’s < 1, but there was an effect when fixations on the function-related object were compared to the control object in the same trial (related: M = .078, SE = .008; control: M = .051, SE = .004), F1(1, 37) = 9.6, p < .01, ηp2 = .21; F2(1, 18) = 6.4, p = .02, ηp2 = .26. Excluding the nine participants who reported noticing that some of the objects were related had no effect on the pattern of results.
Because the function-related object does not reliably draw more fixations than the same object in a different trial, we must consider the possibility that there is something more interesting about the pictures we used to depict functionally related objects than the distractor objects. However, it is also possible that the intrinsic dependency between looks to the related object and the control object in the same trial simply makes this within-trial comparison more sensitive than the between-trial comparison. To help distinguish between these two possibilities, we tested whether (like for the shape effect) the degree of function relatedness was predictive of the function effect. If the source of the function effect is the inherent interest of the pictures rather than function relatedness, then the degree of function relatedness between the target and the related picture should not predict the extent to which it is fixated. As for shape, the dependent variable was the average probability of fixating on the function-related object or its control (in a different trial), and the predictor was the similarity in function of the target and the related object or control. This regression revealed that after covarying out picture-based visual similarity, F(1, 62) = 3.3, R2 = .05, p = .07, function similarity ratings accounted for only an additional 2% of the variability in fixations on the function-related object relative to control, F(1, 61) = 1.5, R2 = .02, p = .23. This suggests that factors other than similarity in function with the target object may contribute to the preference to fixate on the function-related object over the control object in the same display.
Given the observed shape-relatedness effect, the observation of a weak (or even absent) function-relatedness effect is on the surface a somewhat surprising result – intuitively, tape and glue seem more clearly related than do Frisbee and pizza. However, one account for the apparent weakness of the function effect is that, as hypothesized in the introduction, function information becomes available later than shape information. Although our initial assumption was that any time course difference would lead to differences in the timing of function- and shape- relatedness effects within a trial, if we consider our account of what we assume leads to semantic effects in the visual world paradigm, it is clear that activation of function information about both the displayed function-related object and the heard target word is required to observe function-relatedness effects. This raises the possibility that being exposed to the four objects for only 1000 ms prior to the target word (leaving, on average, only 250 ms for each object – and this is before considering the duration of saccades between objects) may not been long enough for function information about all of the objects to have become detectably active.
That function information would eventually become available seems especially plausible because prior studies that explored non-specific “semantic” relatedness in the visual world paradigm (e.g., Huettig & Altmann, 2005; Yee & Sedivy, 2006), while not making an attempt to explicitly specify the particular relationship between target and related item, did include pairs that we would define as “function-related,” and did observe relatedness effects. Importantly however, in these prior studies the exposure durations were longer than 1 second (but cf. Huettig & McQueen, 2007, which we return to in the General Discussion.)
Experiment 2
The goal of Experiment 2 was to test whether, during object identification, information about an object’s function becomes active after (long-term conceptual) knowledge about its shape. We therefore lengthen the amount of time that the display appears prior to hearing the target word, hypothesizing that this manipulation may allow us to measure the activation of the objects at a time when function information is more prominent, leading to a function effect.
Methods
Methods were identical to those in Experiment 1 with two exceptions: 1) the display appeared for 2000 ms (rather than 1000 ms) before the sound file naming one of the objects was played, and 2) a different set of thirty-eight male and female undergraduates from the University of Pennsylvania participated. We chose a 2000 ms exposure duration because pilot work using the same configuration of objects indicated that function-relatedness would be detectable with this timing.
Results and Discussion of Experiment 2
Shape
In all shape trials the correct picture was selected. Seven percent of trials did not provide any data because there were no eye movements after the onset of the target word.
Figure 3 (left panel) plots the mean proportion of trials over time that contained a fixation on the shape-related object, and on the same object in the shape-control condition (for the picture-based similarity matched subset of items). The repeated measures ANOVA revealed the effect of shape relatedness was not reliable (related: M = .076, SE = .009, control: M = .058, SE = .008), F(1, 21) = 2.8, p = .11, ηp2 = .11, and there was no effect of the picture-based visual similarity F(1, 21) < 1. There was also no interaction of time with relatedness. When fixations on the shape-related object were compared to the control object in the same trial (M = .069, SE = .006), the pattern was the same: the shape effect was not significant F(1, 21) = 1.3, p = .27, ηp2 = .06, neither was the effect of the picture-based visual similarity covariate F(1, 21) < 1, and there was no interaction of time with relatedness. As before, we also analyzed the subset of items for which picture-based visual similarity ratings were perfectly matched. This analysis showed the same pattern: when fixations on the shape-related object were compared to the same object in a different trial (related: M = .071, SE = .007, control: M = .052, SE = .008), the shape effect was only marginally significant by subjects, F1(1, 37) = 3.8, p = .06, ηp2 = .09 and was not significant by items F2(1, 11) = 1.9, p = .20, ηp2 = .14. The same pattern appeared in the comparison to the control object in the same trial (related: M = .066, SE = .009, control: M = .045, SE = .007), F1(1, 37) = 3.2, p = .08, ηp2 = .08, F2(1, 7) = 1.4, p = .28, ηp2 = .16. Finally, as in Experiment 1, we tested whether the degree of shape relatedness was predictive of the shape effect. This regression revealed that after co-varying out picture-based visual similarity F(1, 45) < 1, conceptual shape similarity ratings accounted for 7% of the variability in fixations on the shape-related object relative to the control, F(1, 44) = 3.4, R2 = .07, p = .07.
Figure 3.

Experiment 2 (2000 ms exposure), picture-based similarity matched items. Proportion of fixations over time on the shape- (left panel) or function- (right panel) related object vs. the same object in the control condition (when it is not related to the target).
These analyses reveal that in contrast to Experiment 1 in which there was a strong conceptual shape effect, in Experiment 2, the effect of conceptual shape is not statistically significant. We consider reasons for this difference in the General Discussion.
Function
Five trials (0.4%) were not included in the analysis because the wrong picture was selected. Eight percent of trials did not provide any data because there were no eye movements after the onset of the target word.
Figure 3 (right panel) plots the mean proportion of trials across time that contained a fixation on the related object and on the same object in the function-control condition (for the picture-based similarity matched subset of items). The repeated measures ANOVA revealed that when fixations on the function-related object were compared to the same object in a different trial (related: M = .096, SE = .006, control: M = .067, SE = .005) there was a significant effect of function relatedness F(1, 30) = 8.5, p < .01, ηp2 = .22, and no effect of the picture-based visual similarity covariate F(1, 30) < 1. There was also a significant interaction of relatedness with time F(3.9, 117.7) = 4.1, p < .01, ηp2 = .12, reflecting that the relatedness effect was larger in the middle time bins. Similarly, when fixations on the function-related object were compared to a different object in the same trial (M = .050, SE = .006) there was a significant effect of function relatedness F(1, 30) = 22.0, p < .01, ηp2 = .42, no effect of the picture-based visual similarity covariate F(1, 30) < 1, and a significant interaction of relatedness with time F(2.9, 87.8) = 2.9, p = .04, ηp2 = .09. We also tested whether the function effect appeared in the subset of 19 items for which picture-based visual similarity ratings were perfectly matched. This analysis revealed the same pattern: the function effect remained significant both when fixations on the function-related object were compared to the same object in a different trial (related: M = .096, SE = .010, control: M = .065, SE = .007), F1(1, 37) = 9.4, p < .01, ηp2 = .20; F2(1, 18) = 6.9, p = .02, ηp2 = .28, and when they were compared to the control object in the same trial (related: M = .081, SE = .007, control: M = .035, SE = .005), F1(1, 37) = 26.7, p < .01, ηp2 = .42, F2(1, 18) = 23.2, p < .01, ηp2 = .56.
Finally, we tested whether the degree of function-relatedness was predictive of the function effect. This regression revealed that after co-varying out picture-based visual similarity F(1, 62) = 3.1, R2 = .05, p = .08, function similarity ratings accounted for an additional 12% of the variability in the fixations on the function-related object relative to the control, F(1, 61) = 9.1, R2 = .12, p < .01. This relationship provides further evidence that the preference for the function-related object was due to its similarity in function with the target. Figure 4 displays the scatter plots from the regressions using function or (conceptual) shape similarity ratings to predict average proportion of fixations on related objects (with picture-based visual similarity co-varied out) for Experiment 1 (top panels), and Experiment 2 (bottom panels).
Figure 4.

Using conceptual similarity ratings for a given target- related (or control) object pair to predict average proportion of fixations on the related (or control) object, (after co-varying out picture-based visual similarity). Each point is an item, averaged across subjects. Left panels: Experiment 1, shape (top) and function (bottom). Right panels: Experiment 2, shape (top) and function (bottom).
It is important to note that this function effect cannot be explained by participants’ noticing that objects in the display were occasionally related, and therefore strategically attending to them. There are several reasons for this: First, when the target was unrelated to two function-related objects in the same display, these related objects were not preferentially fixated. Furthermore, the same post-test questionnaire used in Experiment 1, that explicitly asked whether participants noticed any relationships between the objects in the displays, and if so, how often and what, indicated that most participants (29 of 38) were completely unaware of the manipulation. Nine participants did report noticing that some objects were related (7 noticed function, 1 shape, and 1 both), but the pattern of results was unchanged with these participants removed. Importantly, these numbers were almost identical to those obtained in Experiment 1 (6 noticed function, 2 shape, and 1 both), and yet Experiment 2 produced a completely different pattern. Further, because any strategy would not be expected to have an influence in the experiment’s initial trials (before subjects had an opportunity to notice that objects were sometimes related), we tested whether the magnitude of the function effect increased as the experiment proceeded by dividing the function related condition into four quartiles (containing four items each). We found no effect of trial order F(3, 111) = 1.2, p = .32, ηp2 = .03 (mean related – control difference: Q1 = .06, Q2 = .02. Q3 = .04, Q4 = .05).
Experiment 2 shows that when searching for a named object, visual attention is drawn to objects that share its purpose. This finding demonstrates that information about displayed objects’ functions do become active, and suggests that objects that have similar functions have overlapping representations. In contrast to Experiment 1, in Experiment 2, the effect of function remains robust across all comparisons.2 The difference between the two experiments suggests that, at least in this context, information about an object’s function may become available after information about its form. In the next section, we describe the crucial test of the hypothesis that these two effects are dissociable, namely, we test the interaction of attribute and exposure duration.
Comparing the Time Course of Function and Shape
Experiments 1 and 2 differed only in the amount of time that the displays were available prior to the presentation of the target word, yet we observed complementary patterns for function and shape in these two experiments. Specifically, the shape effect was reliable in all comparisons in Experiment 1, but not in any in Experiment 2. The function effect, in contrast, was reliable in only one comparison in Experiment 1, but was reliable in all comparisons in Experiment 2.
To address the critical question of whether exposure duration has reliably different effects on the activation of shape and function information, we conducted an ANOVA on the shape and function effects (i.e., the difference between the related and control objects averaged across the entire trial) in the subset of items that were perfectly matched for picture-based visual similarity. When shape and function effects were computed relative to the same object in the control condition, this test revealed no effect of exposure duration or attribute (all F’s < 1). Importantly, however, there was a significant interaction between exposure duration and attribute F1(1, 74) = 3.9, p = .05, F2(1, 29) = 5.8, p = .02. Hence, these analyses indicate that shape and function effects were reliably different at the two exposure durations (Figure 5). The same analysis was also conducted on shape and function effects computed relative to the control object in the same trial. Results were the same: no effect of exposure duration or attribute (F’s < 1), but an interaction between exposure duration and attribute F1(1, 74) = 5.0, p = .03, F2(1, 25) = 7.7, p = .01. Pairwise comparisons indicated that, as Figure 5 suggests, this interaction was driven by the shape effect decreasing with a longer exposure duration and the function effect increasing (shape: same trial control object comparison t(7) = 3.0, p = .02, same object control trial comparison t(11) = 1.6, p = .14; function: same trial control object comparison t(18)=2.2, p = .045), same object control trial comparison: t(18)=2.3, p = .03. Importantly, the presence of an interaction in the absence of a main effect of exposure duration (i.e., in the absence of a main effect of participant group) also mitigates the potential concern that differences between the two experiments could have been due to accidental baseline differences between participant groups.
Figure 5.
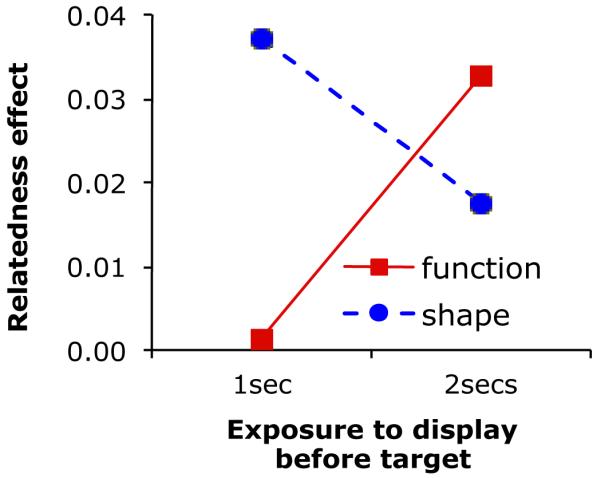
Interaction of time with averaged shape- and function- relatedness effects (i.e., the difference between the related and control objects, averaged across the entire trial), picture-based similarity matched items. Shape effect decreases over time, while function effect increases.
General Discussion
In two experiments, we used the visual world paradigm to investigate the activation of two semantic features during object recognition: one perceptual (shape) and one abstract (function). Because we explicitly manipulated the attribute that the target and the related object shared, we were able to explore the activation of these attributes independently. We observed relatedness effects for both shape and function, demonstrating that conceptual shape and function information become active as an object is recognized. However, these two attributes have different time courses of activation. Below we discuss the theoretical and methodological implications of these findings.
Why Does Function Follow Form?
Why do we observe what appears to be a difference between the activation time courses of shape and function information, with shape information becoming less prominent over time, and function information becoming more prominent? One possibility is that conceptual knowledge that is built from information that can be directly perceived through an individual sense is represented differently than conceptual knowledge that must be acquired through a more complex process. For instance, in recent years, numerous studies have demonstrated that sensory and motor brain regions that are active when perceiving or interacting with an object also become active when conceiving of it, particularly when thinking about its perceptual features (see Thompson-Schill, 2003 for a review). This suggests that long-term perceptual knowledge may be encoded in (or near) sensorimotor brain regions. More abstract information (such as an object’s function, i.e., purpose of use), on the other hand, cannot be directly perceived through any individual sense, leading some theories to posit that abstract information is stored in brain regions that integrate information over multiple sensory modalities (e.g., Patterson et al., 2007). If the same (or closely related) neural substrates support both sensory and conceptual shape, then viewing an object (and its sensory shape) may activate its conceptual shape relatively directly; in contrast, other “higher level” attributes such as purpose might be activated more indirectly, and hence more slowly, during object recognition. Notably, this account therefore suggests that when conceptual information about an object is accessed from a modality in which there is less overlap of sensory input and conceptual shape (e.g., from written words, rather than images), form might not precede function information. In the next section we describe data from the semantic priming paradigm that suggests that changing the access modality may indeed alter the extent to which form information becomes active.
But why then does shape become less active later? One possibility is that although apprehending a triangular piece of pizza (for example) will initially activate other conceptual information about pizzas, including their roundness, the direct perceptual information received about the (triangular) sensory shape allows it to “win out” over the conflicting (round) conceptual shape, resulting in a decline in activation of the conceptual roundness of pizza. A related possibility is that the timecourse difference between function and shape indicates the existence of competition between semantic features, perhaps due to limitations in our ability to maintain the activation of numerous semantic features about multiple objects simultaneously. If true, shape may rapidly decay (or perhaps be inhibited) in favor of function because while shape is critical for recognizing an object, once an object is recognized, other attributes, such as what it is used for, are typically more relevant (e.g., after recognizing that the thing across the room is pizza, what is usually relevant next is what we want to do with it). In fact, this kind of account would suggest that the features that will become more prominent over time are whatever features (abstract or perceptual) are typically more relevant once the object at hand has been recognized. Hence, although function may be critical for many manmade objects, there are also objects for which shape is likely to be more important. Indeed, for some animals (e.g., starfish) it is hard to identify a “function” as we define it here. If a feature’s importance affects its time course of activation, for objects such as starfish, conceptual shape activation may remain prominent. This suggests that a fruitful topic for future research will be to manipulate task relevance, as well as to explore how task relevance interacts with the relative informativeness of features for individual objects.
The Role of Context
The accounts raised above have a common feature – they assume that when identifying objects, the extent to which a particular type of information is activated may be contextually-dependent – either on short-term, task-related factors (i.e., how relevant is conceptual shape for the current task?) or long-term, object-related factors (i.e., is shape relevant in general for identifying this object?), or on some combination of both. The idea that there is a role for context (which we define broadly to include not only what the participant is currently attending to, but also the stimulus by which the concept is accessed, and the goals of the participant) raises an important question: Did conceptual shape information (whatever its time course) become active because it is a compulsory component of concept retrieval, or because shape information is essential for the task of visual object identification? That is, did conceptual shape precede function in our study because of the modality through which the concepts were retrieved?
To address this question, we turn to related work using the semantic priming paradigm. A small number of priming studies have tested whether responses to a written target word are facilitated when preceded by a shape-related prime word. An influential early set of priming studies (Schreuder et al., 1984; Flores d’Arcais, et al., 1985; cf. Taylor, 2005) did obtain evidence of shape priming. Intriguingly, this work also included abstractly related prime-target pairs and found evidence that abstract priming emerges more reliably at long than at short ISIs, whereas perceptual priming was larger at short than long ISIs (Schreuder et al., 1985, Flores d’Arcais et al., 1985). This may indicate that because perceptual information is dominant during the extremely frequent behavior of object recognition, it has developed a “default” early time course. However, these early studies were criticized on methodological grounds (Moss, Ostrin, Tyler, & Marslen-Wilson, 1995; Pecher et al., 1998). When they were repeated with more standard methodology, only one study reported priming for perceptually-related pairs (Taylor, 2005), and others found no priming (Kellenbach, Wijers & Mulder 2000; Pecher et al., 1998 [Exps 1-3 & 5, but see below]). The difficulty of detecting shape priming thus suggests that task relevance does play a role in the activation of shape information – when conceptual shape information is not relevant to the task at hand (e.g., when reading or performing lexical decisions), it is extremely difficult to detect behaviorally (but it may still be active – two studies recording event-related brain potentials did obtain a perceptual priming effect in N400s [Kellenbach et al., 2000; Taylor, 2005]). Significantly, one priming study (Pecher et al. [Exps 4 & 6]) provides further evidence of the importance of context – if, prior to a priming task, participants first made perceptual judgments about the objects to which the words referred, shape priming was subsequently observed.
One of the visual world paradigm studies discussed earlier also speaks to the role of context. In Huettig & McQueen, (2007), semantic relatedness effects (e.g., looks to an image of a kidney upon hearing “arm”) that were observed when displays contained only pictures, were not observed when these pictures were replaced with printed words. Instead, visual attention was drawn only to printed words that overlapped phonologically with the spoken word (e.g., the printed word artichoke, upon hearing “arm”) – presumably because matching auditory to written words emphasizes phonological information over semantic. (Interestingly, this study also varied the duration of prior exposure to the display, and although this had no influence when the visual display contained printed words, with pictures, semantic relatedness effects were robust at the longer exposure duration, but not reliable at the shorter exposure duration – consistent with our own findings.) These data support Pecher et al.’s (1998) suggestion that “what features of a word are activated is not static, but instead can be dynamically affected by the context in which the word occurs” (p. 415).
Context-dependence can also include sensitivity to properties of co-present stimuli. In our studies, a triangular slice of pizza (for example) was present in the context of a round Frisbee. It is conceivable that the roundness of the Frisbee, being directly available, enhanced the activation of the conceptual roundness of the pizza. Such “priming” could explain why conceptual shape appeared to become available more quickly than conceptual function. Yet, regardless of whether the conceptual shape of the pizza is enhanced by the shape of the Frisbee, the fact remains that the pizza’s conceptual shape becomes less active over time, following a different trajectory than its function. Hence our results demonstrate that even with a static visual context, the features of a concept that are active are not static. It remains to be seen whether the time courses of these features can be influenced by the context of the other objects in the display.
Earlier, when discussing reasons for why conceptual shape information may become less accessible over time, we suggested that this might reflect the dynamically changing aims of object identification – with shape becoming less relevant as object identification proceeds, and function becoming more relevant. But unlike shape, function was not required for performing the task we employed. Therefore, the fact that we nonetheless observed function effects may indicate that the activation of function information is a compulsory (rather than context-dependent) component of visual object recognition. However, if our task were even more shape-centric (e.g., picking out objects based on their shapes, rather than their names) perhaps shape activation would persist, and the function effect would never emerge (or would be weaker). Such context effects would both support Pecher et al’s (1998) claim, and would also be consistent with those that have been demonstrated in research on sentence comprehension, showing that, e.g., if pizza is mentioned in a sentence about delivering it, you might access how heavy it is (cf. Barclay et al., 1974). They would also be consistent with the more recently demonstrated “compatibility” effects in which sentence context (e.g., Glenberg & Kaschak, 2002), or even the context provided by an individual word (van Dam, Rueschemeyer Lindemann & Bekkering, 2010) influences the kind of action information that is activated by subsequent language. A benefit of an architecture that allows for dynamic activation is that attention can be focused on specific features, meaning that this type of architecture naturally accommodates effects that are sensitive to the task at hand (see Patterson, Nestor & Rogers, 2007).
Implications for the Organization of Semantic Memory
The co-activation of objects sharing shape or function is consistent with models in which semantic memory is organized such that objects that share these features have overlapping representations. The observed time course difference between shape and function also has implications for the organization of semantic knowledge. First, because the features follow different time courses of activation, it suggests that shape and function are distinct components of semantic knowledge. Although we have suggested that the time course differences we observed are due to differences in the features themselves (or their relevance in a given context), another possibility is that the differences are due to the specificity of the features; it has been proposed by Rogers and Patterson (2007) that semantic memory is organized such that “specific” information about an object – information that can distinguish among objects in the same semantic neighborhood (e.g., the property “yellow” distinguishes between lemons and limes) – becomes available later than more “general” information – information that does not help in distinguishing among objects in the same neighborhood (e.g., the property “can be eaten” is shared by most fruit). Interestingly, however, the patterns that we observe for function and shape do not appear to be consistent with the specificity hypothesis: we find that the arguably more specific feature, shape, becomes available earlier than the arguably more general feature, function. The time course differences we observed, therefore, appear to be due to the content of the features (or perhaps the interaction of that content with the task at hand), rather than their usefulness for distinguishing between semantic neighbors.
Because shape is a sensorimotor feature, the findings for shape in particular provide important evidence for one of the predictions of sensorimotor-based distributed models of semantic memory – if our knowledge of objects is distributed across a set of semantic features that are situated in the neural substrates that are responsible for perceiving and interacting with these objects (e.g., Allport, 1985; Barsalou, 1999; Warrington & McCarthy, 1987), then the conceptual representations of objects that share a perceptual feature such as shape must have overlapping representations. Yet until now, behavioral evidence in support of this prediction has been scarce. In contrast to shape, information about an object’s purpose is unlikely to be a unitary sensorimotor-based feature; although function information is related to an object’s shape, size and the way it is manipulated, an object’s function cannot reliably be predicted from any individual perceptual feature. Thus, the finding for function demonstrates that representations cannot be entirely sensorimotor-based. Most sensorimotor theories, however, do suggest that more abstract, higher-order relationships (e.g., function) can be represented either in an amodal association area or can emerge as a result of similarity between multiple sets of features (e.g., Damasio, 1989; Humphreys & Forde, 2001; Rogers et al., 2004; Simmons & Barsalou, 2003).
We have discussed our results in the context of distributed models because these models very naturally accommodate the findings. However, there are alternative models of semantic memory. One prominent alternative is the “domain-specific” category-based model (Caramazza & Shelton, 1998). According to this model, concepts are represented according to a few innately specified categories (e.g., animals, fruits/vegetables, conspecifics, and tools) that have evolutionary significance, and objects from different categories (e.g., Frisbees and pizzas) have distinct, non-overlapping representations. Because we observed relatedness effects for shape-related pairs that contained items from different categories (twenty of 24 pairs are indisputably cross-category, and the pattern of results is unchanged when the remaining four pairs are removed ), the current results are inconsistent with this category-based model. A recent elaboration of this model (e.g., Mahon & Caramazza, 2003) is partially distributed in that it allows for representations to be distributed over different sensory modalities. However, within each modality, the representations of different categories (e.g., tools and food) remain distinct. Hence, even this partially distributed category-based model would be inconsistent with the shape-based cross-category co-activation that we observed in Experiment 1. To accommodate the cross-category shape effect under a category-based account would require positing an additional (extra-representational) process which operates across categories. However, such an explanation would be difficult to reconcile with the fact that the shape effect emerges prior to the predominantly within-category function effect, and becomes smaller over time – if additional processing were responsible, one would expect the shape effect to grow over time. A category-based model therefore appears incompatible with the pattern we observed. Another alternative to distributed models is a localist model in which activation spreads over propositional (i.e., featural) links between concepts (e.g., [is round] or [sticks thing together]). A version of the model that allows for different propositions to be activated over different time courses (e.g., Collins & Loftus, 1975) would be consistent with the timecourse differences we observed. However, to fully accommodate the current findings, such a model would also need to posit that information contained in these links can also deactivate over different time courses. It is worth noting that if these components (connections that explicitly represent featural information, and which have distinct timecourses of activation and deactivation) are assumed, the predictions of localist and distributed models essentially converge.
Methodological Implications
That there were differences between the results of Experiments 1 and 2 has methodological implications for using the visual world paradigm to study semantic relatedness. As the differences between Experiments 1 and 2 demonstrate, there is no logical necessity for all of the information required to observe semantic relatedness effects to be available when we begin to observe a preference for the target. This means that if a particular semantic attribute is slow to become active, and the amount of time provided to view the objects is short, then there is no reason to expect a relatedness effect based on that particular attribute. Therefore, when relying on relatedness effects to reveal the activation of specific semantic attributes it may be necessary to vary exposure duration to obtain a full picture of their activation. Hence, the visual world paradigm can provide information about both the activation dynamics of objects in the display, and the processing of the heard word, but the processing that can be detected at a given time is limited by their shared activation. This is an important methodological implication because most prior researchers have not considered that preview time may critically influence the visual world paradigm’s sensitivity to different relatedness effects.
Conclusions
The present findings suggest that during object identification, long-term knowledge about an object’s perceptual (shape) and abstract (function) features become active along different time courses, with function following form. The fact that these two components of semantic knowledge can have distinct time courses demonstrates that semantic memory is organized such that they are at least partially independent. Further, the co-activation of shape- or function-related objects suggest that semantic memory is organized such that concepts that share these features have overlapping representations. The observed co-activation of shape-related objects from different categories is difficult to reconcile with a category-based model (e.g., Caramazza & Shelton, 1998). Instead, the findings for shape are easy to accommodate in models that suggest that object meanings are represented (at least in part) as distributed patterns of activation because these models allow for independent activation. The findings for function (an “abstract” feature that cannot be directly observed through a single sensory modality) make it clear that models of semantic memory must include a mechanism for representing abstract, as well as sensorimotor-based features (see Patterson, et al., 2007 for a review). Finally, the results demonstrate that conceiving of an object is a dynamically unfolding process in which the “meaning” of an object evolves as object identification proceeds.
Acknowledgments
This research was supported by NIH Grant (R01MH70850) awarded to Sharon Thompson-Schill and by a Ruth L. Kirschstein NRSA Postdoctoral Fellowship (F32HD051364, from the National Institute of Child Health and Human Development) awarded to Eiling Yee. We are grateful to Jason Taylor, Katherine White and Gerry Altmann for enormously helpful discussions and comments. We also thank Eve Overton, Amir Francois, and Emily McDowell for assistance with data collection. Portions of this research were presented at the 15th Annual Meeting of the Cognitive Neuroscience Society, San Francisco, CA, April 2008.
Appendix
Shape Stimuli from Experiments 1 and 2
| List | Target Unrelated |
Related Control for related in other list |
Target’s Control Target |
Related’s Control Unrelated |
|---|---|---|---|---|
| A | bagel | tire | dart | cloud |
| A | ball | moon | glass | iron |
| A | cigarette | worm | basketball | honey |
| A | daisy | fan | crayon | chain |
| A | football | lemon | chicken | thread |
| A | frisbee | pizza | thimble | pitcher |
| A | grenade | lime | toothbrush | stamp |
| A | puck | cookie | mallet | spider |
| A | rope | cobra | drum | muffin |
| A | spaghetti | hay | ruler | tub |
| A | tennis ball | apple | paintbrush | wine |
| A | tile | napkin | perfume | helmet |
| B | balloon | watermelon | screw | comb |
| B | baseball | orange | telephone | refrigerator |
| B | bomb | peach | desk | slippers |
| B | cigar | candle | garlic | drill |
| B | hat | cake | speaker | pipe |
| B | mountain | funnel | window | giraffe |
| B | rolling pin | corn | lollipop | bear |
| B | softball | grapefruit | mustard | kettle |
| B | teepee | birdie (badminton) | snowman | whistle |
| B | towel | flag | rabbit | plant |
| B | volleyball | cantaloupe | thermometer | kite |
| B | yardstick | belt | lighter | cup |
Note. Rows depict displays. Each display was presented to subjects receiving lists A and B. Plain text column headers indicate the assignment of objects to conditions for the list indicated in column one, while italic headers indicate the assignment of objects to conditions for the other list. For example, for participants receiving list A, tape was the target, glue was the function-related object, penny was the target’s control, and cane was the related object’s control. Participants receiving list B saw the same display, but penny was the target, glue was a control for the related object in list A, and tape and cane were unrelated objects.
Function Stimuli from Experiments 1 and 2
| List | Target Unrelated |
Related Control for related in other list |
Target’s Control Target |
Related’s Control Unrelated |
|---|---|---|---|---|
| A | bullet | arrow | camera | envelope |
| A | candle | lightbulb | yarn | pliers |
| A | cannon | slingshot | monkey | hoe |
| A | cherry | banana | puppet | motorcycle |
| A | clock | hourglass | pencil | teeshirt |
| A | fork | chopsticks | jeep | lighthouse |
| A | handcuffs | cage | beaker | straw |
| A | harmonica | clarinet | glasses | medal |
| A | map | globe | pump | barn |
| A | piano | trumpet | well | lamp |
| A | radiator | fire | sock | table |
| A | rice | bread | wheel | coat |
| A | shower | dishwasher | mirror | chisel |
| A | sunglasses | cap | blackboard | jacket |
| A | tape | glue | penny | cane |
| A | zipper | buckle | mattress | wok |
| B | battery | plug | keyboard | walker |
| B | calculator | abacus | hammer | ladle |
| B | cassette | CD | vacuum | gift |
| B | cooler | thermos | dolphin | gravestone |
| B | dice | cards | vase | church |
| B | gun | sword | wagon | pear |
| B | hair dryer | towel | roller-skate | nail |
| B | hanger | clothespin | ashtray | spatula |
| B | horn | bell | skirt | key |
| B | jet | helicopter | brush | glove |
| B | lantern | flashlight | spoon | microscope |
| B | saw | axe | crown | vest |
| B | sponge | mop | olive | cleaver |
| B | stapler | paperclip | dustpan | windmill |
| B | suitcase | backpack | notebook | mailbox |
| B | umbrella | raincoat | pillow | scissors |
Footnotes
Ratings for one shape-related object pair were not collected due to experimenter error.
We repeated all analyses without including the picture-based visual similarity covariate. The pattern of results remained the same except that when the covariate was not included, the relatedness effects were stronger for function in Experiment 1, and (less so) for shape in Experiment 2. (If picture-based similarity did direct some amount of visual attention to related objects, it is unsurprising that relatedness effects would be larger when picture-based shape is allowed to play a role. Moreover, because the function-related pairs were not expressly created to control for picture-based shape, it may have artificially increased the size of the function effect in particular. Further, given that shape similarity effects appear to occur at shorter exposures, the increase might be expected to be largest in the short exposure condition.) Experiment 1, shape: There was a significant conceptual shape effect when fixations on the shape-related object were compared to the same object in the control condition (related: M = .084, SE = .006, control: M = .066, SE = .005) F1(1, 37) = 6.2, p =. 02, and F2(1, 23) = 7.7, p = .01, and also when fixations on the related object were compared with fixations on the control picture in the same display (M = .061, SE = .006), F1(1, 37) = 6.7, p = .01, and F2(1, 23) = 6.1, p = .02. Experiment 1, function: There was a significant function effect by subjects when fixations on the function-related object were compared to the same object in the control condition, and a marginally significant effect by items (related: M = .086, SE = .008, control: M = .066, SE = .006) F1(1, 37) = 5.9, p = .02; F2(1, 31) = 4.2, p = .05. When fixations on the function-related object were compared to the control picture in the same display (M = .054, SE = .004), the effect of function was significant both by subjects and items F1(1, 37) = 14.7, p < .001, F2(1, 31) = 15.8, p < .001). Experiment 2, shape: By subjects, there was a significant conceptual shape effect when fixations on the shape-related object were compared to the same object in the control condition (related: M = .079, SE = .006, control: M = .056, SE = .006) F1(1, 37) = 12.0, p = . 001, but by items this difference only approached significance F2(1, 23) = 2.9, p = .10. There was no effect when fixations on the shape-related object were compared to the control picture in the same display (M = .069, SD = .005) F1(1, 37) = 1.8, p = .19, F2(1, 23) < 1. Experiment 2, function: There was a significant function effect when fixations on the function-related object were compared to the same object in the control condition (related: M = .098, SE = .007, control: M = .067, SE = .005), F1 (1, 37) = 15.3, p < .001, F2(1, 31) = 14.2, p < .001, and also when fixations on the function-related object were compared with fixations on the control picture in the same display (related: M = .098, SE = .007, control: M = .050, SE = .006) F1(1, 37) = 43.7, p < .001, F2(1, 31) = 34.4, p < .001. Testing the interaction between exposure duration and attribute revealed that when compared to the same object in the control condition, the interaction was not significant (F1 < 1; F2(1, 54) = 1.2, p = .27). However, when compared to the control picture in the same display, the interaction between exposure duration and attribute approached significance by subjects F1(1, 74) = 3.3, p = .08, and was significant by items F2(1, 54) = 5.4, p = .02. Hence, even when differences between exposure durations are presumably dampened (due to disproportionate augmentation of the short-exposure function effect), the interaction pattern between exposure duration and attribute noted in the main text is still present.
Publisher's Disclaimer: The following manuscript is the final accepted manuscript. It has not been subjected to the final copyediting, fact-checking, and proofreading required for formal publication. It is not the definitive, publisher-authenticated version. The American Psychological Association and its Council of Editors disclaim any responsibility or liabilities for errors or omissions of this manuscript version, any version derived from this manuscript by NIH, or other third parties. The published version is available at www.apa.org/pubs/journals/xge
References
- Allport DA. Distributed memory, modular subsystems and dysphasia. In: Newman SK, Epstein R, editors. Current Perspectives in Dysphasia. Churchill Livingstone; Edinburgh: 1985. pp. 207–244. [Google Scholar]
- Altmann GTM, Kamide Y. Now you see it, now you don’t: mediating the mapping between language and the visual world. In: Henderson J, Ferreira F, editors. The interface of language, vision, and action. Psychology Press; 2004. To appear in. [Google Scholar]
- Altmann GTM, Kamide Y. The real-time mediation of visual attention by language and world knowledge: Linking anticipatory (and other) eye movements to linguistic processing. Journal of Memory and Language. 2007;57:502–518. [Google Scholar]
- Barclay JR, Bransford JD, Franks JJ, McCarrell NS, Nitsch KE. Comprehension and semantic flexibility. Journal of Verbal Learning and Verbal Behavior. 1974;13:471–481. [Google Scholar]
- Barsalou LW. Perceptual symbol systems. Behavioral and Brain Sciences. 1999;22:577–660. doi: 10.1017/s0140525x99002149. [DOI] [PubMed] [Google Scholar]
- Bates Timothy C., Oliveiro L. PsyScript: A Macintosh Application for Scripting Experiments. Behavior Research Methods, Instruments, & Computers. 2003;34(5):565–576. doi: 10.3758/bf03195535. [DOI] [PubMed] [Google Scholar]
- Caramazza A, Shelton JR. Domain-specific knowledge systems in the brain the animate-inanimate distinction. Journal of Cognitive Neuroscience. 1998;10:1–34. doi: 10.1162/089892998563752. [DOI] [PubMed] [Google Scholar]
- Collins AM, Loftus EF. A spreading-activation theory of semantic processing. Psychological Review. 1975;82:407–428. [Google Scholar]
- Dahan D, Tanenhaus MK. Looking at the rope when looking for the snake: Conceptually mediated eye movements during spoken-word recognition. Psychonomic Bulletin & Review. 2005;12(3):453–459. doi: 10.3758/bf03193787. [DOI] [PubMed] [Google Scholar]
- Damasio AR. Time-locked multiregional retroactivation: A systems-level proposal for the neural substrates of recall and recognition. Cognition. 1989;33:25–62. doi: 10.1016/0010-0277(89)90005-x. [DOI] [PubMed] [Google Scholar]
- Flores d’Arcais G, Schreuder R, Glazenborg G. Semantic activation during recognition or referential words. Psychological Research. 1985;47:39–49. [Google Scholar]
- Francis WN, Kucera H. Frequency analysis of English usage: Lexicon and grammar. Mifflin Co; Boston, Houghton: 1982. [Google Scholar]
- Glenberg AM, Kaschak MP. Grounding language in action. Psychonomic Bulletin & Review. 2002;9(3):558–565. doi: 10.3758/bf03196313. [DOI] [PubMed] [Google Scholar]
- Godfrey JJ, Holliman EC, McDaniel J. SWITCHBOARD: Telephone speech corpus for research and development. IEEE ICASSP. 1992:517–520. [Google Scholar]
- Huettig F, Altmann GTM. Word meaning and the control of eye fixation: semantic competitor effects and the visual world paradigm. Cognition. 2005;96:B23–B32. doi: 10.1016/j.cognition.2004.10.003. [DOI] [PubMed] [Google Scholar]
- Huettig F, Altmann GTM. Visual-shape competition during language-mediated attention is based on lexical input and not modulated by contextual appropriateness. Visual Cognition. 2007;15(8):985–1018. [Google Scholar]
- Huettig F, Altmann GTM. Looking at anything that is green when hearing ‘frog’ - How object surface colour and stored object colour knowledge influence language-mediated overt attention. Quarterly Journal of Experimental Psychology. 2010 doi: 10.1080/17470218.2010.481474. [DOI] [PubMed] [Google Scholar]
- Huettig F, McQueen JM. The tug of war between phonological, semantic and shape information in language-mediated visual search. Journal of Memory and Language. 2007;57:460–482. [Google Scholar]
- Humphreys GW, Forde EME. Hierarchies, similarity, and interactivity in object recognition: “Category-specific” neuropsychological deficits. Behavioral and Brain Sciences. 2001;24:453–509. [PubMed] [Google Scholar]
- Kellenbach ML, Wijers AA, Mulder G. Visual semantic features are activated during the processing of concrete words: Event-related potential evidence for perceptual semantic priming. Cognitive Brain Research. 2000;10(1-2):67–75. doi: 10.1016/s0926-6410(00)00023-9. [DOI] [PubMed] [Google Scholar]
- Lucas M. Semantic priming without Association: A Meta-analytic Review. Psychonomic Bulletin & Review. 2000;1:618–630. doi: 10.3758/bf03212999. [DOI] [PubMed] [Google Scholar]
- Mahon BZ, Caramazza A. Constraining questions about the organisation and representation of conceptual knowledge. Cognitive Neuropsychology. 2003;20:433–50. doi: 10.1080/02643290342000014. [DOI] [PubMed] [Google Scholar]
- Masson MEJ. A distributed memory model of semantic priming. Journal of Experimental Psychology: Learning, Memory and Cognition. 1995;21:3–23. [Google Scholar]
- McRae K, de Sa VR, Seidenberg MS. On the nature and scope of featural representations of word meaning. Journal of Experimental Psychology: General. 1997;126:99–130. doi: 10.1037//0096-3445.126.2.99. [DOI] [PubMed] [Google Scholar]
- Meyer DE, Schvaneveldt RW. Facilitation in recognizing pairs of words: Evidence of a dependence between retrieval operations. Journal of Experimental Psychology. 1971;90:227–234. doi: 10.1037/h0031564. [DOI] [PubMed] [Google Scholar]
- Mitchell MP, Santorini B, Marcinkiewicz MA. Building a Large Annotated Corpus of English: The Penn Treebank. Computational Linguistics. 1993;19.2:313–330. [Google Scholar]
- Mirman D, Magnuson JS. Dynamics of activation of semantically similar concepts during spoken word recognition. Memory & Cognition. 2009;37(7):1026–1039. doi: 10.3758/MC.37.7.1026. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Moss HE, McCormick SF, Tyler LK. The time course of activation of semantic information during spoken word recognition. Language and Cognitive Processes. 1997;12:695–731. [Google Scholar]
- Moss HE, Ostrin RK, Tyler LK, Marslen-Wilson WD. Accessing different types of lexical semantic information: Evidence from priming. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1995;21(4):863–883. [Google Scholar]
- Myung J, Blumstein SE, Sedivy J. Playing on the typewriter and typing on the piano: Manipulation Features of Man-made Objects. Cognition. 2006;98:223–243. doi: 10.1016/j.cognition.2004.11.010. [DOI] [PubMed] [Google Scholar]
- Nelson DL, McEvoy CL, Schreiber TA. The University of South Florida word association, rhyme, and word fragment norms. 1998 doi: 10.3758/bf03195588. http://www.usf.edu/FreeAssociation/ [DOI] [PubMed]
- Patterson K, Nestor PJ, Rogers TT. Where do you know what you know? The representation of semantic knowledge in the human brain. Nature Reviews Neuroscience. 2007;8:976–987. doi: 10.1038/nrn2277. [DOI] [PubMed] [Google Scholar]
- Pecher D, Zeelenberg R, Raaijmakers JGW. Does pizza prime coin? Perceptual priming in lexical decision and pronunciation. Journal of Memory and Language. 1998;38:401–418. [Google Scholar]
- Rogers TT, Ralph M.A. Lambon, Garrard P, Bozeat S, McClelland JL, Hodges JR, et al. The structure and deterioration of semantic memory: A computational and neuropsychological investigation. Psychological Review. 2004;111:205–235. doi: 10.1037/0033-295X.111.1.205. [DOI] [PubMed] [Google Scholar]
- Rogers TT, Patterson K. Object categorization: reversals and explanations of the basic-level advantage. Journal of Experimental Psychology: General. 2007;136:451–469. doi: 10.1037/0096-3445.136.3.451. [DOI] [PubMed] [Google Scholar]
- Rossion B, Pourtois G. Revisiting Snodgrass and Vanderwart’s object set: The role of surface detail in basic-level object recognition. Perception. 2004;33:217–236. doi: 10.1068/p5117. [DOI] [PubMed] [Google Scholar]
- Schreuder R, Flores D’Arcais GB, Glazenborg G. Effects of perceptual and conceptual similarity in semantic priming. Psychological Research. 1984;45(4):339–354. [Google Scholar]
- Simmons WK, Barsalou LW. The similarity-in-topography principle: Reconciling theories of conceptual deficits. Cognitive Neuropsychology. 2003;20(3-6):451–486. doi: 10.1080/02643290342000032. [DOI] [PubMed] [Google Scholar]
- Snodgrass JG, Vanderwart M. A standardized set of 260 pictures: Norms for name agreement, image agreement, familiarity, and visual complexity. Journal of Experimental Psychology: Human Learning and Memory. 1980;6:174–216. doi: 10.1037//0278-7393.6.2.174. [DOI] [PubMed] [Google Scholar]
- Taylor JR. Unpublished Doctoral Dissertation. 2005. On The Perceptual Basis of Semantic Memory: Representation, process and attentional control revealed by behavior and event-related brain potentials. [Google Scholar]
- Taylor JR, Heindel W. Priming Perceptual and Conceptual semantic knowledge: Evidence for automatic and strategic effects; Cognitive Neuroscience Society Annual Meeting Program; 2001.2001. [Google Scholar]
- Thompson-Schill SL. Neuroimaging studies of semantic memory: Inferring how from where. Neuropsychologia. 2003;41:280–2. doi: 10.1016/s0028-3932(02)00161-6. [DOI] [PubMed] [Google Scholar]
- Tyler LK, Moss HE, Durrant-Peatfield M, Levy JP. Conceptual structure and the structure of concepts: A Distributed Account of Category Specific Deficits. Brain and Language. 2000;75(2):195–231. doi: 10.1006/brln.2000.2353. [DOI] [PubMed] [Google Scholar]
- Tyler LK, Moss HE. Towards a distributed account of conceptual knowledge. Trends in Cognitive. Science. 2001;5:244–52. doi: 10.1016/s1364-6613(00)01651-x. [DOI] [PubMed] [Google Scholar]
- Warrington EK, McCarthy RA. Categories of knowledge. Further fractionations and an attempted integration. Brain. 1987;110(Pt 5):1273–1296. doi: 10.1093/brain/110.5.1273. [DOI] [PubMed] [Google Scholar]
- van Dam WO, Rueschemeyer SA, Lindemann O, Bekkering H. Context effects in embodied lexical-semantic processing. Frontiers in Psychology. 2010;1:150. doi: 10.3389/fpsyg.2010.00150. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yee E, Sedivy J. Using eye movements to track the spread of semantic information during spoken word recognition; Paper presented at the 14th annual CUNY Conference on Human Sentence Processing; Philadelphia, PA. 2001. [Google Scholar]
- Yee E, Sedivy J. Eye movements to pictures reveal transient semantic activation during spoken word recognition. Journal of Experimental Psychology: Learning, Memory and Cognition. 2006;32:1–14. doi: 10.1037/0278-7393.32.1.1. [DOI] [PubMed] [Google Scholar]