

Abstract
The cryo-electron microscopy (cryo-EM) reconstruction problem is to find the three-dimensional structure of a macromolecule given noisy versions of its two-dimensional projection images at unknown random directions. We introduce a new algorithm for identifying noisy cryo-EM images of nearby viewing angles. This identification is an important first step in three-dimensional structure determination of macromolecules from cryo-EM, because once identified, these images can be rotationally aligned and averaged to produce “class averages” of better quality. The main advantage of our algorithm is its extreme robustness to noise. The algorithm is also very efficient in terms of running time and memory requirements, because it is based on the computation of the top few eigenvectors of a specially designed sparse Hermitian matrix. These advantages are demonstrated in numerous numerical experiments.
Keywords: cryo-electron microscopy, class averaging, random matrices, semicircle law, angular synchronization, hairy ball theorem, parallel transport, tomography
1. Introduction
In this paper we address the class averaging problem in cryo-electron microscopy (cryo-EM) [10]. The goal in cryo-EM is to determine three-dimensional (3D) macromolecular structures from noisy projection images taken by an electron microscope at unknown random orientations, i.e., a random computational tomography (CT). Determining 3D macromolecular structures for large biological molecules remains vitally important, as witnessed, for example, by the 2003 Nobel Prize in Chemistry, co-awarded to MacKinnon for resolving the 3D structure of the Shaker K+ channel protein [8, 17], and by the 2009 Nobel Prize in Chemistry, awarded to Ramakrishnan, Steitz, and Yonath for studies of the structure and function of the ribosome. The standard procedure for structure determination of large molecules is X-ray crystallography. The challenge in this method is often more in the crystallization itself than in the interpretation of the X-ray results, since many large proteins have so far withstood all attempts to crystallize them.
In cryo-EM, an alternative to X-ray crystallography, the sample of macromolecules is rapidly frozen in an ice layer so thin that their tomographic projections are typically disjoint; this seems the most promising alternative for molecules that defy crystallization. The cryo-EM imaging process produces a large collection of tomographic projections of the same molecule, corresponding to different and unknown projection orientations. The goal is to reconstruct the 3D structure of the molecule from such unlabeled projection images, where data sets typically range from 104 to 105 projection images whose size is roughly 100 × 100 pixels. The intensity of the pixels in a given projection image is proportional to the line integrals of the electric potential induced by the molecule along the path of the imaging electrons (see Figure 1). The highly intense electron beam destroys the frozen molecule, and it is therefore impractical to image the same molecule at known different directions as in the case of classical CT. In other words, a single molecule can be imaged only once, rendering an extremely low signal-to-noise ratio (SNR) for the images (see Figure 2 for a sample of real microscope images), mostly due to shot noise induced by the maximal allowed electron dose (other sources of noise include the varying thickness of the ice layer and partial knowledge of the contrast transfer function of the microscope). In the basic homogeneity setting considered hereafter, all imaged molecules are assumed to have the exact same structure; they differ only by their spatial rotation. Every image is a projection of the same molecule from an unknown random direction, and the cryo-EM problem is to find the 3D structure of the molecule from a collection of noisy projection images.
Figure 1.

Schematic drawing of the imaging process: Every projection image corresponds to some unknown 3D rotation of the unknown molecule.
Figure 2.

A collection of four real electron microscope images of the E. coli 50S ribosomal subunit.
The rotation group SO(3) is the group of all orientation preserving orthogonal transformations about the origin of the 3D Euclidean space under the operation of composition. Any 3D rotation can be expressed using a 3 × 3 orthogonal matrix R:
satisfying
where I is the 3×3 identity matrix. The column vectors R1, R2, R3 of R form an orthonormal basis to .
To each projection image P there corresponds a 3×3 unknown rotation matrix R describing its orientation (see Figure 1). Excluding the contribution of noise, the intensity P(x, y) of the pixel located at (x, y) in the image plane corresponds to the line integral of the electric potential induced by the molecule along the path of the imaging electrons; that is,
| (1.1) |
where is the electric potential of the molecule in some fixed “laboratory” coordinate system. The projection operator (1.1) is also known as the X-ray transform [19].
We therefore identify the third column R3 of R as the imaging direction, also known as the viewing angle of the molecule. We will often refer to the viewing angle of R as v; that is, is given by v = v(R) = R3. The viewing angle v can be realized as a point on S2 (the unit sphere in ) and can therefore be described using two parameters.
The first two columns R1 and R2 form an orthonormal basis for the plane in perpendicular to the viewing angle v. All clean projection images of the molecule that share the same viewing angle v look the same up to some in-plane rotation. That is, if Ri and Rj are two rotations with the same viewing angle v(Ri) = v(Rj), then , and , are two orthonormal bases for the same plane and the rotation matrix has the form
| (1.2) |
where θij ∈ [0, 2π) is the angle in which we have to in-plane rotate image j in the counterclockwise direction in order for it to be aligned with image i. On the other hand, two rotations with opposite viewing angles v(Ri) = −v(Rj) give rise to two projection images that are the same after reflection (mirroring) and some in-plane rotation.
As projection images in cryo-EM have extremely low SNRs, a crucial initial step in all reconstruction methods is “class averaging” [10]. Class averaging is the grouping of a large data set of n noisy raw projection images P1, …, Pn into clusters, such that images within a single cluster have similar viewing angles (it is possible to artificially double the number of projection images by including all mirrored images). Averaging rotationally aligned noisy images within each cluster results in “class averages”; these are images that enjoy a higher SNR and are used in later cryo-EM procedures such as the angular reconstitution procedure [27] that requires better quality images. Finding consistent class averages is challenging due to the high level of noise in the raw images as well as the large size of the image data set. A sketch of the class averaging procedure is shown in Figure 3.
Figure 3.

The class averaging problem is to find, align, and average images with similar viewing angles: (a) a clean simulated projection image of the ribosomal subunit generated from its known density map; (b) noisy instance of (a), denoted Pi, obtained by the addition of white Gaussian noise. For the simulated images we chose the SNR to be higher than that of experimental images in order for image features to be clearly visible; (c) noisy projection, denoted Pj, of the subunit taken at the same viewing angle but with a different in-plane rotation. The in-plane rotation angle is θij = 3π/2, because image Pj needs to be rotated by π/2 in the clockwise direction in order to be aligned with Pi (see also text following (1.3)); (d) averaging the noisy images (b) and (c) after in-plane rotational alignment. The class average of the two images has a higher SNR than that of the noisy images (b) and (c), and it has better similarity to the clean image (a).
Penczek, Zhu, and Frank [20] introduced the rotationally invariant K-means clustering procedure to identify images that have similar viewing angles. Their invariant distance dij between image Pi and image Pj is defined as the Euclidean distance between the images when they are optimally aligned with respect to in-plane rotations (assuming the images are centered):
| (1.3) |
where R(θ) is the rotation operator of an image by an angle θ in the counterclockwise direction. Prior to computing the invariant distances of (1.3), a common practice is to center all images by correlating them with their total average , which is approximately radial (i.e., has little angular variation) due to the randomness in the rotations. The resulting centers usually miss the true centers by only a few pixels (as can be validated in simulations during the refinement procedure). Therefore, as in [20], we also choose to focus first on the more challenging problem of rotational alignment by assuming that the images are properly centered. The problem of translational alignment will be considered elsewhere. Other methods for class averaging are reviewed in [28].
It is worth noting that the specific choice of metric to measure proximity between images can make a big difference in class averaging. The cross-correlation and Euclidean distance (1.3) are by no means optimal measures of proximity. In practice, it is common to denoise the images prior to computing their pairwise distances. A popular smoothing scheme is to convolve the images with a Gaussian kernel, and other linear and nonlinear filters are also used. Although the discussion which follows is independent of the particular choice of filter or distance metric, we stress again that filtering can have a dramatic effect on finding meaningful class averages.
The invariant distance (1.3) is invariant to in-plane rotations and as such it induces a metric on the viewing angle space S2. The invariant distance between noisy images that share the same viewing angle (with perhaps a different in-plane rotation) is expected to be small. Ideally, all neighboring images of some reference image Pi in a small invariant distance ball centered at Pi should have similar viewing angles, and averaging such neighboring images (after proper rotational alignment) would amplify the signal and diminish the noise.
Unfortunately, due to the low SNR, it often happens that two images of completely different viewing angles have a small invariant distance. This can happen when the realizations of the noise in the two images match well for some random in-plane rotational angle, leading to spurious neighbor identification. Therefore, averaging the nearest neighbor images can sometimes yield a poor estimate of the true signal in the reference image.
Clustering algorithms, such as the K-means algorithm, perform much better than this naive nearest neighbor averaging, because they take into account all pairwise distances, not just distances to the reference image. Such clustering procedures are based on the philosophy that images that share a similar viewing angle with the reference image are expected to have a small invariant distance not only to the reference image but also to all other images with similar viewing angles. This observation was utilized in the rotationally invariant K-means clustering algorithm [20]. Such clustering algorithms make it harder for spurious neighbors to sneak their way into the neighborhood. Still, noise is our enemy, and the rotationally invariant K-means clustering algorithm may suffer from misidentifications at the low SNR values present in experimental data.
Is it possible to further improve the detection of neighboring images at even lower SNR values? In this paper we provide a positive answer to this question. First, we note that the rotationally invariant distance neglects an important piece of information, namely, the optimal angle that realizes the best rotational alignment in (1.3). Second, we observe that these optimal rotation angles must satisfy a global system of consistency relations, namely, that if three projection images correspond to similar viewing angles, then the three optimal rotational angles should add up to 0 modulo 2π. Based on these observations, we use the optimal in-plane rotation angles to construct a sparse n × n Hermitian matrix, which we call “the class averaging matrix,” and show how to identify nearby viewing directions from the top three eigenvectors of the matrix.
The main advantage of the algorithm presented here is that it successfully identifies images with nearby viewing directions even in the presence of high levels of noise in the images. For such high levels of noise, it is possible for pairs of images with viewing angles that are far apart to have relatively small rotationally invariant distances. Our algorithm is extremely robust to such outliers, as we demonstrate both theoretically and in various numerical experiments. This robustness to outliers is explained using random matrix theory, similar to the way we showed robustness of our 3D eigenvector reconstruction algorithm from common lines [24]. Another advantage of the algorithm is that it has a low computational complexity as it requires only the computation of the top three eigenvectors of the class averaging matrix, which is a sparse matrix.
In [23] we presented an algorithm for estimating angles from noisy measurements of their offsets modulo 2π using the top eigenvector of a Hermitian matrix constructed in exactly the same way the class averaging matrix is constructed. The reason why three eigenvectors (instead of one) are needed here is due to the special topology of the sphere S2 as rendered in the “hairy ball” theorem that says that a continuous tangent vector field to the sphere must vanish at some point. We also conducted numerical experiments that demonstrate how the identification of nearby viewing directions can be improved by using more than three eigenvectors. Finally, we show that the class averaging matrix is a discretization of a local version of the parallel transport operator on the sphere. This interpretation leads to a complete understanding of the spectrum of the class averaging matrix and to a rigorous proof of the admissibility (correctness) of the algorithm presented in this paper. The complete spectral analysis will be presented in a separate publication [13].
2. Small-world graph on S2, triplets consistency, and angular synchronization
The purpose of this section is to motivate the construction of the class averaging matrix. We provide here the intuition that leads to the construction of the class averaging matrix, whose mathematical meaning will become apparent only in section 4.
As mentioned earlier, the information in the optimal in-plane rotation angles has yet to be utilized in existing class averaging algorithms. We incorporate this additional information as follows. When computing the optimal alignment of images Pi and Pj and their invariant distance dij, we also record the rotation angle θij that brings the distance between the two images to a minimum,
| (2.1) |
Note that
| (2.2) |
as the optimal rotation from Pj to Pi is in the opposite direction as that from Pi to Pj.
We assume that there is a unique optimal in-plane rotation angle θij for which the minimum in (2.1) is attained. Note that this assumption excludes, for example, projection images of symmetric molecules when the viewing direction coincides with the symmetry axis, and perhaps other projection images are also excluded. Note that if Pi and Pj are clean images having the same viewing angle vi = vj, then the optimal in-plane rotation angle θij computed in the optimization procedure (2.1) agrees with the angle θij introduced in (1.2). In that sense, the computed angles θij provide additional information about the unknown rotation matrices R1, …, Rn.
In practice, however, we cannot expect two projection images to have exactly the same viewing angle. Still, we may assume that the molecule is “nice” enough1 such that projection images that correspond to nearby viewing angles would look similar (up to an in-plane rotation). In such cases, it is reasonable to assume that the optimal in-plane rotation angle θij computed in (2.1) provides a good approximation to the angle that “aligns” the orthonormal bases for the planes2 , , given by the vectors , and , , respectively. In other words, for clean images, it is expected that a small distance between vi and vj would imply that θij approximates the angle given by
| (2.3) |
where
| (2.4) |
and ∥·∥F is the Frobenius norm of the matrix (square root of the sum of its squared elements). The reader may verify that satisfies
| (2.5) |
| (2.6) |
in accordance with (1.2) even when vi differs from vj. Thus, computing θij provides indispensable information about the unknown rotations R1, …, Rn.
By making a histogram of all distances dij, one can choose some threshold value ε, such that dij ≤ ε is indicative that perhaps Pi and Pj have nearby viewing angles. The threshold ε defines an undirected graph G = (V, E) with n vertices corresponding to the projection images, with an edge between nodes i and j iff their invariant distance is smaller than ε:
| (2.7) |
Alternatively, an undirected graph may be constructed from the identification of nearest neighbors, such that {i, j} ∈ E iff i is one of the N nearest neighbors of j or j is one of the N nearest neighbors of i, where N ≪ n is a fixed parameter. Yet another possibility is to take the intersection instead of the union; i.e., {i, j} ∈ E iff i is one of the N nearest neighbors of j and j is one the N nearest neighbors of i.
Either way, in an ideal noiseless world, the topology of the graph is that of S2; for each vertex there corresponds a viewing angle, which is a unit vector in three-space realized as a point on the sphere. If all invariant distances were trustworthy such that small distances imply similar viewing angles, then the edges of G would link neighboring points on S2. The drawing of such a graph in 3D space would show scattered points (vertices) on the sphere connected by short chords (edges). The experimental world, however, is far from ideal and is ruled by noise, giving rise to false edges that shortcut the sphere by long chords. Such graphs are known as “small-world” graphs [29], a popular model to describe social network phenomena such as the six degrees of separation: our social network consists of people living in our own town (neighboring edges), but also some other family and friends who live across the world (shortcut edges). Planar drawings of a ring graph and its corresponding small-world graph are given in Figure 4.
Figure 4.
(a) A ring graph with 20 vertices each of which is connected to its six nearest neighbors with short edges; (b) a small-world graph obtained by randomly rewiring the edges of the ring graph with probability 0.2 leading to about 20% of shortcut edges.
Can we tell the good edges (short chords) from the bad edges (long chords)? It is possible to denoise small-world graphs based on the fact that they have many more “triangles” than random graphs: two images Pi and Pj that have nearby viewing angles should have common neighboring images Pk whose viewing angles are close to theirs. All three edges {i, j}, {j, k}, and {k, i} are in E forming a triangle (i, j, k). On the other hand, shortcut edges are not expected to be sides of as many triangles. This “cliquishness” property of small-world graphs was used by Goldberg and Roth [11] to denoise protein-protein interaction maps by thresholding edges that appear in only a few triangles.
In the class averaging problem of cryo-EM, we can further test for the consistency of the triangles. Indeed, if the three images Pi, Pj, and Pk share the same viewing angle, then the three corresponding rotation angles θij, θjk, and θki must satisfy
| (2.8) |
because rotating first from Pi to Pj, followed by a rotation from Pj to Pk, and finally a rotation from Pk to Pi together complete a full circle. Equation (2.8) is a consistency relation that enables us to detect image triplets with similar viewing angles and to identify good triangles. Similarly, we may write consistency relations that involve four or more images.
At first (but incorrect3) inspection, the triplet consistency relation seems to be a byproduct of an underlying angular synchronization problem [23]. If all projection images can be initially rotated such that they are optimally rotationally aligned, then we can let θi be the rotation angle of image Pi that brings it in sync with all other images. The mutual rotation angles θij should satisfy the difference equations
| (2.9) |
from which the consistency relation (2.8) immediately follows:
In [23] we introduced a robust and efficient synchronization algorithm for estimating the angles θ1, …, θn from noisy offset measurements of the form (2.9). The first step of the synchronization algorithm is to construct an n × n Hermitian matrix H as
| (2.10) |
where The matrix H is Hermitian, i.e., , because the offsets are skew-symmetric; i.e., θij = −θji mod 2π. As H is Hermitian, its eigenvalues are real. The second step of the synchronization algorithm is to compute the top eigenvector v1 of H with maximal eigenvalue, and to derive an estimator for the angles in terms of this top eigenvector as
| (2.11) |
The motivation and analysis of this eigenvector-based synchronization algorithm are detailed in [23].
3. Hairy ball theorem
Unfortunately, the top eigenvector of H constructed with the offset angles given in (2.1) does not provide rotation angles that would bring all the projection images in sync. This is due to the fact that such rotation angles simply do not exist! That is, there is no way to rotate all images such that every pair of images with nearby viewing angles would be rotationally aligned. This somewhat surprising fact is a consequence of the topology of S2 and, more specifically, a mathematical theorem known as the hairy ball theorem.
The hairy ball theorem says that a continuous tangent vector field to S2 must vanish at some point on the sphere. In other words, if f is a continuous function that assigns a vector in to every point v on the sphere such that f(v) is always tangent to the sphere at v, then there is at least one v ∈ S2 such that f(v) = 0. The theorem attests to the fact that it is impossible to comb a hairy (spherical) cat without creating a cowlick. For example, consider the tangent vector field f given by
| (3.1) |
The tangent vector field f is continuous but vanishes at the north and south poles ±(0, 0, 1). The normalized tangent vector field
is discontinuous at the poles z = ±1. The hairy ball theorem implies that any attempt to find a nonvanishing continuous tangent vector field to the sphere would ultimately fail. An elementary proof of the theorem can be found in [18].
We now explain the way the hairy ball theorem relates to the rotational alignment problem of the projection images. Each projection image P whose corresponding rotation is R can be viewed as a tangent plane to S2 at the viewing direction v = v(R) = R3. The first two columns of R, namely, R1 and R2, are vectors in that form an orthogonal basis for the tangent plane. Together with the imaging direction v they make an orthogonal basis of . An in-plane rotation of the projection image can thus be viewed as changing the basis vectors R1 and R2 while keeping v fixed. A successful rotational alignment of all projection images means that we can choose orthogonal bases to all tangent planes such that the basis vectors vary smoothly from one tangent plane to the other. However, this is a contradiction to the hairy ball theorem! We conclude that the rotational alignment of all images cannot be considered as an angular synchronization problem, because there does not exist a set of angles θ1, …, θn such that θij = θi − θj, not even approximately. We refer the reader to Appendix B for a discussion about the relevance of the hairy ball theorem in the discrete case of a finite number of images.
4. Parallel transport and spectral properties of the class averaging matrix
We note that (2.8) can hold (approximately) without (2.9). So, instead of getting too pessimistic from the hairy ball theorem, we observe that the matrix H is a well-defined Hermitian matrix, and nothing prevents us from computing its eigenvectors and eigenvalues. In fact, we expect the eigenvectors of H to somehow capture the consistency relation (2.8) and all higher-order consistency constraints that correspond to cycles longer than three. The question is whether or not the eigenvectors of H are meaningful in the sense that they will allow us to identify images with nearby viewing angles, and if so, how?
We show that there is indeed a relatively simple algorithm that successfully identifies images with nearby viewing directions using the top three (or more) eigenvectors of H. The underpinning of the algorithm is the connection between the matrix H and the parallel transport operator on the sphere. To that end, consider the case in which the underlying graph is a neighborhood graph on S2, without any shortcut edges.4 More specifically, we assume that the neighborhood of every vertex corresponds to a small spherical cap with an opening angle α; that is, if v1, v2 ∈ S2 are two different viewing angles, then there is an edge between v1 and v2 iff 〈v1, v2〉 > cos α. We denote the resulting matrix by Hclean to emphasize that there are no shortcut edges, which will be the case if the matrix is constructed from clean projection images that contain no noise.
As mentioned earlier, we may think of a projection image P with corresponding rotation matrix R as living on the tangent plane to the sphere at the viewing angle v = R3. The tangent plane at the point v can be identified with the standard Euclidean plane using the first two columns R1, R2 of R. Let us denote5 this copy of by TR. In addition, we note that TR can be further identified with : any vector is identified with the complex number . This complex structure is the one induced from the orientation defined by the viewing angle v.
Between any two nonantipodal points vi, vj ∈ S2 there is a unique geodesic line (a great circle) that connects them. We can slide any vector tangent to the sphere at vj along this geodesic line in such a way that the sliding vector remains tangent to the sphere until it reaches the point vi, where it becomes a tangent vector to the sphere at vi. During this transportation, we make sure that the angle that the tangent vector makes with the geodesic remains constant. The transportation that takes vectors in TRj to vectors in TRi is a linear transformation denoted by and is known in differential geometry as the parallel transport operator on the sphere [7, Chapter 4] (see Figure 5).
Figure 5.

Illustration of the parallel transport operator on the sphere (taken from http://en.wikipedia.org/wiki/Connection_(mathematics)).
The main observation is that whenever two projection images Pi and Pj have nearby viewing angles vi and vj satisfying 〈vi, vj〉 > cos α, the matrix element is an approximation to the parallel transport operator , viewed as an operator from to . That is, if zj ∈ TRj, then (in Appendix A.5 we give the explicit formula of the parallel transport operator on the sphere and show that it coincides with the rotation implied by the optimization procedure (2.3)).
This implies that the limiting class averaging matrix in the limit of an infinite number of clean images whose viewing angles are independently drawn from the uniform distribution on S2 is a local version of the parallel transport operator on the sphere. The parallel transport operator takes tangent vector fields to the sphere to tangent vector fields on the sphere. The (global) parallel transport operator can be written in terms of the following integral over SO(3):
| (4.1) |
where dU is the uniform (invariant Haar) measure over SO(3), and f is any complex-valued function on SO(3) satisfying f(R) ∈ TR for all R ∈ SO(3). We define the local parallel transport operator by the integral
| (4.2) |
where h = 1 − cos α ∈ [0, 2] and α is the opening angle of the spherical cap. To conclude, we obtain
| (4.3) |
In this regard, the matrix Hclean should be considered as a discretization of . Note that from the experimental data obtained from rotationally aligning the images we are only able to extract (a discretization of) the local parallel transport operator. This is due to the fact that we do not know at this point how to transport vectors between projection images (tangent planes) whose viewing angles are far apart, because the angle θij obtained from the rotational alignment (2.1) of dissimilar images is meaningless in such cases in the sense that it has nothing to do with parallel transportation.
It follows that the spectral properties of the matrix Hclean are governed by the spectral properties of the operator . We now state without proof6 a few results concerning the spectrum of .
The first result states that the multiplicities of the eigenvalues λn(h) of are 3, 5, 7, 9, …, that is, the following:
Note that the multiplicity 1 that appears in the angular synchronization problem disappears from the spectrum of , a fact that may be attributed to the hairy ball theorem. The precise formula for the first four eigenvalues is
These formulas are valid for all values of h ∈ [0, 2]. The graphs of λn(h), for n = 1, 2, 3, 4, are given in Figure 6.
Figure 6.

The eigenvalues λn(h) of the local parallel transport operator for n = 1, 2, 3, 4.
The second result states that the eigenspace of multiplicity 3 (n = 1) corresponds to the largest eigenvalue of . That is, λ1(h) > λn(h) for n ≥ 2 and for all h ∈ [0, 2]. For example, Figure 6 demonstrates that λ1(h) dominates λ2(h), λ3(h), and λ4(h). The spectral gap is evident from Figure 6, which shows that for small values of h the second largest eigenvalue among the first four eigenvalues is λ2(h). In fact, λ2(h) > λn(h) for all h ≤ 1/2 and n ≥ 3 (note that λ2(h) has its maximum at h = 1/2). Hence, the spectral gap Δ(h) is
| (4.4) |
The third result states that if Ri, Rj ∈ SO(3) are two rotations, and ψ1, ψ2, ψ3 form an orthonormal basis for the top eigenspace of of multiplicity 3, that is, ψ1, ψ2, ψ3 are the top three eigenfunctions of satisfying
then
| (4.5) |
where for every rotation R ∈ SO(3) we define the vector as
| (4.6) |
Note that the dot product on the left-hand side of (4.5) is between vectors in , while the dot product and norms on the right-hand side are of vectors in . The result (4.5) means that the top three eigenvectors of allow us to express the dot product between the unknown viewing angles v(Ri) and v(Rj) in terms of the Hermitian dot product between their corresponding unit vectors and in . The third result is of extreme importance as it lies at the heart of our algorithm. In Appendix A we give an elementary proof of this result. That proof requires neither knowledge of representation theory nor familiarity with the tools developed in [12, 13].
5. Algorithm
Taking these three spectral properties into account leads to a simple algorithm for finding images that correspond to similar viewing angles. The input to the algorithm consists of n projection images P1, …, Pn (n is often twice as large as the number of raw images, because for every raw image we artificially add its mirrored image). We now detail the various steps of the algorithm:
Compute the rotationally invariant distances7dij and the optimal alignment angles θij as in (1.3) and (2.1) between all pairs of images.8
Construct the sparse n × n Hermitian matrix H as defined in (2.10), with the edge set E defined in (2.7) or, preferably, by taking the N nearest neighbors of every image (where N ≪ n is a fixed parameter).
Since some vertices may have more edges than others, we define = D−1H, where D is an n × n diagonal matrix with . Notice that is similar to the Hermitian matrix D−½HD−½.
Compute the top three normalized eigenvectors of , denoted . Since is a sparse matrix, its top three eigenvectors are most efficiently computed using an iterative method, such as the MATLAB eigs function.
- Use ψ1, ψ2, ψ3 to define n vectos by
where ψj(i) is the ith entry of the vector ψj (j =1,2,3).(5.1) - Define a measure of affinity Gij between images Pi and Pj as
(5.2) - Declare neighbors of Pi as
where 0 < γ ⪡ 1 controls the size of the neighborhood, or, alternatively, it is also possible to choose some fixed number of the largest Gij values to define neighbors.(5.3)
In section 6 we consider a specific model for which the algorithm is shown to successfully detect the true neighbors, while in section 7 we detail the results of numerous experiments that demonstrate its usefulness in practice. Moreover, in subsection 7.4 we describe a generalization of the algorithm that uses more than three eigenvectors and discuss the reason for which it succeeds even if the viewing directions are not uniformly distributed.
6. Probabilistic model and random matrix theory
We now explain why the algorithm succeeds in identifying the true neighbors. To that end, we will assume a specific probabilistic model for the entries of H. Our simplified model tries to capture and approximate the main features of the matrix H when it is constructed by computing rotationally invariant distances and optimal angles between noisy images.
We start by randomly generating n rotations R1, …, Rn uniformly (according to the Haar measure) on SO(3). Our model assumes that if Pi and Pj are two projection images whose viewing angles both belong to a small spherical cap of size α, then with probability p the rotationally invariant distance dij will be small enough such that there would be an edge between them in the graph (i.e., {i, j} ∈ E) and that the optimal angle θij would be accurate in the sense that it would be given by (2.5)–(2.6). With probability 1 − p the distance dij is not small enough for creating an edge between i and j, and instead there would be a link between i to some random vertex, drawn uniformly at random from the remaining vertices (not already connected to i). We assume that if the link between i and j is a random link (such that the corresponding viewing angles are far away from each other), then the optimal in-plane rotation angle θij is uniformly distributed in [0, 2π). In our model, the only links existing between projection images Pi and Pj whose viewing angles do not belong to a small spherical cap of size α are these shortcut edges obtained by rewiring other good links, and there are no other links between them. In other words, our model assumes that the underlying graph of links between noisy images is a small-world graph on the sphere, with edges being randomly rewired with probability 1 − p. The angles take their correct values for true links and random values for shortcut edges.
The matrix H is a random matrix under this model. Since the expected value of the random variable eıθ vanishes for θ ~ Uniform[0,2π), that is, , we have that the expected value of the matrix H is
| (6.1) |
where Hclean is the class averaging matrix that corresponds to p = 1 obtained in the case that all links and angles are inferred correctly. Here we take full advantage of our construction of H that sets the elements of H to be complex-valued numbers that average to 0 (instead of nonnegative entries like 0 and 1 of the adjacency matrix that cannot have zero mean). We conclude that the matrix H can be decomposed as
| (6.2) |
where R is a random matrix whose elements are independent and identically distributed (i.i.d.) zero mean random variables with finite moments (the elements of R are all bounded). The decomposition (6.2) is extremely useful, as it means that the top eigenvectors of H approximate the top eigenvectors of Hclean as long as the 2-norm of R is not too large. Bounds on the spectral norm of random sparse matrices are proved in [16, 15]. Adapting [16, Theorem 2.1, p. 126] to our case shows that with high probability, since the average degree of the graph is . In the next section we provide the results of numerical experiments from which it seems that the distribution of the eigenvalues of R follows Wigner's semicircle law [30, 31]. Moreover, we note that the spectral norm of Hclean is O(nα2), since converges to the operator (given in (4.2)) whose spectral norm is O(h) = O(α2). Similarly, the spectral gap of Hclean is O(nh2) = O(nα4), since the spectral gap of is O(h2) = O(α4) (see (4.4)). The decomposition (6.2) and the bound on ‖R‖2 imply that the top three eigenvectors of H approximate the top three eigenvectors of Hclean as long as ‖R‖2 is smaller than the spectral gap of pHclean or, equivalently, for p > pc, where is the threshold probability that depends on the size of the cap and the number of images.
As discussed earlier, the matrix converges almost surely to the operator in the limit n → ∞. This convergence rate is at least as fast as due to the law of large numbers. Altogether, it follows that for large enough n, the linear span of the top three eigenvectors of H is a discrete approximate of the top eigenspace of , because the top eigenvectors of H approximate the top eigenvectors of Hclean, but these approximate the top eigenfunctions of . Finally, the spectral properties of (section 4) ensure the success of the algorithm under this probabilistic model.
7. Numerical experiments
We conducted two types of numerical experiments. The first type involves simulations of the probabilistic model of section 6. The second type mimics the experimental setup by applying the algorithm to noisy simulated projection images of a given 3D volume. We point out that there is no direct way to compare the performance of classification algorithms on real microscope images, since their viewing angles are unknown. The only way to compare classification algorithms on real data is indirectly, by evaluating the resulting 3D reconstructions. Here we conduct only numerical experiments from which conclusions can be drawn directly.
All experiments in this section were executed on a Linux machine with eight Xeon 2.93GHz cores and 48GB of RAM. Unless otherwise specified, the executed code was not parallelized and so only one core was active.
7.1. Experiments with the probabilistic model
The purpose of the first experiment of this type is to illustrate the emergence of Wigner's semicircle law and the performance of the algorithm for n = 1000, cos α = 0.7 (α = 45.6°, and different values of p. We chose this relatively small value for n (n = 1000), because showing the semicircle requires the computation of all eigenvalues of H, not just the few top ones that are required by the algorithm. Also, the value of α = 45.6° is too large to be considered realistic, as it implies that projection images whose viewing angles differ by as much as 45° are similar enough to have a small rotationally invariant distance. We chose this high value of α so that the underlying graph would have enough edges and the spectral gap would be noticeable. The number of graph edges in this experiment is m ≈ 37,500. We emphasize once again that the purpose of this experiment is of an illustrational nature.
Figure 7 summarizes the results of the first experiment. Evident from the histogram of the eigenvalues of H (left column) is the emergence of the semicircle that gets slightly wider as p decreases (the right edges of the semicircles never exceed 25). The multiplicities 3, 5, 7, … of the top eigenvalues are clearly demonstrated in the bar plots of the eigenvalues (middle column). The top three eigenvalues of H are separated from the semicircle as long as p is not too small. Note that the decrease of these three eigenvalues as p is decreased stands in full agreement with (6.2), which shows that they scale linearly with p as they correspond to the eigenvectors of Hclean. The right column shows scatter plots of the Gij values that were estimated from the algorithm (y-axis) against the dot products 〈vi, vj〉 of the simulated (true) rotations R1, …, Rn with vi = Ri3, i = 1, …, n. Figure 7(c) shows that the dot products between the normalized unit vectors in that are computed from the top three eigenvectors of H are equal (up to numerical errors) to the dot products of the corresponding viewing angles. In particular, large Gij values imply large 〈vi, vj〉 values; that is, they indicate the correct neighbors. The scattered points get more spread as the value for p decreases. The numerical results show that the spreading is wider for large distances (small values of the dot product, bottom-left corner) and is narrower for small distances. This narrowing near the top-right corner is very appealing, because it allows us to better distinguish the true neighbors.
Figure 7.
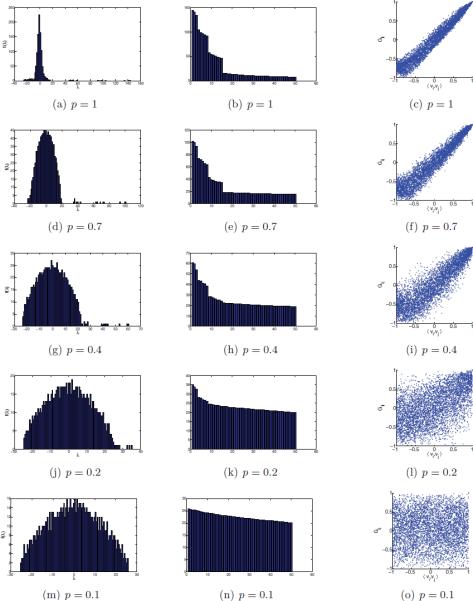
n = 1000, α = 45.6° , and different values of p . Left column: histogram of the eigenvalues of H . Middle column: bar plot of the top 50 eigenvalues of H . Right column: scatter plot of Gij as estimated in step 6 of the algorithm (y-axis) against the dot product of the true simulated viewing angles 〈vi, vj〉 (x-axis).
In the second experiment, we used parameter values that are more realistic: n = 40,000, cos α = 0.95 (α = 18.2°), and different values of p. The number of edges was m ≈ 107. The running time for each value of p was about 2 minutes, which includes the construction of the graph and the computation of the top 20 eigenvalues of H using the MATLAB eigs function. Note that this running time is negligible compared to the time required to compute all n(n − 1)/2 rotationally invariant distances. The results of this experiment are summarized in Figure 8. The spectral gap between the top three eigenvalues of H and the remaining spectrum, though small, is noticeable even for p = 0.1 (90% false links), and even the multiplicities 5 and 7 are easily distinguishable (see Figure 8(d)). The estimated Gij's provide a very good approximation to the dot products 〈vi, vj〉 between the true viewing angles, and the approximation is especially good for neighboring pairs, even for p = 0.2 (80% of shortcut edges), as can be seen in Figure 8(h). Even for p = 0.1 (Figure 8(i)), the identification of the neighbors based on the large Gij values is quite good, and there are only a few images that the algorithm would confusingly consider as neighbors.
Figure 8.
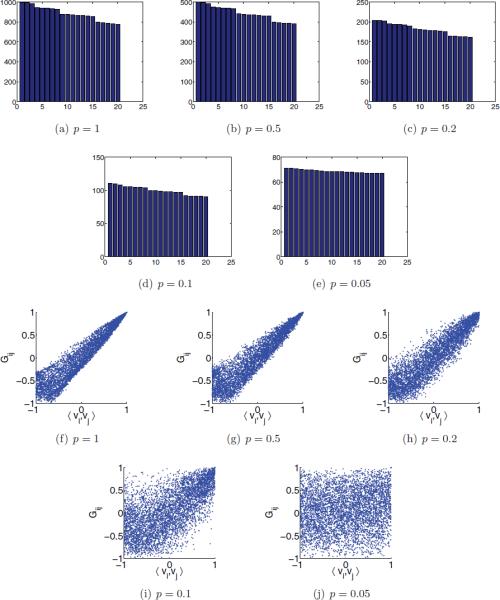
n =40000, α = 18.2° , and different values of p . Top two rows: bar plot of the top 20 eigenvalues of H . Bottom two rows: scatter plot of Gij as estimated in step 6 of the algorithm (y-axis) against the dot product of the true simulated viewing angles 〈vi , vj〉 (x-axis).
7.2. Experiments with noisy simulated images
In the second series of experiments, we tested the eigenvector method on different sets of 20,000 simulated noisy projection images of the ribosomal 50S subunit, each set corresponding to a different level of noise. Including the mirrored images, the total number of images was n = 40,000. The simulated images were generated as noise-free centered projections of the macromolecule, whose corresponding rotations were uniformly distributed SO(3). Each projection was of size 129 × 129 pixels. Next, we fixed a signal-to-noise ratio (SNR), and added to each clean projection additive Gaussian white noise of the prescribed SNR. The SNR in all our experiments is defined by
| (7.1) |
where Var is the variance (energy), Signal is the clean projection image, and Noise is the noise realization of that image. Figure 9 shows one of the projections at different SNR levels.
Figure 9.

Simulated projection with various levels of additive Gaussian white noise.
For each set of n = 40,000 simulated images with a fixed SNR, we need to compute all rotationally invariant distances (1.3) and optimal alignment angles (2.1). This computation can be quite time consuming. Also, we need to pay special attention to making the computation accurate, as it involves rotating images that are specified on a Cartesian grid rather than on a polar grid. There are quite a few papers that deal with the problem of fast and accurate rotational alignment of images; see, e.g., [22, 14, 6]. In the experiments reported here we rotationally align the images using a method that we recently developed that uses a steerable basis of eigenimages [21, 32]. Using this method, we computed the rotational alignments in about 30 minutes using all eight cores (here the computation ran in parallel). The images are first radially masked since pixels near the image boundaries (also known as the “ears”) correspond to noise rather than signal. Then, the masked images are linearly projected onto the subspace spanned by a specified number M of eigenimages that correspond to the largest eigenvalues of the images' covariance matrix. After this linear projection, the images are represented by their M expansion coefficients instead of their original pixelwise representation, thus achieving significant compression for M ≪ 1292. This compression not only facilitates a faster computation for rotational alignment but also amounts to filtering. The particular choice of M can be assisted by inspecting the numerical spectrum of the covariance matrix, but we do not go into the details of this procedure. For SNR = 1/64 we used M = 55 eigenimages, for SNR = 1/32 we used M = 90, for SNR = 1/16 we used M = 120, and for higher values of the SNR we used M = 200.
The histograms of Figure 10 demonstrate the ability of small rotationally invariant distances to indicate images with similar viewing directions. For each image we use the rotationally invariant distances to find its 40 nearest neighbors among the entire set of 40,000 images. In our simulation we know the original viewing directions, so for each image we compute the angles (in degrees) between the viewing direction of the image and the viewing directions of its 40 neighbors. Small angles indicate successful identification of “true” neighbors that belong to a small spherical cap, while large angles correspond to outliers, that later lead to shortcut edges in the graph. We see that for SNR = 1/2 there are no outliers, and all the viewing directions of the neighbors belong to a spherical cap whose opening angle is about 8°. However, for lower values of the SNR, there are outliers, indicated by arbitrarily large angles (all the way to 180°).
Figure 10.

Histograms of the angle (in degrees, x-axis) between the viewing directions of 40,000 images and the viewing directions of their 40 nearest neighboring images as found by computing the rotationally invariant distances.
After computing the rotationally invariant distances and optimal alignment angles, we use the N = 40 nearest neighbors of each image to construct the sparse matrix H using the “intersection” rule (i.e., {i, j} ∈ E iff i is one of the 40 nearest neighbors of j and j is one of the 40 nearest neighbors of i). Note that, following the application of the intersection rule, it may happen (especially for low values of the SNR) that some vertices are of degree 0 (i.e., vertices that have no links with other vertices). We delete from the matrix H the rows and columns corresponding to degree 0 vertices. After this removal, it is still possible for different vertices to have different degrees (between 1 and 40), rendering the importance of the normalization step . We then compute the eigenvectors and eigenvalues of . Figure 11 shows the top 10 eigenvalues of for different values of the SNR. The multiplicity 3, and even the multiplicity 5, are evident for high values of the SNR, such as SNR = 1/2 and SNR = 1/16. Figure 12 shows scatter plots of the dot products between the viewing directions 〈vi, vj〉 and the Gij's that are deduced from the computed eigenvectors. For SNR = 1/2, SNR = 1/16, and SNR = 1/32 we get the desired linear correspondence between 〈vi, vj〉 and Gij from which we can infer the true neighbors. For SNR = 1/64 we do not get the desired spectrum, and from the values of Gij we cannot infer the true neighbors. Still, a closer examination of the scatter plot for SNR = 1/64 reveals that points are not scattered randomly but rather have some structure. In section 7.4 we discuss how to improve the identification of true neighbors, but already at this point we have established that our method works well even for SNR as low as 1/32.
Figure 11.

Bar plots of the 10 largest eigenvalues of . Since the eigenvalues are very close to 1, the y-axis corresponds to 1 − λ.
Figure 12.

Scatter plots of Gij (computed from the top three eigenvectors of ) against 〈vi, vj〉.
7.3. Numerical comparison with diffusion maps
We compared our algorithm against what we refer to as the “diffusion maps” approach. Diffusion maps were introduced in [3], but here we do not assume the reader to be familiar with that method in its generality. We are not aware of any earlier attempts to apply diffusion maps for the solution of the class averaging problem in cryo-EM. We note, however, that the diffusion maps approach presented below is quite similar to our solution to the problem of two-dimensional (2D) random tomography [5], where the goal is to find the unknown viewing angles of one-dimensional (1D) tomographic projections of an unknown 2D object; see also [1, 2]. In that regard, we emphasize that the main difference between the 3D cryo-EM class averaging problem and its 2D counterpart is perhaps the extra angular information that we encode in the class averaging matrix H. This angular information does not exist in the 2D problem, where 1D projection signals (instead of 2D images) are compared.
In the diffusion maps approach, the matrix H is replaced by the adjacency matrix A of the graph G = (V, E). Specifically,
| (7.2) |
Notice that Aij = |Hij|. We normalize the matrix A the same way we normalized H. That is, we define as . Under the “clean” model of section 6, the eigenvectors of A approximate the eigenfunctions of an integral operator over the sphere whose kernel function is the characteristic function of a small spherical cap. As such, this operator commutes with rotations, and from the Funk-Hecke theorem [19, p. 195] it follows that its eigenfunctions are the spherical harmonics, whose multiplicities are 1, 3, 5,… (see, e.g., the discussion in [4, section 4.4]). In particular, the second, third, and fourth eigenvectors φ2, φ3, and φ4 of correspond to the linear spherical harmonics x, y, and z (multiplicity 3), where v = (x, y, z) is the viewing direction. The first eigenvector φ1 corresponds to the constant function and is therefore not required by this method. This motivates us to define
and
The above discussion implies that under the “clean” model of section 6 we have that .
Figure 13 depicts bar plots of the largest 10 eigenvalues of the matrix for different values of the SNR. Notice that λ1 = 1 and that the multiplicity 3 of λ2, λ3, λ4 and the multiplicity 5 of λ5,…, λ9 are evident for SNR = 1/2 and SNR = 1/16. Figure 14 shows scatter plots of against 〈vi, vj〉. The diffusion maps approach works well even for SNR = 1/32, but also breaks down for SNR = 1/64.
Figure 13.

Bar plots of the 10 largest eigenvalues of . Since the eigenvalues are very close to 1 , the y-axis corresponds to 1 − λ.
Figure 14.

Scatter plots of (computed from the second, third, and fourth eigenvectors of ) against 〈vi, vj〉.
From the numerical experiments shown thus far we cannot conclude that the eigenvectors of outperform the eigenvectors of in terms of improving the identification of the true neighbors. We therefore conducted another experiment with SNR = 1/40. From Figure 15 we draw the conclusion that the method based on the matrix outperforms the diffusion maps approach.
Figure 15.

SNR = 1/40: scatter plots using the eigenvectors of (left) and using the eigenvectors of (right).
7.4. Using more than three eigenvectors
Thus far we have seen the usefulness of the H matrix method for SNRs as low as 1/40, but it was not successful for SNR = 1/64. Also, the reader may question the validity of the assumption that the viewing directions are uniformly distributed over the sphere, an assumption that seems essential in order to get the linear relation between Gij and 〈vi, vj〉. We now address these important issues using both theory and numerical simulations.
The first point that we would like to make here is that in the class averaging problem, we are not required to find the viewing directions of the images. We just need to find images with similar viewing directions. Once the neighboring images are identified, they can be rotationally aligned and averaged to produce images of higher SNR, and later procedures that are based on common lines and refinements can be used to deduce the viewing directions of the class averages. Asking for the viewing directions is perhaps too much to require at this preliminary stage of the data processing. Instead, we can settle for improving our identification of neighbors.
The second point that we raise is that the eigenvectors of the matrix approximate the eigenfunctions of an integral operator over SO(3), even if the viewing directions are not uniformly distributed. Since the eigenfunctions are continuous (they become more oscillatory for smaller eigenvalues of ), it follows that the eigenvectors of do not change by much (as tangent vector fields to the sphere) for images whose viewing directions are restricted to the same spherical cap. However, we do not need to restrict ourselves to just the top three eigenvectors as we have done up to this point. We can use more than just three eigenvectors in order to identify images with similar viewing directions. Let K ≥ 3 be the of eigenvectors ψ1, ψ2,…, ψK that we use. For the ith image (i = 1, …, n) we define as
| (7.3) |
Moreover, we define the similarity measure between image i and image j as
| (7.4) |
and we postidentify an image j as a neighbor of image i if is large enough.
This classification method is proved to be quite powerful in practice. We applied it with K = 80 to the set of noisy images with SNR = 1/64, for which we observed already that K = 3 failed. For every image we find its 40 nearest neighbors based on . In the simulation we know the viewing directions of the images, and we compute for each pair of suspected neighboring images the angle (in degrees) between their viewing directions. The histogram of these angles is shown in Figure 16(a). About 92% of the identified images belong to a small spherical cap of opening angle 20°, whereas this percentage is only about 65% when neighbors are identified by the rotationally invariant distances (Figure 16(c)). For the diffusion maps approach, it is also possible to use K≥ 3 eigenvectors. The result of the diffusion maps approach with K = 80 is shown in Figure 16(b). Also for this modified diffusion maps approach about 92% of the identified images are in a spherical cap of opening angle 20°. We remark that for SNR = 1/50 this percentage goes up to about 98%. We did not experiment with SNRs below 1/64.
Figure 16.

SNR = 1/64. Histogram of the angles (x-axis, in degrees) between the viewing directions of each image (out of 40,000) and its 40 neighboring images. (a) Neighbors are postidentified usingK = 80 eigenvectors of . (b) Neighbors are postidentified using 80 eigenvectors of . (c) Neighbors are identified using the original rotationally invariant distances.
8. Summary and discussion
In this paper we introduced a new algorithm for identifying cryo-EM noisy projection images with nearby viewing angles. This identification is an important first step in 3D structure determination of macromolecules from cryo-EM, because once identified, these images can be rotationally aligned and averaged to produce “class averages” of better quality. The main advantage of our algorithm is its extreme robustness to noise. The algorithm is also very effcient in terms of running time and memory requirements, as it is based on the computation of the top few eigenvectors of a sparse Hermitian matrix. These advantages were demonstrated in our numerical experiments.
The main core of our algorithm is a special construction of a sparse Hermitian matrix H. The nonzero entries of H correspond to pairs of images whose rotationally invariant distances are relatively small. The nonzero entries are set to take complex-valued numbers of unit magnitude, with phases that are equal to the optimal in-plane rotational alignment angles between the images. We show that images with nearby viewing angles are identified from the top three eigenvectors of that matrix. The construction of the matrix H here is similar to the construction in our solution to the angular synchronization problem [23]. The main difference is that while angular synchronization required only the top eigenvector, here we need the top three eigenvectors in order to identify images with nearby viewing directions. We explain this difference using the topology of the sphere and, more specifically, the hairy ball theorem.
The robustness of the algorithm is guaranteed by random matrix theory, whose application here is made possible by the special construction of H, since the average of points on the unit circle in the complex plane is 0. The admissibility (correctness) of the algorithm follows from the spectral properties of H, which result from the fact that H is a discretization of a local version of the parallel transport operator on S2. The exact analysis of the spectral properties of this local parallel transport operator are reported in [13] using representation theory.
The assumption that the viewing angles are uniformly distributed over S2 is important to our spectral analysis, though it may not hold for some experimental data sets. We emphasize that our algorithm identifies the correct neighbors also for nonuniform distributions, because the eigenvectors of H (and ) are continuous as a function of the viewing directions, regardless of the underlying distribution. In other words, a large value for Gij indicates that Pi and Pj have similar viewing angles also in the case of a nonuniform distribution. We also showed numerical results in which using more than three eigenvectors improves the identification of the true neighbors.
Throughout this paper we assumed the homogeneity case, that is, that all images correspond to the exact same 3D structure of the molecule. In the heterogeneity case, the molecule may have several different conformations, so that projection images also need to be classified accordingly. This classification is often extremely difficult, due to the low SNR of the images and the similarity between the 3D structures of the different conformations. We believe that the algorithm presented here may assist in solving the conformational classification problem.
We are currently applying our algorithms to real microscope image data sets. Handling real microscope images requires paying special attention to issues such as the contrast transfer function of the microscope that may be changing from one image to another, translational alignment, and other practical issues that are beyond the scope of this paper. Finally, the ideas presented here can be used in other applications that require a global rotational alignment of images, such as the structure-from-motion problem in computer vision.
Acknowledgments
We would like to thank Fred Sigworth and Ronald Coifman for introducing us to the cryo-electron microscopy problem and for many stimulating discussions. We also thank Steven (Shlomo) Gortler for reviewing an earlier version of the manuscript and for offering helpful comments
This work was supported by award R01GM090200 from the National Institute of General Medical Sciences and by award 485/10 from the Israel Science Foundation. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institute of General Medical Sciences or the National Institutes of Health.
Appendix A. Parallel transport on the sphere and related operators
Our algorithm is heavily based on (4.5), which provides a way to express the dot product between unknown viewing angles using the Hermitian dot product between vectors in obtained from an orthonormal basis of the maximal eigenspace of multiplicity 3 of the local parallel transport operator . In this appendix we calculate an explicit orthonormal basis for this eigenspace and give an elementary verification of identity (4.5) without using representation theory. In passing, we make a few important observations about the parallel transport operator that go beyond the mere purpose of identifying its maximal eigenspace. In particular, we relate the parallel transport operator to two other integral operators, which we call the common lines operator and the orthographic lines operator, first introduced in [24] and [12], respectively, as well as their localized versions. At first we disregard the complex structure, thinking of as a map from to .
A.1. Common lines and orthographic lines
One of the fundamental concepts in cryo-EM is that of the common line [26, 27]: if Pi and Pj are two projection images with corresponding rotations Ri and Rj, then the two planes v(Ri)⊥ and v(Rj)⊥ must have a common line of intersection whose normalized direction in is the unit vector
| (A.1) |
Using the orthonormal bases , for v(Ri)⊥ and , for v(Ri)⊥, the unit vector (A.1) is identified with the unit vectors (A.1) is identified with the unit vectors and , given by
| (A.2) |
and
| (A.3) |
Note that the cross product satisfies
The common lines (A.2)–(A.3) can therefore be simplified using
| (A.4) |
and
| (A.5) |
where , U3 is its third column, and I3 = (0 0 1)T is the third column of the 3 × 3 identity matrix I. As rotations are isometries, we also have that
| (A.6) |
It follows from (A.4)–(A.6) that the common lines (A.2)–(A.3) are given by
| (A.7) |
and
| (A.8) |
We proceed to define the orthographic lines oij and oji. Let be the normalized projection of v(Rj) onto v(Ri)⊥, given by
| (A.9) |
and let be the normalized projection of v(Ri) onto v(Rj)⊥, given by
| (A.10) |
We identify and with the vectors oij ∈ TRi and oji ∈ TRj, respectively, written explicitly as
| (A.11) |
and
| (A.12) |
The common lines (A.7)–(A.8) and the orthographic lines (A.11)–(A.12) are related through
| (A.13) |
where
| (A.14) |
is the 2 × 2 rotation matrix by 90°. Note that JT = J−1 = −J and that multiplication by J is equivalent to multiplication by ı in the complex structure. From (A.13) it follows that the orthographic lines are perpendicular to the common lines, that is, , because χTJχ = 0 for every .
A.2. Common lines kernel, orthographic lines kernel, and parallel transport kernel
We define the orthographic lines kernel as the 2 × 2 rank-one matrix that maps the orthographic line oji to the orthographic line oij:
| (A.15) |
Similarly, we define the common lines kernel as the 2 × 2 rank-one matrix that maps the common line cji to the common line cij:
| (A.16) |
Note that unlike the parallel transport kernel , the orthographic lines kernel and the common lines kernel do not respect the complex structure: they can be considered as maps from to , but not as maps from to .
Lemma A.1. The parallel transport kernel admits the decomposition
| (A.17) |
Proof. The geometric definition of theorthographic line implies that is the normalized velocity vector of the geodesic path from v(Rj) to v(Ri) at v(Rj). Similarly, the orthographic line is the normalized velocity vector of the geodesic path from v(Ri) to v(Rj) at v(Rj). The differential geometric definition of parallel transport means that maps oji to −oij. Moreover, since is a rotation, it must also map Joji to −Joij. Therefore, in order to verify that is indeed given by (A.17), we need to check that it satisfies
| (A.18) |
and
| (A.19) |
but these follow immediately from (A.15), (A.16), and the orthogonality of the common lines and the orthographic lines:
A.3. Global and local integral operators
Using the kernels , , and we define the integral operators , , and as follows:
where f is a function from SO(3) to . We refer to , , and as the global common lines operator, the global orthographic lines operator, and the global parallel transport operator, respectively.
We also define the local integral operator , , and ,for h∈[0,2], as
| (A.20) |
| (A.21) |
| (A.22) |
We refer to , , and as the local common lines operator, the local orthographic lines operator, and the local parallel transport operator, respectively.
A.4. Preliminary spectral analysis of the local operators
The following lemma is key to the characterization of the maximal eigenspace of .
Lemma A.2. Each of the three columns of
| (A.23) |
is an eigenfunction of both , , and , with
| (A.24) |
| (A.25) |
| (A.26) |
Proof Recalling that gives
| (A.27) |
Together with (A.16) we obtain
| (A.28) |
We note that
which, substituting in (A.28), results in
| (A.29) |
where U3 = (x y z)T. Similarly,
| (A.30) |
From (A.29) and (A.30) it follows that the integrals over SO(3) defining and in (A.20)–(A.21) collapse to the following integrals over S2:
| (A.31) |
| (A.32) |
where Cap(h) = {(x, y, z) ∈ S2 : z > 1 − h} and dS is the uniform measure over S2 satisfying ∫S2 dS = 1. In Spherical coordinates
the cap is given by 0 ≤ ϕ < 2π and 0 ≤ θ < α, where cos α = 1−h and θdϕ. In order to simplify (A.31)–(A.32) we calculate the following integrals using spherical coordinates and symmetry whenever possible:
Substituting the values of the integrals above into (A.31)–(A.32) gives
Together with Lemma A.1 we have
and the proof of the lemma is completed.
Note that from (A.16) it follows that f : is an eigenfunction of the operator satisfying
iff Jf is an eigenfunction of the operator satisfying
Indeed, suppose for all R ∈ SO(3); then
The other direction The other direction of the “iff” statement is verified in a similar manner. We conclude that the three columns of JF(R) are also eigenfunctions of with the same eigenvalue . Overall, the multiplicity of the eigenvalue λ1(h) of is 6.
A.5. Complex structure of the parallel transport kernel
We return to the complex structure and regard the parallel transport kernel as a mapping9 from to . Since parallel transport maps oji to −oij (A.11)–(A.12), the complex structure implies that
| (A.33) |
and we conclude that the single matrix element for is
| (A.34) |
We proceed to prove that the rotation of (2.5)–(2.6) obtained by optimal alignment of the bases (2.3) is the same rotation angle of the parallel transport kernel. Establishing this fact would justify that the class averaging matrix H, which is computed from the image data, is indeed the (discretized version of the) local parallel transport operator. Comparing the expressions in (A.34) and (2.5)–(2.6), we conclude that the proof consists of verifying that the identity
| (A.35) |
holds for all U ∈SO(3) with v(U) ≠ ±(0, 0, 1)T (the parallel transport operator is not defined for v(Ri) = ±v(Rj)). The sphere is a double cover of SO(3), and by Euler's formula, for U ∈ SO(3) there corresponds a vector (a unit quaternion) (a, b, c, d) ∈ S3 (a2 + b2 + c2 + d2 = 1), unique up to its antipodal point (−a, −b, −c, −d), such that
| (A.36) |
Using Euler's formula (A.36), the right-hand side of (A.35) is given by
while the left-hand side is
which verifies that the identity (A.35) holds for all U ∈ SO(3) with v(U) ≠ ±(0, 0, 1)T and the proof is completed.
A.6. Preliminary spectral analysis of the complex local parallel transport operator
In the complex structure, multiplication by J is equivalent to multiplication by ı, so the columns of JF (R) are linear combinations of the columns of F (R), and the multiplicity of the eigenvalue λ1(h) of is only 3 (instead of 6 over the reals). We have the following pair of lemmas.
Lemma A.3. The three functions ψ1, ψ2, ψ3 : SO(3) ↦ given by
| (A.37) |
| (A.38) |
| (A.39) |
are orthogonal eigenfunctions of satisfying
| (A.40) |
where
| (A.41) |
and
| (A.42) |
Proof. The fact that ψ1, ψ2, ψ3 are eigenfunctions of with eigenvalue of with eigenvalue follows immediately from (A.26 (Lemma A.2) and the complex structure. The orthogonality of the eigenfunctions and their normalization are verified through
where R3 = (x y z)T, and we used symmetry to calculate
Lemma A.4. Suppose ψ1, ψ2, ψ3 are the three eigenfunctions of given in (A.37)–(A.39), and define Ψ : SO(3) ↦ as
Then,
| (A.43) |
for all Ri,Rj ∈ SO(3).
Proof. We start the proof with an explicit computation of the absolute value of the Hermitian dot product between Ψ(Ri) and Ψ(Rj):
| (A.44) |
where . The right-hand side of (A.44) can be further simplified using Euler's formula (A.36):
for all U ∈ SO(3). Therefore,
| (A.45) |
In particular,
because
We conclude that
or, equivalently,
and the proof is completed.
Appendix B. Hairy ball theorem in the case of a finite number of images
One may argue that we should not care too much about the hairy ball theorem, because the number of images n is finite, so it is always possible to remove an arbitrarily small spherical cap from the sphere that does not include any of the n viewing angles, and that the resulting chopped sphere can be combed, using, e.g., the tangent vector field f given in (3.1). We move on to explain that the hairy ball theorem affects the eigenvectors of the matrix H even when the number of images is finite, and that the above argument for chopping off the sphere fails already for moderate values of n.
To that end, recall that in the noise-free case, the underlying graph used to construct H is a neighborhood graph on S2. It may be further assumed that an edge between Pi and Pj exists iff the angle between their viewing angles is less than or equal to α, that is, {i, j} ∈ E ⇔ vi, vj > cos α. In other words, tilting the molecule by less than α results in a projection image that is similar enough to be recognized as a neighbor of the original (nontilted) image. Consider now the union of n spherical caps of opening angle α centered at the viewing angles v1, …, vn. If this union of n spherical caps entirely covers the sphere, then it would be impossible to chop an arbitrarily small cap off the sphere without affecting the underlying graph and the matrix H. Since the surface area of a spherical cap with an opening angle α is 4π , the total surface area covered by all n caps cannot exceed (union bound). As the total surface area of the sphere is 4π, we see that a complete coverage of the sphere with random spherical caps is impossible for . For such small values of n we do not “see” the topology of the sphere through the connectivity graph, and the hairy ball theorem would not be effective. However, we are much more interested in large values of n corresponding to large image data sets that we want to class average in order to increase the SNR.
For large values of n, the probability that the sphere is not fully covered is exponentially small. The coverage problem of the sphere by random spherical caps is considered in [25, Chapter 4, pp. 85–96]. Let Pr(n, α) be the probability that n random spherical caps of opening angle α cover the sphere. Though we are not familiar with the exact value of Pr(n, α) except for special values of α and n, it is easy to derive useful upper and lower bounds for Pr(n, α) as well as its asymptotic behavior in the limit n→∞. For example, the probability that the north pole is not covered by any cap is . If the sphere is covered, then in particular the north pole is covered, and thus, a simple upper bound for Pr(n, α) is given by
A slightly more involved geometric argument [25] shows that a lower bound is given by
Combining the lower and upper bounds yields
In particular, Pr(n, α) goes to 1 exponentially quickly as n→∞; that is,
In other words, the hairy ball theorem affects the eigenstructure of H as soon as the number of images n is of the order of .
Footnotes
If and has compact support, then the X-ray transform (1.1) is a continuous function from SO(3) to . A similar statement for the Radon transform is given as an exercise in Epstein's book on the mathematics of medical imaging [9, Exercise 6.6.1, p. 215]. The proof is based on the fact that continuous functions are dense in L2 and on the fact that for functions with compact support, the L2 norm of the projection image is bounded by the L2 norm of ϕ.
v⊥ is a shorthand notation of the plane perpendicular to v and passing through the origin.
The explanation for this incorrectness is given in section 3.
We remind the reader at this point that the molecule is assumed to be generic and in particular to have a trivial point group symmetry (that is, it has no special symmetry), to ensure that projection images taken at different imaging directions cannot be perfectly rotationally aligned.
Our notation is somewhat nonstandard. The reader should not confuse TR with the tangent plane to SO(3) at the point R. For us, TR denotes the tangent plane to S2 at the point v(R), where the subscript R conveys the information that we equip this tangent space with the orthonormal basis given by the columns R1,R2 of the matrix R.
For a complete proof of the results we refer the curious reader to [13], which builds on the analysis presented in [12].
The specific metric to measure distances between images need not be the Euclidean distance, and we leave its specific choice to the user. It is possible of course to first denoise the images (e.g., by applying a radial mask and filtering) and normalize the images (so that all of them have the same Euclidean norm) in order to have distances that are statistically more significant.
There is no need to store all O(n2) distances and rotation angles. To save on storage we store only distances and angles corresponding to edges in the graph defined in step 2.
The parallel transport kernel is either a 2×2 real-valued (rotation) matrix or a 1×1 complex-valued matrix. Though our notation is ambiguous, the exact meaning of should be clear from the context.
REFERENCES
- [1].Basu S, Bresler Y. Feasibility of tomography with unknown view angles. IEEE Trans. Image Process. 2000;9:1107–1122. doi: 10.1109/83.846252. [DOI] [PubMed] [Google Scholar]
- [2].Basu S, Bresler Y. Uniqueness of tomography with unknown view angles. IEEE Trans. Image Process. 2000;9:1094–1106. doi: 10.1109/83.846251. [DOI] [PubMed] [Google Scholar]
- [3].Coifman RR, Lafon S. Diffusion maps. Appl. Comput. Harmon. Anal. 2006;21:5–30. [Google Scholar]
- [4].Coifman RR, Shkolnisky Y, Sigworth FJ, Singer A. Reference free structure determination through eigenvectors of center of mass operators. Appl. Comput. Harmon. Anal. 2010;28:296–312. doi: 10.1016/j.acha.2009.11.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].Coifman RR, Shkolnisky Y, Sigworth FJ, Singer A. Graph Laplacian tomography from unknown random projections. IEEE Trans. Image Process. 2008;17:1891–1899. doi: 10.1109/TIP.2008.2002305. [DOI] [PubMed] [Google Scholar]
- [6].Cong Y, Jiang W, Birmanns S, Zhou ZH, Chiu W, Wriggers W. Fast rotational matching of single-particle images. J. Struct. Biol. 2005;152:104–112. doi: 10.1016/j.jsb.2005.08.006. [DOI] [PubMed] [Google Scholar]
- [7].Do Carmo MP. Differential Geometry of Curves and Surfaces. Prentice-Hall; Englewood Cliffs, NJ: 1976. [Google Scholar]
- [8].Doyle DA, Cabral JM, Pfuetzner RA, Kuo A, Gulbis JM, Cohen SL, Chait B, MacKinnon R. The structure of the potassium channel: Molecular basis of K + conduction and selectivity. Science. 1998;280:69–77. doi: 10.1126/science.280.5360.69. [DOI] [PubMed] [Google Scholar]
- [9].Epstein CL. Introduction to the Mathematics of Medical Imaging. Pearson Education; Upper Saddle River, NJ: 2003. [Google Scholar]
- [10].Frank J. Three-Dimensional Electron Microscopy of Macromolecular Assemblies: Visualization of Biological Molecules in Their Native State. Oxford University Press; New York: 2006. [Google Scholar]
- [11].Goldberg DS, Roth FP. Assessing experimentally derived interactions in a small world. Proc. Natl. Acad. Sci. USA. 2003;100:4372–4376. doi: 10.1073/pnas.0735871100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].Hadani R, Singer A. Representation theoretic patterns in cryo electron microscopy I: The intrinsic reconstitution algorithm. Ann. of Math. (2) doi: 10.4007/annals.2011.174.2.11. to appear. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [13].Hadani R, Singer A. Representation theoretic patterns in cryo electron microscopy II: The class averaging problem. Found. Comput. Math. doi: 10.1007/s10208-011-9095-3. to appear. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [14].Joyeux L, Penczek PA. Efficiency of 2D alignment methods. Ultramicroscopy. 2002;92:33–46. doi: 10.1016/s0304-3991(01)00154-1. [DOI] [PubMed] [Google Scholar]
- [15].Khorunzhiy O. Discrete Random Walks, Discrete Math. Theor. Comput. Sci. Proc., AC, Assoc. Discrete Math. Theor. Comput. Sci. Nancy; France: 2003. Rooted trees and moments of large sparse random matrices; pp. 145–154. [Google Scholar]
- [16].Khorunzhy A. Sparse random matrices: Spectral edge and statistics of rooted trees. Adv. in Appl. Probab. 2001;33:124–140. [Google Scholar]
- [17].MacKinnon R. Potassium channels and the atomic basis of selective ion conduction. Nobel Lecture, Bioscience Reports. 2004;24:75–100. doi: 10.1007/s10540-004-7190-2. [DOI] [PubMed] [Google Scholar]
- [18].Milnor J. Analytic proofs of the “hairy ball theorem” and the Brouwer fixed-point theorem. Amer. Math. Monthly. 1978;85:521–524. [Google Scholar]
- [19].Natterer F. Classics Appl. Math. 32. SIAM; Philadelphia: 2001. The Mathematics of Computerized Tomography. [Google Scholar]
- [20].Penczek PA, Zhu J, Frank J. A common-lines based method for determining orientations forN > 3 particle projections simultaneously. Ultramicroscopy. 1996;63:205–218. doi: 10.1016/0304-3991(96)00037-x. [DOI] [PubMed] [Google Scholar]
- [21].Ponce C, Singer A. IEEE Trans. Image Process. Computing steerable principal components of a large set of images and their rotations. to appear. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [22].Radermacher M. Three-dimensional reconstruction from random projections: Orientational alignment via Radon transforms. Ultramicroscopy. 1994;53:121–136. doi: 10.1016/0304-3991(94)90003-5. [DOI] [PubMed] [Google Scholar]
- [23].Singer A. Angular synchronization by eigenvectors and semidefinite programming. Appl. Comput. Harmon. Anal. 2011;30:20–36. doi: 10.1016/j.acha.2010.02.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [24].Singer A, Shkolnisky Y. Three-dimensional structure determination from common lines in cryo-EM by eigenvectors and semidefinite programming. SIAM J. Imaging Sci. 2011;4:543–572. doi: 10.1137/090767777. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [25].Solomon H. Geometric Probability. SIAM; Philadelphia: 1978. [Google Scholar]
- [26].Vainshtein B, Goncharov A. Determination of the spatial orientation of arbitrarily arranged identical particles of an unknown structure from their projections. In: Imura T, Maruse S, Suzuki T, editors. Proceedings of the 11th International Congress on Electron Microscopy; Tokyo, Japan: Japan Soc. Electron Microscopy; 1986. pp. 459–460. [Google Scholar]
- [27].Van Heel M. Angular reconstitution: A posteriori assignment of projection directions for 3D reconstruction. Ultramicroscopy. 1987;21:111–123. doi: 10.1016/0304-3991(87)90078-7. [DOI] [PubMed] [Google Scholar]
- [28].van Heel M, Gowen B, Matadeen R, Orlova EV, Finn R, Pape T, Cohen D, Stark H, Schmidt R, Schatz M, Patwardhan A. Single-particle electron cryo-microscopy: Towards atomic resolution. Q. Rev. Biophys. 2000;33:307–369. doi: 10.1017/s0033583500003644. [DOI] [PubMed] [Google Scholar]
- [29].Watts DJ, Strogatz SH. Collective dynamics of small-world networks. Nature. 1998;393:440–442. doi: 10.1038/30918. [DOI] [PubMed] [Google Scholar]
- [30].Wigner EP. Characteristic vectors of bordered matrices with infinite dimensions. Ann. of Math. (2) 1955;62:548–564. [Google Scholar]
- [31].Wigner EP. On the distribution of the roots of certain symmetric matrices. Ann. of Math. (2) 1958;67:325–327. [Google Scholar]
- [32].Zhao Z, Singer A. Fast Rotational Alignment of Cryo-EM Images Using Steerable Principal Components. preprint. [Google Scholar]