
Figure 1.
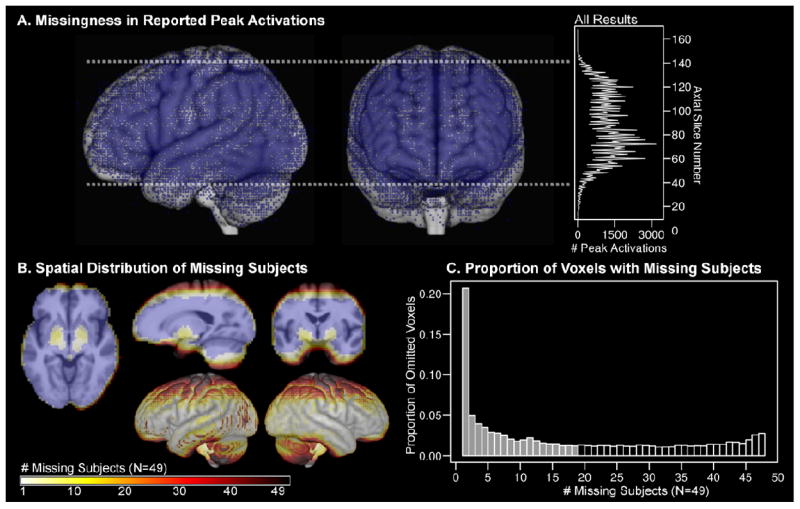
The standard approach in fMRI group statistics is to omit voxels that do not contain observations from all subjects. A) Due to common missingness mechanisms, omitted voxels would be predicted to coalesce into “blind spots” across many neuroimaging studies. A meta-result map was created in MNI space with 113,788 peak activations from 2,204 fMRI studies that were published from1996-2009, which make up the surface management system (SuMS) database (Dickson, Drury, and Van Essen, 2001). The resultant map demonstrates that peak activations (blue dots; rendered with infinite surface depth) are distributed most sparsely along typical bounding box edges (dashed white line), cortical boundaries, and frontal susceptibility artifact regions. The histogram shows the total number of peak activations for each axial slice in MNI space. B) Omitting partial datasets from analysis is costly to spatial coverage, especially along edge regions. Group data shown in B) and C) are from the speech recognition fMRI experiment analyzed in the current study (N=49). In cross sectional views, blue voxels contained non-missing data for every subject. The color scale indicates the number of subjects missing data for each voxel. Brighter colored voxels were missing data from few subjects. Darker colored voxels were missing data in a larger proportion of subjects. Most missing data occurred in regions at the boundary of the image acquisition bounding box and regions with susceptibility artifact, and correspond to missingness in A). C) The histogram shows the proportion of omitted voxels that were missing data from 1 and 48 subjects. More than 20% of those voxels were omitted as a result of missing data from only one subject. Half of the omitted voxels (11,748) were missing values from 18 or fewer subjects. There were 33,323 voxels with complete data from all subjects (N=49).