

Abstract
Quantifying behavior often involves using variables that contain measurement errors and formulating multiequations to capture the relationship among a set of variables. Structural equation models (SEMs) refer to modeling techniques popular in the social and behavioral sciences that are equipped to handle multiequation models, multiple measures of concepts, and measurement error. This work provides an overview of latent variable SEMs. We present the equations for SEMs and the steps in modeling, and we provide three illustrations of SEMs. We suggest that the general nature of the model is capable of handling a variety of problems in the quantification of behavior, where the researcher has sufficient knowledge to formulate hypotheses.
Keywords: error in variables, factor analysis, path analysis, LISREL, covariance structures
Among the many problems in quantifying behavior are the challenges presented by the multiple equations to study and the difficulty of accurately measuring key concepts. For instance, scientists might be interested in general arousal and how it relates to more specific forms of arousal, or researchers might want to analyze quality of sleep and it relationship to different forms and intensities of pain. Arousal, quality of sleep, pain intensity, and numerous other variables are difficult to measure without considerable measurement error. Additionally, studying how several or more of these difficult to measure latent variables relate to each other is an even more arduous task when the multiequation nature of the problem is included.
Ignoring these issues leads to inaccuracy of findings. Ignoring the measurement error in arousal or pain data, for instance, leads to inaccurate assessments of effects. Therefore, our assessment of perception of pain on quality of sleep is unlikely to be correct if we do not take account of the measurement error. We might have several ways to measure the same latent arousal variable and not be sure how to incorporate these ways into the model. Also, if we ignore the indirect effects of one variable on another variable and concentrate only on the direct effect, we are more likely to be mistaken in our assessment of how one variable affects another variable.
Structural equation models (SEMs) refer to modeling techniques popular in the social and behavioral sciences that are equipped to handle multiequation models, multiple measures of concepts, and measurement error. This general model incorporates more familiar models as special cases. For instance, multiple regression is a special form of SEM, where there is a single dependent variable and multiple covariates and the covariates are assumed to be measured without measurement error. ANOVA is a another specialization where the covariates are assumed to be dichotomous variables. Factor analysis is yet another special form of the latent variable SEM. Here, we assume that we have multiple indicators that measure one or more factors and that the factors are permitted to correlate or not correlate. Recursive models, nonrecursive models, growth curve models, certain fixed and random effects models, etc. can all be incorporated as special cases of the general latent variable SEM. However, the structural component in SEM reflects that the researcher is bringing causal assumptions to the model, whereas multiple regression, ANOVA, etc. might be applied purely for descriptive purposes without any causal assumptions (1).
The purpose of this work is to give a brief overview of latent variable SEMs and to illustrate them with several hypothetical examples. It is meant to give the reader a sense of the potential of these procedures for research on the quantification of behavior. The next section explains SEMs with a brief verbal description followed by a more formal model of latent variable SEMs and its assumptions. This section is followed by a section that contains three illustrations. These illustrations are examples meant to give the reader a flavor of the type of applications that might be done. The section on illustrations is followed by the conclusions.
What Are SEMs?
SEMs are traceable at least back to the path analysis work of Wright (1, 2). SEMs did not receive much attention until they were introduced into sociology in the 1960s by Blalock (3) and Duncan (4). From sociology, they spread to the other social sciences and psychology. A turning point was the development of the LISREL model by Jöreskog (5) and the LISREL SEM software. There have been numerous contributors to SEM from several disciplines, and we cannot fully describe these here. However, historic reviews are available from several sources (6, 7). SEMs have continued to diffuse through numerous disciplines and are reaching beyond the social and behavioral sciences into biostatistics, epidemiology, and other areas. Furthermore, there are a variety of SEM software packages, including LISREL (8), Mplus (9), AMOS (10), EQS (11), and the SEM procedure in R (12).
SEMs are marked by typically including two or more equations in the model. This process differs from the usual single equation regression model that has a single dependent variable and multiple covariates. In SEMs, it is not unusual to have a number of equations with several explanatory variables in each equation. The usual terms of dependent variable and independent variable make less sense in this context, because the dependent variable in one equation might be an independent variable in another equation. For this reason, the variables in a model are called either endogenous or exogenous variables. At the risk of oversimplifying, endogenous variables are variables that appear as dependent variables in at least one equation. Exogenous variables are never dependent variables and typically, are allowed to correlate with each other, although explaining the source of their associations is not part of the model.
Another division among the variables is between latent and observed variables. Latent variables are variables that are important to the model but for which we have no data in our dataset (13). Observed variables are variables that are part of our analysis but for which we have values in our dataset. For instance, sharp pain might be a latent variable of interest, and the self-reports of perceived sharp pain would be an observed variable to measure it. We recognize that the subjective measure is a less than perfect measure of the latent variable of sharp pain. Indeed, we could devise several differently worded questions to try to tap the latent sharp pain variable. With SEMs, we would build a measurement model of the relationship between each indicator and the latent sharp pain variable. This model would enable us to estimate the relationship between each indicator and the latent variable and determine which measure is the most closely related to the latent variable.
Similarly, if interest lies in another latent variable such as quality of sleep, then we could follow a similar procedure to develop several indicators of sleep quality and build a measurement model with each indicator related to the sleep quality latent variable. Combining the measurement model of sleep quality with that for sharp pain, we could construct a latent variable model that examines whether the latent sharp pain variable influences the latent sleep quality variable while controlling for the measurement error in the indicators.
The preceding discussion illustrates that the latent variable SEM permits us to study the relationships of latent variables to each other and between latent and observed measures of these latent variables. By so doing, the analysis can study the relationships among the theoretical variables of primary interest without having the effects confounded with measurement error. In addition, the analysis permits assessment of which measures seem to be most closely related to the latent variables.
Model.
The last section gave more of a verbal than formal description of the latent variable SEMs. In this subsection, we present the model and assumptions more formally. The latent variable SEM is conveniently divided into two parts: the latent variable model and the measurement model. The latent variable model (sometimes called the structural model) is (Eq. 1)
where ηi is a vector of latent endogenous variables for unit i, αη is a vector of intercept terms for the equations, B is the matrix of coefficients giving the expected effects of the latent endogenous variables (η) on each other, ξi is the vector of latent exogenous variables, Γ is the coefficient matrix giving the expected effects of the latent exogenous variables (ξ) on the latent endogenous variables (η), and ζi is the vector of disturbances. The i subscript indexes the ith case in the sample. We assume that E(ζi) = 0, COV(ξi′, ζi) = 0, and (I − B) is invertible. As we stated, exogenous variables are variables that are not explained within the model and that are uncorrelated with all disturbances in the system. Endogenous variables are variables that are directly influenced by other variables in the system other than its disturbance. Two covariance matrices are part of the latent variable model: Σξξ is the covariance matrix of the exogenous latent variables (ξ) and Σζζ is the covariance matrix of the equation disturbances (ζ). The mean of ξ is μξ.
The latent variable model reflects the hypotheses about how the different concepts such as perceived pain and quality of sleep relate to each other. In its general form, it incorporates any number of endogenous or exogenous latent variables.
The measurement model links the latent to the observed responses (indicators). It has two equations (Eqs. 2 and 3),
where yi and xi are vectors of the observed indicators of ηi and ξi, respectively, αy and αx are intercept vectors, Λy and Λx are matrices of factor loadings or regression coefficients giving the impact of the latent ηi and ξi on yi and xi, respectively, and εi and δi are the unique factors of yi and xi. We assume that the unique factors (εi and δi) have expected values of zero, have covariance matrices of Σεε and Σδδ, respectively, and are uncorrelated with each other and with ζi and ξi.
Using these equations, we can illustrate the generality of the model. First, researchers can do all confirmatory factor analysis models using only Eq. 3. This model includes the observed variables or measures in the vector xi, the factor loadings are in the Λx matrix, and the intercepts of the equation are in αx. The δi vector contains the unique factors. We could have just as easily used Eq. 2 to present the confirmatory factor analysis model.
Multiple regression provides another example. By introducing the restrictions of assuming no measurement error in xi (αx = 0, Λx = I, Σδδ = 0) and no error in yi (αy = 0, Λy = I, Σεε = 0), using a single dependent variable (yi is a scalar), and setting B = 0, we get a multiple regression model where the implicit assumption of no measurement error is made explicit. ANOVA follows if we let xi consist only of dummy variables.
Econometrics developed the idea of simultaneous equation models, which is a multiequation model where a series of endogenous variables are related to each other as well as to a series of exogenous variables. Unlike regression, simultaneous equations have multiple equations rather than a single one. However, like multiple regression, measurement error is assumed absent. By assuming that there is a single observed variable for each latent variable and that there is no measurement error (i.e., αx = 0, Λx = I, Σδδ = 0, αy = 0, Λy = I, and Σεε = 0), the latent variable model becomes (Eq. 4)
and this equation is equivalent to the simultaneous equation model from econometrics that is used in some of the other social sciences as well. Furthermore, nonlinear models that relate dichotomous, ordinal, or censored observed variables to the latent variables also are possible (14), although we do not cover these models in this overview. Special cases of this model include fully recursive and nonrecursive models that also assume no measurement errors.
The general model also incorporates growth curve models, random and fixed effects models, and a large number of other models that are used in statistical modeling. Below, Illustrations, Illustration 2 will show a growth curve model; however, other applications of the general model are not shown here (6).
Modeling Steps.
Latent variable SEM occurs in a series of steps. These steps include model specification, model-implied moments, identification, estimation, model fit, and respecification. We give an overview of each step.
Model specification.
Model specification is the term that refers to the formulation of the model. It involves specifying the primary latent variables and how they relate to each other. It also involves constructing the measurement model that specifies the relationship between the latent and observed variables and whether there are any correlated unique factors predicted. Another way of understanding this step is that it gives the specific composition and form of the matrices that are in the latent variable and measurement models.
The information necessary for model specification comes from the subject matter experts and their knowledge of theory and prior research in this area. If the information in an area leads to two or more different models, the researcher should use all plausible models. Later in the process, the fit of these different models can be compared to determine which is more consistent with the data.
The model specification step makes it difficult for statisticians or biostatisticians to use SEM unless they have substantive expertise or are collaborating with a colleague who has this knowledge.
Model specification is done using the latent variable and measurement models from the SEM or sometimes, is represented in a path diagram. A path diagram is a figure that represents the latent variable and measurement models for a particular application. Later, we provide examples of path diagram, and we will explain their symbols.
Model-implied moments.
After a model is specified, it has implications for the observed variables. One set of implications has to do with predicting the means, variances, and covariances of the observed variables using the parameters from the model specification. These means, variances, and covariances are the moments of the observed variables.
The parameters of the model are placed in a vector called θ. If a model specification is valid, then the following mean and covariance structures hold (Eqs. 5 and 6):
The implication is that if the model is true, then the parameters (θ) of the model should enable us to exactly predict the means, variances, and covariances of the observed variables. In other words, there should be an exact match between the population means, variances, and covariances and those values implied by the parameters in the model.
These implied moments are useful in estimating and assessing the fit of a model. They also are useful in establishing model identification, a topic to which we now turn.
Identification.
Identification concerns whether it is possible to uniquely estimate values of all of the parameters in an SEM. When we can, the model is identified. When we cannot, it is underidentified. In multiple regression or ANOVA, the assumptions of the model lead to an exactly identified model, and therefore, this issue is rarely discussed in these contexts. However, when we are dealing with multiequation models with multiple indicators and latent variables, we cannot assume that all model parameters are identified. For instance, suppose that we had two observed variables, y1i and y2i, that had a feedback relationship such that y1i caused y2i and y2i caused y1i. The errors of these two equations are correlated. Having just the means, variances, and covariance of these two variables would be insufficient to identify the coefficients in this feedback relationship. Even with data from the population, we could not find the true coefficient values.
If a parameter in a model is not identified, then there will be two or more values of the parameters that are equally consistent with the data, and the researcher will not be able choose among them empirically, even if population data were available. Hence, knowing the identification status of a model is important to proper estimation and interpretation of a model. In general, the means (μ), variances, and covariances (Σ) of the observed variables are identified parameters for virtually all observed variables that are part of a model. In the most common situation, the identification question is whether the parameters of the model (e.g., factor loadings, regression coefficients, and variances of latent variables) can be written as unique functions of the known to be identified means, variances, or covariances of the observed variables. If yes, then the parameters and model are identified. If no, the model is not identified, even if some equations or individual parameters are identified.
There are rules of identification that apply to some models (15, 16). Empirical techniques for model identification are part of nearly all SEM software. The empirical procedures generally are accurate but not always, because they examine a more limited type of identification (17).
Models that are overidentified (that is, models that have more than enough information to identify all parameters) provide a way to test the overall model structure. However, before we test the model, we need to estimate it.
Estimation.
We review two classes of estimators for SEM. We refer to these as the model-implied moment (MIM) and the model-implied instrumental variable (MIIV) estimators. The MIM estimators are the most common, and therefore, we treat them first.
MIM estimators.
In a previous section, we examined the MIMs, means, variances, and covariances of the observed variables and the fact that these values should equal the corresponding population means, variances, and covariances of the observed variables if the model is valid. The MIM estimators are based on this relationship in that they choose values of the model parameters such that, when they are substituted into the implied moments, they will come as close as possible to reproducing the means, variances, and covariances of the observed variables. These estimators are also called full information estimators. They are full information in that all relationships in the system, including the covariances, variances, and means of exogenous variables and disturbances, play a role in developing the estimates. There are a number of full information estimators, but the dominant full information estimator is the maximum likelihood (ML) estimator. The ML fitting function in SEMs is (Eq. 7)
 |
where S is the sample covariance matrix,  is the vector of the sample means of the observed variables (
is the vector of the sample means of the observed variables ( and
and  stacked in a vector), Pz is the number of observed variables, ln is the natural log, |·| is the determinant, and tr is the trace of a matrix. The ML estimator,
stacked in a vector), Pz is the number of observed variables, ln is the natural log, |·| is the determinant, and tr is the trace of a matrix. The ML estimator,  , is chosen so as to minimize FML. Like all ML estimators,
, is chosen so as to minimize FML. Like all ML estimators, 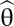 has several desirable properties. It is consistent, asymptotically unbiased, asymptotically efficient, and asymptotically normally distributed, and the asymptotic covariance matrix of
has several desirable properties. It is consistent, asymptotically unbiased, asymptotically efficient, and asymptotically normally distributed, and the asymptotic covariance matrix of 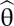 is the inverse of the expected information matrix.
is the inverse of the expected information matrix.
The classic derivation of the ML estimator assumes that all observed variables come from a multinormal distribution. However, a variety of studies have proved that this estimator maintains its properties under less restrictive assumptions. For instance, the ML properties still hold if the observed variables come from a continuous distribution with no excess multivariate kurtosis (18). Robustness studies provide conditions under which the significance tests based on the ML estimator maintain their desirable asymptotic properties even when none of the preceding conditions holds (19). Finally, there are bootstrapping methods (20, 21) and corrected significance tests (22, 23) that enable significance testing even when the robustness conditions fail. Thus, there are numerous options to handle observed endogenous variables that come from nonnormal distributions.
A negative consequence of being a full information estimator such as ML is that, in the likely situation that there are structural misspecifications in the model, there is a great potential for the structural errors in one part of the system to spread their effects elsewhere. This spread can happen even if the other parts of the model are correctly specified. Given the high likelihood of at least some structural error in models, this spread is a drawback of full information MIM estimators. This potential for structural errors or model misspecifications is motivation to use more robust estimators such as the MIIV estimators discussed below.
MIIV estimators.
The MIIVs come in a couple of different forms. Here, we concentrate on the MIIV two-stage least squares (MIIV-2SLS) estimator from Bollen (24, 25).
The main requirement of this MIIV-2SLS estimator is that each latent variable have a scaling indicator such that (Eqs. 8 and 9)
where y1i contains the scaling indicators of ηi and x1i contains the scaling indicators of ξi. These equations imply that ηi = y1i − ε1i and ξi = x1i − δ1i, and by substituting the right-hand sides of these equations, we can eliminate the latent variables from Eqs. 1–3, resulting in Eqs. 10–12:
This simple substitution transforms a system of latent and observed variables into a system of observed variables and a more complex error structure. The end result is a system of equations that consists of observed variables and composite disturbance terms. Generally, most of the equations in this model cannot be consistently estimated with ordinary least squares regression, because one or more of the variables in the composite disturbances correlate with the right-hand side variables. An instrumental variable (IV) approach is used to take account of this problem.
We illustrate an IV using a simple regression equation, y1i = α1 + β11x1i + ε1i, where COV(x1i, ε1i) ≠ 0. The ordinary least squares (OLS) estimator of this equation would result in an inconsistent and biased estimator of β11. However, if there were another variable (x2i) that had a moderate to strong correlation with x1i but no correlation with ε1i, then we could regress x1i on x2i and form the predicted value of 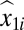 . The OLS regression of y1i on
. The OLS regression of y1i on 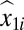 would provide a consistent estimator of β11. The resulting estimator would be the IV estimator where x2i is the IV.
would provide a consistent estimator of β11. The resulting estimator would be the IV estimator where x2i is the IV.
In the general latent variable SEM, the researcher chooses the first equation to estimate from the transformed system that eliminates the latent variables (Eqs. 10–12). The researcher then chooses the MIIV for this equation. The MIIVs are observed variables that are part of the model and based on the model structure, should not correlate with the disturbance of the equation but do have a significant association with the problematic explanatory variable(s). The MIIV selection contrasts with the more typical applications of IV, where the selection of IVs is somewhat ad hoc. In the MIIV-2SLS latent variable approach in the work by Bollen (24), the model comes first, and the observed variables that satisfy the conditions of IVs follow from the model structure. Bollen and Bauer (26) describe an algorithm that finds the MIIVs for a specific model structure, or the researcher can determine the MIIVs by inspection of the model. After the MIIVs are determined for an equation, a 2SLS estimator is applied. The estimator is consistent, asymptotically unbiased, and asymptotically normally distributed, and an estimate of the asymptotic covariance matrix of the coefficients is readily available. As stated above, this estimator seems more robust to misspecified structures than the MIM estimators and could prove helpful when structural misspecification is likely. The works by Bollen (24, 25) have the formula and more technical details.
Both the MIM and MIIV estimators are justified based on their asymptotic properties. Asymptotic refers to large sample properties. It is impossible to give a single sample size N at which these properties take hold, because they depend on many things, such as the complexity of the model and the strength of relationships. However, most SEM researchers would consider an N less than 100 small for all but simple models and an N of 1,000 as sufficiently large for most models. However, even here, there can be exceptions depending on the estimator, distribution of variables, number of parameters, and strength of relationships.
Model fit.
After estimation, the researcher turns to assessing the fit of the model. It is convenient to describe model fit as having two aspects. One concerns the component fit of the model. Overall model fit is the second aspect of fit. In evaluating the component fit of the model, the MIM and MIIV estimators are similar in that both produce asymptotic SEs of the coefficients and intercepts so that the researcher can test individual parameters for statistical significance. In addition, groups of parameters can be tested using, for example, Wald tests. The MIIV-2SLS estimator also has a test of individual equations for all equations that are overidentified in that they have more than the minimum number of MIIVs needed for identification. The Sargan test (27) is a good test to use for this purpose. Its null hypothesis is that all MIIVs are valid in that they are uncorrelated with the disturbance of the equation. The alternative hypothesis is that at least one MIIV is correlated with the disturbance, signifying a problem with the model structure.
Overall fit is a second way to gauge model fit. When using ML and other full information estimators, a χ2 test of overall fit is generally available. For instance, for the ML estimator, the test statistic, TML, is (N − 1)FML, where FML is evaluated at the final estimates 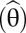 of the parameters. When the assumptions of the ML estimator are satisfied, TML follows an asymptotic χ2 distribution with degrees of freedom of
of the parameters. When the assumptions of the ML estimator are satisfied, TML follows an asymptotic χ2 distribution with degrees of freedom of 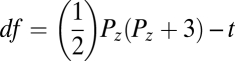 , where Pz is the number of observed variables and t is the number of free parameters estimated in the model. The null hypothesis of this χ2 test is Ho: μ = μ(θ) and Σ = Σ(θ). A statistically significant test statistic casts doubt on the implied moment structure and the model that gave rise to it. A nonsignificant test statistic is consistent with the model structure. One aspect of overall fit to be mindful of is the existence of equivalent models. These equivalent models are models that have different structures but the same overall model fit (28). For instance, a factor analysis model that has four indicators depending on a single latent variable with uncorrelated errors has the same overall fit as the exact same model, except that the first indicator causes rather than depends on the latent variable. Subject matter expertise must be relied on to discriminate between such models, because their χ2 fit and degrees of freedom are the same.
, where Pz is the number of observed variables and t is the number of free parameters estimated in the model. The null hypothesis of this χ2 test is Ho: μ = μ(θ) and Σ = Σ(θ). A statistically significant test statistic casts doubt on the implied moment structure and the model that gave rise to it. A nonsignificant test statistic is consistent with the model structure. One aspect of overall fit to be mindful of is the existence of equivalent models. These equivalent models are models that have different structures but the same overall model fit (28). For instance, a factor analysis model that has four indicators depending on a single latent variable with uncorrelated errors has the same overall fit as the exact same model, except that the first indicator causes rather than depends on the latent variable. Subject matter expertise must be relied on to discriminate between such models, because their χ2 fit and degrees of freedom are the same.
In practice, Ho: μ = μ(θ) and Σ = Σ(θ) is too strict for most models, because the test is intolerant of even slight misspecifications, and hence, in situations with sufficient statistical power (e.g., when N is large), the null hypothesis is nearly always rejected. This finding has given rise to a wide variety of fit indices that supplement the χ2 test and to controversy about the best ways to assess overall fit. Works by Bollen and Long (29) and Hu and Bentler (30) have rationales, formulas, and discussions of these additional fit indices. Current practice is to report the χ2 test statistic, degrees of freedom, and P value along with several other fit indices when assessing a model's overall fit. Alternative methods for model evaluation are available as well (31). If the overall fit or component fit of a model is judged to be inadequate, then this finding suggests the need to respecify the model.
Respecification.
It is common that researchers’ first specified model is found wanting and in need of modification. Respecifications refer to revisions of an initial model. These revisions can range from minor (e.g., introducing a secondary path) to major (e.g., changing number of latent variables and their relationships). Subject matter expertise is the best guide to respecifications. A researcher who had considered alternative structures before choosing the tested one could turn again to these structures to see if fit improves.
Empirical procedures also exist to suggest respecifications of the initial model. For the MIM estimators, the Lagrangian Multiplier (modification indexes) test statistic is the most popular empirical guide. It is an estimate of the decrease in the χ2 test statistic that would result by freeing a previously fixed parameter in the model. It considers freeing just a single parameter at a time, which can be misleading when multiple modifications are required. Reliance on the modification index can lead to the introduction of nonsense parameters and difficulty in recovering the true generating model (32, 33). The modification index is most useful if used in conjunction with substantive expertise. Other diagnostic tools include covariance residual analysis (34) and individual case diagnostics (35, 36). There also are recent developments in exploratory SEM that might prove useful (37). The MIIV-2SLS test of IVs for an equation is another alternative (38).
Empirically based respecifications move the analysis more in the direction of exploratory than confirmatory analysis. The significance tests from such an approach must be interpreted cautiously, because they do not consider that modifications were made in response to patterns found in a specific sample and might not replicate in a new sample from the same population. When possible, replication of the models on fresh data provides some protection against capitalizing on a specific sample. Another desirable strategy is to start the analysis with several plausible models for the same data and compare their fit in a more confirmatory manner. This method contrasts with starting with a single model and modifying it several times in response to its empirical fit. We also note that a researcher approaching modeling from a purely confirmatory perspective would not necessarily respecify a model. The researcher might be more interested in determining whether the model fits or not and regardless of the outcome, would not attempt to modify the original model; the researcher would just report the results of the initial specification.
Illustrations
In this section, we provide several hypothetical examples of SEMs as a way of illustrating the types of structures that are part of this model.
Illustration 1.
The first illustration is a confirmatory factor analysis (CFA), a special case of an SEM that only includes the relationship between a latent variable (or factor) and its measures. This example is taken from Friedman et al. (39); it concerns childhood sleeping patterns and executive functioning at late adolescence and includes three latent variables, each representing a different executive function: inhibiting, updating, and shifting. Each of these executive functioning latent variables is measured by three manifest variables derived from performances on tasks designed to tap into the concepts represented by the latent variables. Using any one of these measures as a covariate in a regression would lead to bias because of the measurement error in each indicator. The benefit of using a latent variable for each of these three executive functioning skills over a single measure is that the degree of measurement error can be estimated and controlled in the model.
The first model is a measurement model. Measurement models can inform the researcher about the degree of measurement error in each indicator and whether all of the indicators behave as hypothesized in relation to the latent variable. Furthermore, the measurement model permits us to determine the closeness of association of different latent variables after we take account of measurement error and see whether the latent variables are empirically separable from each other. Here, we have three correlated latent variables representing different aspects of executive functioning, each with a latent variable measured with three indicators. The latent variables from this measurement model will appear as endogenous (dependent) variables in Illustration 2.
The latent variable for the executive function, inhibiting, represents the concept of individual restraint while holding back a dominant response, and it is measured here by the three variables: antisac, stop-signal, and stroop. The updating executive function latent variable represents the process of discarding less relevant information as an individual acquires more relevant information. Its three measures are keep track, letter, and S2back. Finally, the executive function of shifting is the transitioning from one task to another efficiently and is measured by the variables number, color, and category.
Either equations or path diagrams can represent the relationship between the measures and latent variables. For instance, the equations for the three indicators of inhibiting are (Eqs. 13–15)
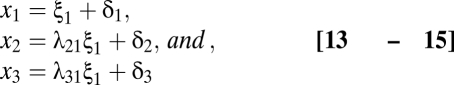 |
where ξ1 is the latent variable for inhibiting and λ21 and λ31 are the coefficients (factor loadings) that give the expected difference in x2 and x3, respectively, for a one-unit difference in ξ1. The coefficient of the x1 is implicitly set to one to provide a metric for the latent variable ξ1. An alternative way to scale the latent variable is to set its variance to one rather than a factor loading. The equations for the measures of updating and shifting are similar but include their respective indicators and latent variables.
Fig. 1 is an alternative way to represent the CFA model—with a path diagram that is equivalent to the equations. The path diagram consists of three latent variables and nine observed variables. The three unobserved or latent variables mentioned above, inhibiting, updating, and shifting, are represented by ovals. Curved, double-headed arrows between each pair of these latent variables allow for covariances between the latent variables in recognition of their likely association with each other.
Fig. 1.

Confirmatory factor analysis of inhibiting, updating, and shifting behaviors.
The indicators, also called observed or manifest variables, are represented in the diagram by the nine boxes and include, for example, antisac, stop-signal, and stroop for the first latent variable of inhibiting. The single-headed straight arrows that originate with the latent variables and terminate in the indicators represent direct relationships from the latent to the observed variables. The small arrow at the bottom of these boxes, whose origin is not pictured, symbolizes the error's effect on the indicator. The error or disturbance includes all other variables that influence the indicator besides its respective latent variable. Each observed variable has a single error term. In the factor analysis tradition, this error term has two parts, with the first part being purely random error and the second part being the specific component. The specific component is a systematic variable that is specific to the particular measure. For simplification, we ignore this distinction and use the term error or disturbance to refer to this variable. Furthermore, the lack of any double-headed curved arrows between these errors identifies that observed variables have no additional covariation beyond that caused by their shared latent variable.
The path diagram in Fig. 1 represents pictorially the relationship between the three latent variables of executive function. We see from the diagram that three latent variables are allowed to covary, each latent variable has effects on only its three indicators and none of the errors from these observed variables covaries with other errors. Of course, more elaborate models are possible where dictated by substantive hypotheses.
Illustration 2.
Illustration 2 is an extension of Fig. 1 by including this model with additional variables in a longitudinal application of the SEM framework known as a latent curve model (LCM). This model will test the hypothesis that a child's sleep problems from ages 4 to 16 y will be useful in predicting his/her executive functioning at age 17 y. The purpose of the LCM is to determine an individual trajectory of sleep problems for each child based on the reported number of sleep problems at 11 different time points in the development of a child. These 11 repeated measures of sleep problems serve as a window into the sleep problem trajectory of a child between the ages of 4 and 16 y. Ultimately, the parameters governing each individual child's sleep trajectory are then used as a predictor of the executive functioning of that individual child at age 17 y. In practice, two unique parameters, the intercept and slope for each child, are used to predict their executive functioning at age 17 y. These two correlated parameters are called growth parameters, and the intercept for the sleep problem trajectory is at age 4 y.
The path diagram in Fig. 2 shows the three latent variables (inhibiting, updating, and shifting) from Fig. 1 in the lower part of the diagram. The upper part of Fig. 2 includes 11 repeated measures of sleep problems at different ages (4–16 y) of children. Each child can have a different starting point or intercept, and this variable is captured by the random intercept latent variable labeled intercept. Each child also can have a different random rate of change in sleep problems, and the random slopes are represented by the latent slope variable. Together, the intercepts and slopes represent the growth curves of sleep problems for the children in the sample. The model in Fig. 2 shows the intercept and slopes with direct effects on the three executive functioning latent variables of inhibiting, updating, and shifting. The errors of these latter three latent variables are allowed to correlate, which is represented by the curved double-headed arrows that connect them. The random intercepts and random slopes also are allowed to correlate, which is represented by the curved double-headed arrow that connects them.
Fig. 2.

Latent curve model of childhood sleep problems on inhibiting, updating, and shifting behaviors at adolescence.
This model illustrates an SEM approach to growth curve models, where the parameters of the growth curves have effects on other outcome variables (40). To avoid overcrowding the diagram, the Greek letters representing the latent variables and coefficients are not shown. However, the ovals and boxes clearly show which variables are latent and observed. Associated with each path is a single-headed arrow from one variable to another. The coefficients give the expected impact of the variable at the base of the arrow on the variable at the head of the arrow while holding constant any other variables affecting that target variable.
There are several benefits of using an LCM to predict executive functioning of children at age 17 y. It allows each child to have a unique trajectory of sleep problems described by their growth parameters. Researchers can test the functional form of the growth trajectory of sleep problems to find the best representation of the growth trajectory of sleep disruptions. Sometimes, nonlinear growth trajectories are better representations of the underlying growth trajectory, and researchers can fit these as well. This method also allows for the usual overall fit indices from the SEM framework to be incorporated in addition to individual component fit measures to assess how well this model fits the data. Furthermore, it allows for estimation of the effect that the trajectory of sleep problems has on the three executive functioning tasks at age 17 y while controlling for the measurement error in inhibiting, updating, and shifting. This model also allows for an assessment of the correlation of the disturbances of inhibiting, updating, and shifting after their prediction by the sleep problem trajectory parameters.
Illustration 3.
The third illustration of SEMs originates in the literature on the relationship of sleep and pain (Fig. 3). The first series of day 1–8 latent variables is the amount of sleep for each person over 8 d. The latent sleep variable that influences all 8 d represents the stable component of sleep across the 8 d.
Fig. 3.

Structural equation model of repeated measures of sleep and pain over 8 d.
Similarly, the second series of day 1–8 latent variables is the daily reports of pain. The latent pain variable that influences all of the daily pain reports is a stable component of the pain reports. The higher-order latent sleep (η1) and latent pain (η10) variables are allowed to correlate. The daily sleep and pain latent variables have an autoregressive relation and some cross-lagged effects from sleep to pain and pain to sleep with a 1-d lag. Prior values often influence current values of the same variable, and this type of autoregressive relationship is included (e.g., sleep on day 2 is regressed on sleep from day 1, sleep from day 3 is regressed on the sleep from day 2, etc.). A pure cross-lagged effect involves two variables and is when a previous measure of one variable predicts a subsequent measure of the other variable. Not shown in the diagram are the measures of the sleep and pain daily latent variables.
This illustration is an adaptation of the SEM from the work by Edwards et al. (41). Notice that this model permits stable individual differences in the latent sleep and pain variables that hold across the days, but it also allows each day's sleep to depend on the prior day's sleep and pain and vice versa. The model hypothesizes that the number of hours that an individual sleeps in one night predicts the daily reports of pain the following day. This model also hypothesizes that both the previous night's sleep and the daily reports of pain during the day are predictors of the amount of sleep that the individual will have that night. Furthermore, this model hypothesizes that the pain reports of a previous day help to predict the pain reports of the current day. This model is a step to trying to untangle the finding that pain and sleep seem to have a nonrecursive relationship (41). To illustrate this model in equation form, consider the equation for the latent sleep variable for day 2 (η3) (Eq. 16),
or the equation for the day 5 pain variable (η15) (Eq. 17),
In a similar fashion, all of the equations could be read from the path diagram.
The whole model could be estimated simultaneously to answer a number of questions about the sleep–pain relationship. Are there individual differences in the overtime levels of pain or sleep? What are the relative strengths of the autoregressive relations among the daily sleep and daily pain variables after controlling for individual differences in sleep and pain higher-order latent variables? Are the lagged effects from sleep to pain and pain to sleep both significant? These questions and others would be addressed while controlling for the other variables in the model and taking account of measurement error.
Conclusions.
Among the many challenges facing studies that quantify behavior are the measurement errors in the behavioral and other measures, the need to formulate multiple equations to characterize the behavioral system, and the desire to understand the direct and indirect effects of variables as they work their way through the equation system. Latent variable SEMs provide the tools to address these challenges. They have the capability to allow quantification and testing of the hypothesized relationships among latent and observed variables. They provide tests of the consistency and plausibility of the assumed model compared with the observed data. Additionally, they enable a researcher to analyze direct as well as mediated relationships. Although SEMs cannot replace sound substantive knowledge in formulating a model, they can provide information on the match between the model and the data, and they do provide tools to further trace the implications of this structure.
Footnotes
The authors declare no conflict of interest.
This paper results from the Arthur M. Sackler Colloquium of the National Academy of Sciences, “Quantification of Behavior,” held June 11–13, 2010, at the AAAS Building in Washington, DC. The complete program and audio files of most presentations are available on the NAS Web site at www.nasonline.org/quantification.
This article is a PNAS Direct Submission.
References
- 1.Wright S. The method of path coefficients. Ann Math Stat. 1934;5:161–215. [Google Scholar]
- 2.Wright S. On the nature of size factors. Genetics. 1918;3:367–374. doi: 10.1093/genetics/3.4.367. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Blalock HM. Causal Inferences in Nonexperimental Research. Chapel Hill, NC: University of North Carolina Press; 1964. [Google Scholar]
- 4.Duncan OD. Path analysis: Sociological examples. Am J Sociol. 1966;72:1–16. [Google Scholar]
- 5.Jöreskog KG. A general method for estimating a linear structural equation system. In: Goldberger AS, Duncan OD, editors. Structural Equation Models in the Social Sciences. New York: Seminar Press; 1973. pp. 85–112. [Google Scholar]
- 6.Bollen KA. Structural equation models. In: Armitage P, Colton T, editors. Encyclopedia of Biostatistics. New York: Wiley; 1998. pp. 4363–4372. [Google Scholar]
- 7.Matsueda RL. Key advances in the history of structural equation modeling. In: Hoyle R, editor. Handbook of Structural Equation Modeling. New York: Guilford; 2012. [Google Scholar]
- 8.Jöreskog KG, Sórbom D. LISREL 8: User's Reference Guide. Uppsala, Sweden: Scientific Software International; 2001. [Google Scholar]
- 9.Muthén LK, Muthén BO. Mplus User's Guide. , 5th Ed. Los Angeles: Muthén and Muthén; 1998. [Google Scholar]
- 10.Arbuckle JL. Amos 18 User's Guide. Crawfordville, FL: Amos Development Corporation; 2009. [Google Scholar]
- 11.Bentler PM. EQS Structural Equations Program Manual. Encino, CA: Multivariate Software; 1995. [Google Scholar]
- 12.Fox J. Structural equation modeling with the SEM package in R. Struct Equ Modeling. 2006;13:465–486. [Google Scholar]
- 13.Bollen KA. Latent variables in psychology and the social sciences. Annu Rev Psychol. 2002;53:605–634. doi: 10.1146/annurev.psych.53.100901.135239. [DOI] [PubMed] [Google Scholar]
- 14.Muthén B. A general structural equation model with dichotomous, ordered categorical, and continuous latent variable indicators. Psychometrika. 1984;49:115–132. [Google Scholar]
- 15.Bollen KA. Structural Equations with Latent Variables. New York: Wiley; 1989. [Google Scholar]
- 16.Davis WR. The FC1 rule of identification for confirmatory factor analysis: A general sufficient condition. Sociol Methods Res. 1993;21:403–437. [Google Scholar]
- 17.Bollen KA, Bauldry S. Model identification and computer algebra. Sociol Methods Res. 2010;39:127–156. doi: 10.1177/0049124110366238. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Browne MW. Asymptotically distribution-free methods for the analysis of covariance structures. Br J Math Stat Psychol. 1984;37:62–83. doi: 10.1111/j.2044-8317.1984.tb00789.x. [DOI] [PubMed] [Google Scholar]
- 19.Satorra A. Robustness issues in structural equation modeling: A review of recent developments. Qual Quant. 1990;24:367–386. [Google Scholar]
- 20.Bollen KA, Stine RA. Direct and indirect effects: Classical and bootstrap estimates of variability. Sociol Methodol. 1990;20:115–140. [Google Scholar]
- 21.Bollen KA, Stine RA. Bootstrapping goodness-of-fit measures in structural equation models. Sociol Methods Res. 1992;21:205–229. [Google Scholar]
- 22.Arminger G, Schoenberg R. Pseudo maximum likelihood estimation and a test for misspecification in mean and covariance structure models. Psychometrika. 1989;54:409–425. [Google Scholar]
- 23.Satorra A, Bentler PM. Corrections to test statistics and standard errors in covariance structure analysis. In: von Eye A, Clogg CC, editors. Latent Variables Analysis: Applications for Developmental Research. Newbury Park, CA: Sage; 1994. pp. 399–419. [Google Scholar]
- 24.Bollen KA. An alternative 2SLS estimator for latent variable models. Psychometrika. 1996;61:109–121. [Google Scholar]
- 25.Bollen KA. Two-stage least squares and latent variable models: Simultaneous estimation and robustness to misspecifications. In: Cudeck R, Du Toit S, Sörbum D, editors. Structural Equation Modeling: Present and Future, A Festschrift in Honor of Karl Jöreskog. Lincoln, IL: Scientific Software; 2001. pp. 119–138. [Google Scholar]
- 26.Bollen KA, Bauer DJ. Automating the selection of model-implied instrumental variables. Sociol Methods Res. 2004;32:425–452. [Google Scholar]
- 27.Sargan JD. The estimation of economic relationships using instrumental variables. Econometrica. 1958;26:393–415. [Google Scholar]
- 28.Hershberger SL. The problem of equivalent structural models. In: Hancock GR, Mueller RO, editors. Structural Equation Modeling: A Second Course. Greenwich, CT.: IAP; 2006. pp. 13–41. [Google Scholar]
- 29.Bollen KA, Long JS, editors. Testing Structural Equation Models. Newbury Park, CA: Sage; 1993. [Google Scholar]
- 30.Hu L, Bentler PM. Fit indices in covariance structure modeling: Sensitivity to underparameterized model misspecification. Psychol Methods. 1998;3:424–453. [Google Scholar]
- 31.Saris WE, Satorra A, van der Veld WM. Testing structural equation models or detections of misspecifications? Struct Equ Modeling. 2009;16:561–582. [Google Scholar]
- 32.MacCallum LC. Specification searches in covariance structure modeling. Psychol Bull. 1986;100:107–120. [Google Scholar]
- 33.MacCallum RC. Working with imperfect models. Multivariate Behav Res. 2003;38:113–139. doi: 10.1207/S15327906MBR3801_5. [DOI] [PubMed] [Google Scholar]
- 34.Costner HL, Schoenberg R. Diagnosing indicator ills in multiple indicator models. In: Goldberger AS, Duncan OD, editors. Structural Equation Models in the Social Sciences. New York: Seminar Press; 1973. pp. 167–200. [Google Scholar]
- 35.Bollen KA, Arminger G. Observational residuals in factor analysis and structural equation models. Sociol Methodol. 1991;21:235–262. [Google Scholar]
- 36.Cadigan NG. Local influence in structural equations models. Struct Equ Modeling. 1995;2:13–30. [Google Scholar]
- 37.Marsh HW, et al. Exploratory structural equation modeling, integrating CFA and EFA: Application to students’ evaluations of university teaching. Struct Equ Modeling. 2009;16:439–476. [Google Scholar]
- 38.Kirby JB, Bollen KA. Using instrumental variable (IV) tests to evaluate model specification in latent variable structural equation models. Sociol Methodol. 2009;39:327–355. doi: 10.1111/j.1467-9531.2009.01217.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Friedman NP, Corley RP, Hewitt JK, Wright KP., Jr Individual differences in childhood sleep problems predict later cognitive executive control. Sleep. 2009;32:323–333. doi: 10.1093/sleep/32.3.323. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Bollen KA, Curran PJ. Latent Curve Models: A Structural Equation Perspective. Wiley Series in Probability and Mathematical Statistics. New York: Wiley; 2004. [Google Scholar]
- 41.Edwards RR, Almeida DM, Klick B, Haythornthwaite JA, Smith MT. Duration of sleep contributes to next-day pain report in the general population. Pain. 2008;137:202–207. doi: 10.1016/j.pain.2008.01.025. [DOI] [PMC free article] [PubMed] [Google Scholar]