
Figure 1.
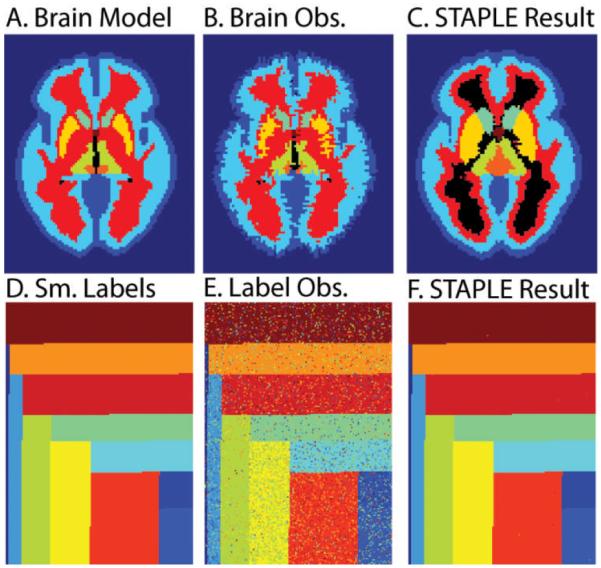
Characteristic STAPLE failure and success. For truth label models (one slice shown in A&D), fusion of multiple sets of reasonable quality random observations (such as in B&E) can lead to decreased performance (such as in C) as seen through the dramatic label inversion problem. A collection of 50 raters of quality similar to the observation seen in (B) were used to generate the estimate seen in (C). This catastrophic segmentation error occurred between 10% and 20% of the time the simulation was run. However, this behavior is not ever present, even for models with small regions (as illustrated in the label fusion in F). Note B&E were observed with the same rater reliabilities and C&F were each fused with three observations per voxel.