
Figure 2. SAILnet activity can be linearly decoded to approximately recover the input stimulus.

(A) An example of an image that was whitened using the filter of Olshausen and Field [17], which is the same filter used to process the images in the training set. The image in panel (A) was not included in the training set. (B) A reconstruction of the whitened image in (A), by linear decoding of the firing rates of SAILnet neurons, which were trained on a different set of natural images. The input image was divided into non-overlapping 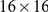 pixel patches, each of which was preprocessed so as to have zero-mean and unit variance of the pixel values (like the training set). Each patch was presented to SAILnet, and the number of spikes were recorded from each unit in response to each patch. A linear decoding of SAILnet activity for each patch
pixel patches, each of which was preprocessed so as to have zero-mean and unit variance of the pixel values (like the training set). Each patch was presented to SAILnet, and the number of spikes were recorded from each unit in response to each patch. A linear decoding of SAILnet activity for each patch 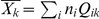 was formed by multiplying each unit's activity by that unit's RF and summing over all neurons. The preprocessing was then inverted, and the patches were tiled together to form the image in panel (B). The decoded image resembles the original, but is not identical, owing to the severe compression ratio; on average, each
was formed by multiplying each unit's activity by that unit's RF and summing over all neurons. The preprocessing was then inverted, and the patches were tiled together to form the image in panel (B). The decoded image resembles the original, but is not identical, owing to the severe compression ratio; on average, each 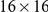 input patch, which is defined by 256 continuous-valued parameters, is represented by only 75 binary spikes of activity, emitted by a small subset of the neural population. Linear decodability is a product of our learning rules, and it is an observed feature of multiple sensory systems [42] and spiking neuron models optimized to maximize information transmission [8], [12].
input patch, which is defined by 256 continuous-valued parameters, is represented by only 75 binary spikes of activity, emitted by a small subset of the neural population. Linear decodability is a product of our learning rules, and it is an observed feature of multiple sensory systems [42] and spiking neuron models optimized to maximize information transmission [8], [12].