
Figure 1. Identification of sources present in complex auditory scenes using large dictionaries.

(A) Auditory scenes are composed of sounds generated by different sources. (B) Blind source separation methods estimate the sources present in a scene based only on the observed scene. (C) Other algorithms assume that the sources present in a scene are part of a very large dictionary of possible sources (represented by the collection of pictures and the associated sounds). (D) These algorithms also assume that the sources present are combined linearly, (vectors 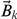 multiplied by the time varying amplitude
multiplied by the time varying amplitude 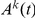 ), to generate the time varying scene (time-varying vector
), to generate the time varying scene (time-varying vector 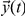 ). (E) Algorithms as in D create an estimate of the observed signal by combining elements of the dictionary, each one weighted by an time varying estimated parameter
). (E) Algorithms as in D create an estimate of the observed signal by combining elements of the dictionary, each one weighted by an time varying estimated parameter 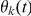 . For large dictionaries, there are multiple estimated parameters that create an estimate of the observation that matches equally well to the observed signal (represented by the different combinations of vectors inside the large square that generate the same well-matched estimate
. For large dictionaries, there are multiple estimated parameters that create an estimate of the observation that matches equally well to the observed signal (represented by the different combinations of vectors inside the large square that generate the same well-matched estimate 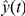 ). A single solution is chosen by minimizing the number of active dictionary elements (vector combination inside the smaller square). (F) At each time step, a new set of parameters
). A single solution is chosen by minimizing the number of active dictionary elements (vector combination inside the smaller square). (F) At each time step, a new set of parameters 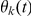 is estimated that reflect the contribution of the identified dictionary element to the current auditory scene
is estimated that reflect the contribution of the identified dictionary element to the current auditory scene 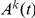 . The other estimated parameters
. The other estimated parameters 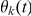 are zero.
are zero.