
Table 1. The posterior probability results for the simulated data sets.
| prior probability | sample size | times true model was highest | avg. posterior probability of true models | avg. posterior probability of best false models | avg. posterior probability of all false models |

|
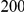
|
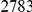
|

|
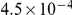
|
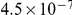
|
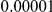
|

|

|

|
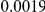
|

|

|

|

|
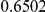
|

|
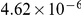
|

|
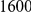
|
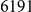
|

|

|
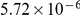
|
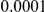
|
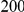
|

|
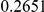
|

|

|
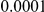
|

|

|
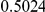
|

|
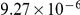
|
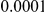
|
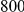
|

|
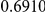
|

|
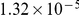
|

|
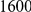
|

|

|
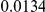
|
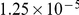
|
The 1st column shows whether the smaller or larger priors were used; the 3rd column shows the number of times (out of 7000 data sets) the true (i.e., the data-generating) model had the highest posterior probability; the 4th column shows the average posterior probability of the true models; the 5th column shows the average posterior probability of the most probable false models (in each of the 7000 data sets); and the last column shows the average posterior probabilities of all false models.