

Abstract
Perceptual learning (PL) and perceptual expertise (PE) are two fields of visual training studies that investigate how practice improves visual performance. However, previous research suggests that PL can be acquired in a task-irrelevant manner while PE cannot, and that PL is highly specific to the training objects and conditions while PE generalizes. These differences are difficult to interpret since PL and PE studies tend to differ on multiple dimensions. We designed a training study with novel objects to compare PL and PE while varying only the training task, such that the training objects, visual field, training duration and the type of learning assessment were kept constant. Manipulations of the training task sufficed to produce the standard effects obtained in PE and PL. In contrast to prior studies, we demonstrated that some degree of PE can be acquired in a task-irrelevant manner, similar to PL. Task-irrelevant PE resulted in similar shape matching ability compared to the directly trained PE. In addition, learning in both PE and PL generalizes to different untrained conditions, which does not support the idea that PE generalizes while PL is specific. Degrees of generalization can be explained by considering the psychological space of the stimuli used for training and the test of transfer.
Keywords: perceptual learning, visual training, visual experience, learning generalization
Practice can improve our ability to discriminate between visually similar objects, from recognizing faces and letters to evaluating radiographic charts. There are two theoretical constructs, both derived from visual training studies, that provide accounts of how behavioral performance is enhanced and the visual system altered with different types of visual experience. The first construct is called perceptual expertise (PE) and has been used to account for how real-world experts can easily individuate similar objects in a given domain, such as faces, letters, birds and cars (see review in Bukach & Gauthier, 2007). Real-world PE has also been modeled in laboratory training studies with novel objects (Gauthier et al., 1997; 1998; Wong et al., 2009a; 2009b). The second construct, perceptual learning (PL), pertains mainly to laboratory training studies in which subjects acquire enhanced ability to recognize simple perceptual attributes (e.g. orientation, motion direction or simple shapes) through practice (see review in Gilbert et al., 2001; Sasaki et al., 2010). Although both types of learning occur on tasks that are difficult for untrained subjects and produce training effects that typically last for at least several months, they also differ in important ways.
First, task-relevant individuation training appears to be essential for PE while PL can sometimes be elicited by mere exposure. Prior work in PE suggests that while deliberate training individuating shapes produces PE, mere exposure with the same stimuli, or even practice in some tasks for which individuation is irrelevant, is insufficient to improve the ability to discriminate between shapes of the trained category (Tanaka et al., 2005; Scott et al., 2006; McGugin et al., in press; Wong et al., 2009). In contrast, PL can be acquired without explicit training, when gated by attention and reward (Watanabe, 2001; see reviews in Sasaki et al., 2010; Seitz & Watanabe, 2009). For example, subjects’ ability to detect direction of motion was enhanced after exposure to moving dot stimuli, even though the moving dot stimuli were task irrelevant and so noisy that motion direction was not consciously perceived (Watanabe, 2001).
Second, PE and PL differ in terms of the degree of specificity in learning. By definition, the excellent recognition skills in PE generalize to new but similar exemplars of the trained category. We can easily think of real-world examples, for instance, a music-reading expert can read newly composed music pieces efficiently, and bird experts can discriminate between new birds without trouble (see also Gauthier et al., 1997; 1998; Wong et al., 2009a). Lab-training studies, using birds or novel objects also support such generalization in learning (Tanaka, Curran & Sheinberg 2005; Gauthier et al., 1998; Wong et al., 2009a). In contrast, PL is marked by the high specificity of learning effects, for instance to the trained orientation and spatial frequency (Fiorentini & Berardi, 1980), eye (Karni & Sagi, 1991), visual field (Fahle, Edelman & Poggio, 1995), motion direction (Ball, 1987), shape (Sigman et al., 2000) and task (Fahle, 1997). For example, changing the spatial frequency or rotating training shapes by 90° often lead to a large decrease in performance, down to the pre-training level (Fiorentini & Berardi, 1980). Although recent evidence suggests that the degree of generalization in PL can be modulated by various factors including task precision (Jeter et al., 2009), task difficulty (Ahissar & Hochstein, 1997) and pre-exposure in spatial locations (Xiao et al., 2008), the specificity of PL has been extensively replicated and remains a defining characteristic of this type of learning.
Why do PE and PL differ in terms of the need of task-relevant training and the degree of specificity in learning? The fields of PE and PL are traditionally distinct, and little discussion or empirical work has been devoted to comparing these two fields of visual learning. Critically, PE and PL studies tend to differ on multiple factors. For example, PE uses complex training objects (Bukach et al., 2007) while PL typically trains with simple visual attributes (Gilbert et al., 2001; Sasaki et al., 2010). The training tasks in PE often involve naming (e.g. Gauthier et al., 1997; Wong et al., 2009a), while that in PL typically involves binary judgment for orientation or size (e.g. Fiorentini & Berardi, 1980; Ball, 1987). PE studies involve foveal presentation of a single object (e.g. Gauthier et al., 1997; Tanaka et al., 2005), while PL studies often involve peripheral presentation of multiple stimuli simultaneously (e.g. Sigman et al., 2000; Karni & Sagi, 1991). The testing tasks and training duration for PE and PL are different, such that not only learning experience differs but also the manner in which learning is measured. It is therefore difficult to pinpoint the specific factor(s) that explain the differences between PE and PL.
Here, we sought to bridge these literatures empirically by comparing training effects following training protocols typical of PE and PL. The PE training task modeled an individuation training used in a number of PE studies (Gauthier et al., 1999; Wong et al., 2009a; Rossion, Kung & Tarr, 2004). The PL training task followed a visual search task based on stimulus orientation used by Sigman et al., (2005). Importantly, the only major difference between our PL and PE conditions was the training task, while the training object sets, parafoveal stimulus presentation, training duration, and pre- and post-tests for assessing training effects were matched across groups.
Methods
Subjects
Subjects were 24 undergraduate students, graduate students and staff members at Vanderbilt University. Twelve subjects were randomly assigned to the PL group (6 females, 6 males; mean age = 25.1 years; SD = 4.87), and 12 were assigned to the PE group (7 females, 5 males; mean age = 25.1 years; SD = 4.68). All subjects reported normal or corrected-to-normal vision and gave informed consent according to the guidelines of the institutional review board of Vanderbilt University. They were paid $12 per hour.
Stimuli
The experiment was conducted on Mac Minis using Matlab (Natick, MA) with the Psychophysics Toolbox extension (Brainard, 1997; Pelli, 1997). Forty-eight novel objects were modified from computer-generated Ziggerins used in prior PE work (Wong, Palmeri & Gauthier, 2009) into a black on white silhouette format using Adobe Photoshop CS2 software (Fig. 1). We used two-tone silhouette versions of Ziggerins to allow discrimination in visual periphery. Two categories of novel objects were created with 24 exemplars each. In each category, six basic shapes were created (objects in different rows; Fig. 1), which was subtly manipulated in shapes and part configuration to create another three exemplars (objects in different columns; Fig. 1).
Figure 1.

The two sets of Ziggerins in silhouette formats used for the training. Each set has 6 basic shapes (objects in different rows), each shape was subtly varied in shape and part configuration to create another three exemplars (objects in different columns). The brackets illustrate the objects used as training exemplars, novel exemplars and novel category for one subject (counterbalanced across subjects).
Training Regimens
Each subject underwent eight 1-hour sessions in which they were trained to perform either the PL or PE task on 18 exemplars of an object category (Fig. 2). The orientation of the trained exemplars was constant throughout training: either 0° (as in Figure 1) or 180° rotated in the picture plane, counterbalanced across subjects.
Figure 2.

A schematic illustration of the training and testing procedures.
The 18 training exemplars were selected from three of the columns in Fig. 1 (‘trained exemplars’), with the remaining six exemplars reserved for the pretests and posttests (‘novel exemplars’, counterbalanced across subjects). For all training tasks, the stimuli were presented in eight possible positions forming a circle 3.5° from fixation, and each object spanned a visual angle of 1.9°. Accuracy was stressed throughout the training. Before the training task was introduced, each subject studied the 24 training objects presented on a piece of paper with no time limit. This was added to provide all subjects with a sense for the subtle differences they would need to attend to, as we expected PE learning in the periphery to be much more difficult than foveal learning.
PL training
PL training was modeled after Sigman et al. (2005), using silhouettes of Ziggerins instead of ‘T’ shapes. On each trial, one of the 18 training exemplars was randomly selected to create an eight-object array, in which objects were identical in shape but either plane-rotated 0°, 90°, 180° or 270° from the subject’s assigned training orientation (Fig. 3). Subjects judged whether any object in the array was presented in the assigned target orientation by key press, and targets appeared with 50% probability. On each trial, a central fixation dot was presented for 1000ms, followed by an eight-object array for 150ms, and then the central fixation reappeared until response (Fig. 3a). Subjects were informed of their mean accuracy every 60 trials. Since this is a 2AFC task, performance was measured with sensitivity(d′) instead of general accuracy to get rid of any possible influence of response bias.
Figure 3.

The visual search training used in PL (top) and the shape naming training used in PE (bottom).
At the beginning of the training, we helped subjects learn the assigned training orientation in two ways. First, before each block of training trials and to illustrate the training orientation, each of the 18 objects in the trained orientation was presented in isolation for 150ms, each randomly shown in one of the eight array positions. Second, we started training at 250ms with the eight-object array. Once the subjects reached 70% accuracy for the first time (typically happened within the first training session), the presentation time of the eight-object array was speeded up to 150ms, and the objects were no longer presented in isolation before each block.
PE training
PE training was modeled after prior individuation trainings with novel objects (Gauthier & Tarr, 1997; Gauthier, Williams, Tar & Tanaka, 1998; Wong et al., 2009a; 2009b). Subjects learned a unique name for each of the 18 trained objects. Names consisted of 18 two-syllable nonsense words (e.g., PIMO, JEPU) that were randomly assigned to the 18 trained objects for each subject. The 18 objects were progressively introduced in four different learning phases. Four new objects were introduced in the first three phases, and six new objects were introduced in the last phase. Each learning phase included three tasks: passive viewing, verification and naming. In passive viewing, a name was presented for 1500ms at the center, followed by the corresponding object presented randomly in one of the eight parafoveal positions for 250ms. Subjects were allowed to repeat this task as many times as they preferred. In verification, subjects were required to verify whether a presented name matched with an object. On each trial, a name was presented for 1500ms, followed by an object randomly presented in one of the 8 positions for 250ms, and by a central fixation shown until a response was made. Subjects finished this task when they reached 90% matching accuracy in a block of 24 trials. For trials with incorrect response, a beep sound was presented, and the pairing of the name and the correct object was presented. In naming, a central fixation dot was presented for 200ms on each trial, followed by an object presented for 250ms and a central fixation until response (Fig. 3b). Subjects were required to type the first letter of the name of each object. Similar to verification, subjects were presented with a beep and the correct pairing if they made an incorrect response, and they finished the naming task when they reached 90% accuracy in a block of 60 trials. While passive viewing and verification were practiced on newly introduced objects, naming always used all the objects learned up to the current point in the training. Therefore subjects spent most of the time practicing naming. Once subjects started naming with all 18 objects, the presentation time of the objects was shortened to 150ms.
It is important to note that, to allow us to bridge between these two paradigms, our training conditions depart in significant ways from standard PE and PL studies. For instance, PE studies typically present training stimuli in fovea, while our PE condition presented training objects in parafoveal region. PL training stimuli typically do not include task-irrelevant variability in shape such as was included here. These changes likely make both trainings more difficult than their standard versions. While it is possible that, with similar training duration, the levels of experience acquired in our training conditions may be lower compared to prior studies, we expected that our training conditions would move subjects along the same PE and PL learning trajectories as in prior studies.
Apart from the target, the PL group saw seven more distracters on each trial during the training compared to the PE group. However, it would not cause different degrees of learning across groups. Based on prior studies (e.g. Sigman et al., 2000; 2005), PL improvement was expected to be specific for the objects in the trained orientation but not for other orientations (distracters). In other words, PL subjects were expected to improve only for the trained targets, same as the PE subjects.
Pretests and Posttests
All subjects completed one pretest session and two posttest sessions (Fig. 2). At pretest, subjects were tested with six trained objects (counterbalanced across subjects; ‘trained category’) and six novel exemplars either in the trained or inverted orientation. The first posttest was identical to the pretest. Then, a second posttest using the novel object category(‘novel category’) was performed, either on the same day as the first posttest (6 PE subjects and 7 PL subjects) or within three days after the first posttest. All sessions included 3 identical tasks, visual search, peripheral matching and central matching. The order of the three testing tasks was counterbalanced across subjects. Accuracy was stressed for all tasks.
Testing task 1: Visual Search
Visual search was similar to the PL training, except that a target object was presented at fixation for 500ms before each eight-object array. Subjects judged if there was one object in the array in the same orientation as that of the target object by key press (Fig. 4a). The target object (when present, on 50% of the trials) and all the objects in the array were identical in shape. Search performance was measured in sensitivity (d′) with 60 trials in each of four conditions.
Figure 4.

a) Visual search pre- and post test. b) Peripheral matching pre- and post-tests. c) Central matching pre- and post tests. d) The periphery-matching task used during retest 6–22 months after subjects completed their training.
Testing task 2: Peripheral Matching
Peripheral matching tested shape matching performance in the trained parafoveal region (Figure 4b). On each trial, subjects were presented with a central target object followed by an array of two objects occupying opposite parafoveal positions. One of the two objects was identical to the target while the other was a distracter. The subject’s task was to identify which object matched the target. The task had two phases: the noise threshold phase followed by the duration threshold phase.
In the noise threshold phase, visual noise was manipulated while stimulus duration was held constant. Just enough Gaussian noise was added to the objects to produce 80% accuracy in each subject when arrays of upright objects were presented for 150ms. In the pre-test and first post-test, six trained upright objects were used to determine the noise threshold while in the second post-test, six novel category objects were used (presented in a single orientation, arbitrarily defined as “upright”). Noise level was defined by the variance of the Gaussian noise (mean = 0, variance = .01 * noise level), and was adjusted after every block of 12 trials (the noise level went up 1 step for accuracy > 90%; stayed the same for accuracy between 80 – 90%, and went down 1 step for accuracy < 80%). If the average performance for 2 consecutive blocks was between 76%–84%, the average of the noise levels used for the two blocks was taken as the noise threshold. The number of blocks required for convergence was 5.83 for the PE group (range from 4–10 blocks) and 6.52 for the PL group (range from 4–15 blocks).
In the duration threshold phase, noise was held constant while the duration of the array was manipulated to determine a duration threshold for 80% accuracy in each of the four experimental conditions (trained or novel exemplars in trained or inverted orientation). To ensure that the array had disappeared before subjects had time to saccade to one of the objects, the longest presentation duration for the two-object array was set to be 250ms. The duration threshold was estimated using QUEST to keep accuracy at 80% in 72 trials (Fig. 4b). Finally, 30 catch trials were presented randomly in which the fixation turned grey briefly during the presentation of the two-object array, further discouraging subjects from breaking fixation. Subjects were required to indicate the color change at fixation when it occurred.
On each trial, a central fixation dot was presented for 500ms, followed by a target object presented at the center for 500ms, a fixation cross for 200ms, and the two object array for 150ms (noise threshold phase) or for a varied duration (duration threshold phase). The next trial did not start until a response key was pressed.
Testing task 3: Central Matching
Central matching measured shape matching performance at fovea. Similar to peripheral matching, a central target was presented first, followed by a two-object array with one element of the array matching the target. The task was again to choose which of the two array objects matched the target. In this task, however, the difficulty of the initial target was manipulated rather than the subsequent choice array.
During the noise threshold phase, we again manipulated the amount of visual Gaussian noise in the object images until each subject’s accuracy was at 80%. Targets in the pre-test and first post-test were again six trained upright objects while targets for the second post-test were six novel category objects.
During the threshold duration phase, we estimated the duration of the initial target object for each subject using QUEST to obtain the duration threshold for 80% accuracy in each of the four conditions (trained or novel exemplars in trained or inverted orientation), with the noise level held constant.
Each trial began with a 500ms central fixation dot, followed by a mask for 500ms, a target object at center for 150ms (for the noise threshold phase) or for a varied duration (for the duration threshold phase), and a mask for 500ms (Fig. 4c). Then two objects appeared side-by-side at center until response, one identical to the target object and one was a distractor. Subjects were required to identify the target object by key press. The thresholds were determined with the same method as that used in peripheral matching. To be clear, both peripheral and central matching tasks showed objects at the fovea and at the periphery, but the two tests differ in which of the two was constrained in the measurement of the threshold.
Third Posttest: Re-test and Modified Peripheral Matching
Six PE and 9 PL subjects participated in a third posttest, which was conducted 6 to 22 months after subjects completed their training (Fig. 2). This was motivated by our finding that PL subjects performed as well as PE subjects in shape matching in the earlier posttests. We first assessed whether the behavioral training effects could still be observed in a twenty-minute session identical to their last training session. Then, we tested both relatively coarse and more subtle shape discriminations in a periphery shape matching task to see if performance difference would emerge across the PL and PE. Both groups had one-third of the subjects trained on one object category and two-thirds trained on the other category. Only trained exemplars were included for the trained category, and exemplars in the novel category were counterbalanced across subjects.
On each trial, a central fixation dot was presented for 800ms, followed by a target object for 150ms, a central fixation for 500ms, and a second target for 150ms. The two target objects were presented in one of the eight trained parafoveal regions randomly (without Gaussian noise; Fig. 4d). Subjects judged whether the two objects were identical or different by key press, and accuracy was stressed. In this task, two factors were manipulated. First, the objects were either from the trained or novel category. Second, the matching trials were of two levels of difficulty. For the easy condition, the target and distracter had different basic shapes (selected from the same column; Fig. 1), while, for the difficult condition, the two objects had the same basic shapes but subtly different part configurations (selected from the same row; Fig. 1). There were 72 trials in each of the four conditions and were presented in random order.
Hypotheses and Predictions
Our design addresses several hypotheses. First, we tested whether the manipulation of training task suffices to produce the different training effects observed in PE and PL. If it is the case, we should observe typical PE and PL training effects following our training protocols. For PE, we expected to observe improved shape discrimination that generalize to new items of the trained category (Gauthier et al., 1998; Wong et al., 2009a), while we did not have a strong prediction about the orientation specificity of PE learning because prior PE studies are mixed as to whether a short training is sufficient to produce an inversion effect (Gauthier et al., 1998; 1999; Moore et al., 2006). For PL, we expected improved visual search performance specific to the trained shapes in the trained orientation for PL (Sigman et al., 2000; 2005). For each type of training, we also assessed generalization of learning effects across changes in shape and orientation. We tested four types of transfer: to novel exemplars (within the trained category), to novel category of objects, to an untrained (inverted) orientation of objects in the trained category, and to the untrained foveal area. Importantly, if PL is specific while PE generalizes, we should observe that learning transfers for PE but not for PL.
Second, we examined the possibility of task-irrelevant learning for PE and PL, i.e., whether improvements can be obtained on a transfer task that requires attention to information irrelevant for the training task. We tested visual search and shape discrimination before and after PE and PL training. For PL, the training consisted of orientation discrimination of identical shapes rotated in 0°, 90°, 180° and 270°. In each training display, the presented objects were identical in shape and the rotations across 90° involved global shape changes. As such, fine shape differences across training objects shown in different displays were irrelevant to the visual search training. Therefore any improved fine-level shape discrimination following PL training would indicate task-irrelevant perceptual expertise (TIPE). Similarly, we assessed if task-irrelevant perceptual learning (TIPL) was acquired following the PE training. The shape naming training in PE involved one object at a time, and emphasized discriminating between fine shape differences across objects that were always presented in the same orientation. The ability to detect object orientations in a multi-object display was irrelevant to the shape naming training in PE. So, any improved visual search performance following PE training indicates TIPL.
Results
Training Performance
Performance for both groups improved throughout the eight-hour training. Performance for the PL group leveled off after the fifth training session, with an average accuracy of 95.5% during the final training session (Fig. 5a). Performance for the PE group constantly increased to around 80% till the end of the training (Fig. 5b).
Figure 5.

Training effects of the PL group (A) and the PE group (B). For the PE group, the accuracy was scaled to that relative to all 18 objects such that performance during the four different training phases with different numbers of training objects (4, 8, 12 or 18) are comparable. The dotted line on (B) indicates chance level for the naming task. Error bars plot the standard error of each data point.
Examining the training effects in PE
For PE, the peripheral matching task was used to assess whether shape discrimination ability was enhanced after training (Gauthier et al., 1998; Wong et al., 2009a), while we did not have a strong prediction about the orientation specificity of PE learning (inversion effects can be large for real-world perceptual experts (e.g., Curby, Glazek & Gauthier, 2009, they are not always found in laboratory-trained experts, e.g., Gauthier et al., 1999).
We compared performance for the trained objects (in the trained orientation) before and after training with two measures. The noise threshold allowed us to compare performance between the trained and novel category. Note that objects were always presented in the trained orientation in the noise threshold test, so this measure did not allow us to assess any orientation effects across training. Second, the duration threshold allowed us to compare shape matching ability between trained and novel exemplars, trained and novel category, and trained and inverted orientation. However, our analyses showed that the duration threshold measure was not sensitive to any changes before and after training. For simplicity, analyses related to the duration threshold measure are not reported below.
A one-way ANOVA on Session (pretest / posttest) was conducted on the noise threshold for the trained category in the trained orientation. The main effect of Session was significant, F(1,11) = 6.71, p = .025 (Mpre = 0.92, SD = 1.14; Mpost = 2.17, SD = 1.70; Cohen’s d = .86, CI.95 of d = .09 to 1.38; Fritz, Morris & Richler, in press; Smithson, 2003), indicating that the noise required to keep subjects’ accuracy at 80% increased after PE training (Fig. 6a). For the catch trials, average accuracy for detecting the color change of the fixation dot was 83%, confirming that subjects consistently kept fixation at center. Our PE condition resulted in the expected PE training effects, i.e., improved shape matching ability.
Figure 6.

Performance for the periphery matching task before and after training using the noise threshold measure for PE (A) and PL (B), and the duration threshold measure for PE (C) and PL (D).
Next, we examined whether the increased noise threshold for shape matching generalized from the trained to the novel category. At posttest, a one-way ANOVA with Category (trained / novel) on the noise threshold did not reveal any significant difference across Category (F < 1; Fig. 6a). However, the performance for the novel category was similar to that for the trained category before training. A one-way ANOVA with Category (trained at pretest / novel at posttest) on the noise threshold did not reveal any significant difference across Category (F1,11 = 1.20, p = .30). These mixed results do not allow us to conclude that PE learning generalizes to the novel category.
In addition, we did not observe generalization of PE learning to the novel category, novel exemplars with the duration threshold (Fig. 6c), perhaps caused by the limited sensitivity of this measure to PE learning. The performance for the shape matching task performed at the untrained foveal region remained similar across training, when measured with the noise threshold or the duration threshold (all Fs < 1; Fig. 7a; 7c), so we found no evidence that training in parafoveal regions affected shape matching performance at fovea.
Figure 7.

Performance for the central matching task before and after training using the noise threshold measure for PE (A) and PL (B), and the duration threshold measure for PE (C) and PL (D).
In sum, the PE training improved shape matching ability for the trained exemplars in the peripheral region as expected (Gauthier et al., 1997; 1998; Wong et al., 2009a), and we could not assess whether the training effect was specific to the trained orientation. Our tasks did not detect transfer to novel exemplars, a novel category, or to the untrained fovea.
Examining the training effects in PL
For PL, the visual search task was used to examine whether visual search ability was improved after training. Following Sigman et al. (2005), we expected to observe orientation- and category-specific improvement for the trained objects after PL training.
We first examined if the PL training led to orientation-specific improvement in visual search. A 2x2 ANOVA with Session (pretest / posttest) x Orientation (trained / inverted) was conducted on d′ for the trained exemplars. A main effect of Session was obtained, F(1,11) = 66.9, p <= .0001, with better performance during posttest than pretest. A main effect of Orientation was obtained, F(1,11) = 40.8, p <= .0001, which interacted with Session, F(1,11) = 63.9, p ≤ .0001 (ηp2 = .85, CI.95 of ηp2 = .55 to .91; Fig. 8a). Scheffé tests (p < .05) revealed that performance for both trained and inverted orientation improved after training. An inversion effect was absent during pretest but was significant at posttest, with better performance for the trained than the inverted orientation. In other words, we observed orientation-specific improvement for the visual search task after the PL training.
Figure 8.

Performance for the visual search task before and after training for PL (A) and PE (B).
To test whether the PL training effect was category-specific (Sigman et al., 2000; 2005), we compared the magnitude of the inversion effect between the trained category (trained exemplars) and the novel category at posttest. A 2x2 ANOVA on Category (trained / novel) x Orientation (trained / inverted) on d′ was performed on posttest results. The main effect of Category was significant, F(1,11) = 52.1, p <= .0001, with better performance for trained than novel objects. A main effect of Orientation was found, F(1,11) = 49.9, p <= .0001, with better performance for trained than inverted orientation. The Category x Orientation interaction was significant, F(1,11) = 73.4, p <= .0001 (ηp2 = .87, CI.95 of ηp2 = .59 to .92; Fig. 8a). Scheffé tests (p < .05) revealed that the performance for the trained objects was better than novel objects only for the trained orientation but not for the inverted orientation. These results suggest that typical training effects, i.e., orientation- and category-specific learning for PL, were obtained with our training protocol.
Next, we tested whether PL transfers from trained to novel exemplars of the trained category (we did not measure orientation judgments in the untrained fovea because the task would have been trivial and at ceiling). For the novel exemplars, a 2x2 ANOVA with Session (pretest / posttest) x Orientation (trained / inverted) was conducted on d′. A main effect of Session was obtained, F(1,11) = 34.7, p = .0001, with better performance during posttest than pretest. A main effect of Orientation was obtained, F(1,11) = 38.9, p <= .0001, which interacted with Session, F(1,11) = 124.3, p ≤ .0001 (Fig. 8a). Scheffé tests (p < .05) revealed that performance for both trained and inverted orientation improved after training. An inversion effect was absent during pretest but was significant at posttest, with better performance for the trained than the inverted orientation, suggesting that the PL training also led to orientation-specific improvement for the untrained novel exemplars.
To compare whether the transfer was complete, we compared the performance for the trained and novel exemplars at pretest and at posttest respectively. Before training, a 2x2 ANOVA with Exemplar (trained / novel) x Orientation (trained / inverted) on d′ did not reveal any significant effect (all ps > .25). After training, a similar analysis revealed a significant main effect of Orientation, F(1,11) = 139.8, p ≤ .0001, while the Exemplar x Orientation interaction was not significant (F < 1). Scheffé tests (p < .05) revealed that the performance for the trained and novel exemplars was similar for either orientation, suggesting that the transfer of PL was complete to novel exemplars.
To summarize, we observed orientation- and category-specific learning with our PL training protocol, consistent with prior PL findings (Sigman et al., 2000; 2005). PL transferred completely to the novel exemplars in the trained category, in contrast to prior PL findings that PL is specific to the trained stimuli (Fiorentini & Berardi, 1980; Sigman et al., 2000). This may be because our trained and novel exemplars are highly similar (see discussion).
Our results confirmed that with matched training object sets, parafoveal stimulus presentation, training duration, and pre- and post-tests, differences in training tasks suffice to reproduce the typical differences in learning effects in PE and PL respectively. Admittedly, the PL effects were stronger, likely because of the detrimental effect of parafoveal training on shape identification (while both training performance and noise threshold reveal improvements in identification of trained exemplars for the PE group). Next, we examined whether task-irrelevant perceptual expertise (TIPE) or task-irrelevant perceptual learning (TIPL) could be observed following our PL and PE training respectively.
Task-irrelevant perceptual expertise (TIPE)
Fine-level shape discrimination skill was irrelevant to the PL training, which was about orientation discrimination among identical shapes rotated in 0°, 90°, 180° and 270°. Therefore any improved shape discrimination performance after PL training indicates task-irrelevant perceptual expertise (TIPE).
In the peripheral matching task, we compared whether the performance for the trained objects in the trained orientation was enhanced across training, measured by the noise threshold and the duration threshold for 80% matching accuracy.
On the noise threshold, a one-way ANOVA on Session (pretest / posttest) was conducted for the trained category in the trained orientation for PL. The main effect of Session was significant, F(1,11) = 9.24, p = .011 (Mpre = .92, SD = 1.33; Mpost = 2.67, SD = 2.54; Cohen’s d = .86, CI.95 of d = .19 to 1.54; Fig. 6b). For the catch trials, average accuracy for detecting the color change of the fixation dot was 82%, confirming that subjects consistently kept fixation at center. This suggests that task-irrelevant shape matching performance was enhanced after PL training, demonstrating that TIPE can be found.
For both PE and TIPE, the improvement in noise threshold was similar -transfer to novel category seems limited and the variability for the novel category was larger than other conditions (Fig. 6a; 6b). Therefore, we combined the two groups for better statistical power and re-examined whether improvement in shape matching was transferred to novel object category. The 2x3 ANOVA with Group (PE / PL) and Test (trainedPre / trainedPost / novelPost) on noise threshold revealed a significant main effect of Test, F(2,44) = 4.74, p = . 014. Post-hoc tests (LSD) indicated that performance for trainedPost was better than that for trainedPre (p < .05), and marginally better than novelPost (p = .08). Performance for novelPost was similar to that for trainedPre (p > .2). These results suggest that training, regardless of the task, improved shape matching in parafoveal region for trained category, with limited transfer to a novel object category.
Task-irrelevant perceptual learning (TIPL)
Discriminations based on object orientation were not relevant in the PE training, where the task concerned discriminating highly-similar shapes that were always presented in the same training orientation and in isolation. Therefore, any improved visual search performance after PE training would indicate task-irrelevant perceptual learning (TIPL). In the visual search task, we assessed whether search performance for the trained exemplars improved after the PE training.
For the trained exemplars, a 2x2 ANOVA with Session (pretest / posttest) x Orientation (trained / inverted) on d′ revealed a significant main effect of Session, F(1,11) = 11.5, p = .006 (ηp2 = .51, CI.95 of ηp2 = .06 to .72; Fig. 8b), with better performance at posttest than pretest. The Session x Orientation interaction was not significant (F1,11 = 2.22, p = .16).
For the novel exemplars, a similar analysis on d′ revealed a significant main effect of Session, F(1,11) = 6.56, p = .027, with a better performance at posttest than pretest. The main effect of Orientation was significant, F(1,11) = 10.1, p = .009 (ηp2 = .48, CI.95 of ηp2 = .04 to .70), with a better performance for trained than untrained orientation. While the Session x Orientation interaction did not reach significance (F1,11 = 3.62, p = .08), Scheffé tests (p < .05) revealed that an inversion effect (trained d′ > inverted d′) was found at posttest but not pretest, suggesting some degree of orientation specificity in the TIPL. In contrast, the visual search performance for the novel category did not differ across the two orientations after training (F < 1).
In sum, visual search performance for the trained category (for both trained and novel exemplars) was enhanced across PE training, indicating that TIPL occurred.
Training effects sustained after 6 months
Six PE and 9 PL subjects were available to come back for a 20 min training session, 6 to 22 months after the end of the initial training. The PE group continued the last phase of their shape naming training, while the PL group performed the visual search training. Their performance was compared to that at the beginning and the end of the training.
For PE, a one-way ANOVA with Session (beginning / end / retest) on naming accuracy during the naming training was performed. Results revealed a main effect of Session, F(2,10) = 27.0, p ≤ .0001 (ηp2 = .84, CI.95 of ηp2 = .45 to .90; Fig. 5b). Post-hoc LSD tests (p < .05) revealed that the retest performance was better than that at the beginning of the training, but worse than at the end of training.
For PL, a similar main effect of Session was found on d′ during visual search, F(2,16) = 35.8, p ≤ .0001 (ηp2 = .82, CI.95 of ηp2 = .54 to .88; Fig. 5a). Post-hoc LSD tests (p < .05) revealed that performance at the end of training and retest were similar, and both were better than that at the beginning of the training.
These results suggest that behavioral improvement following PE and PL training lasts for at least 6 months. The decline in performance with time in the PE group may depend on memory for the specific names, while PL performance remaining high for at least 6 months is consistent with prior PL work (Karni & Sagi, 1991).
Easy versus difficult shape matching
It is surprising that the magnitude of improvement on shape matching in the PE group and in the PL group were similar (Fig. 6a-b), because task-relevant learning where attention is intentionally directed to the relevant dimension is expected to result in more effective learning (McGugin et al., in press; Wong et al., 2009a; Folstein, Gauthier & Palmeri, submitted; Sasaki, 2010; Roelfsema et al., 2010). One explanation may lie in differences between the difficulty of discriminations required for the naming task and the periphery matching task used to probe PE. Inspection of Figure 1 reveals that objects in different rows are easier to discriminate than objects that share a row. PE training required discrimination between both same-row and different-row objects while the periphery matching task required only easier discriminations between objects in different rows. Therefore, the shape matching task may not have been sufficiently difficult to reveal an advantage of task-relevant training in the PE group. In addition, it is possible that the periphery shape matching task, in which the target and distracter objects were presented at the same time, was relatively easier for the PL group since they were trained to perceive multiple objects simultaneously, which was not the case for the PE group since objects were presented in isolation during their training.
As another test of the shape matching performance by the PE and PL groups, we used a sequential matching task with objects presented in isolation and manipulated two levels of difficulty in shape matching with either trained or novel category (see Methods). The novel category provided a baseline according to which improvement due to training could be assessed.
A three-way ANOVA with Group (PL/PE) x Category (trained / novel) x Difficulty (easy / difficult) on d′ revealed a significant main effect of Category, F(1,13) = 7.27, p = .018 (ηp2 = .36, CI.95 of ηp2 = .01 to .61), with performance for the trained category better than for the novel category (Fig. 9), and a main effect of Difficulty, F(1,13) = 136.8, p ≤ .0001 (ηp2 = .91, CI.95 of ηp2 = .74 to .95). Importantly, no effect involving Group reached significance (all Fs < 1), suggesting that the shape matching ability for PE and TIPE were again similar, regardless of whether the distracters were highly similar to the targets or not. In other words, we found evidence of a lasting learning effect, with an advantage for the trained over the untrained category. However, no evidence that under parafoveal training conditions, a directly-trained PE group performed better in shape matching than a group where TIPE developed during a PL training.
Figure 9.
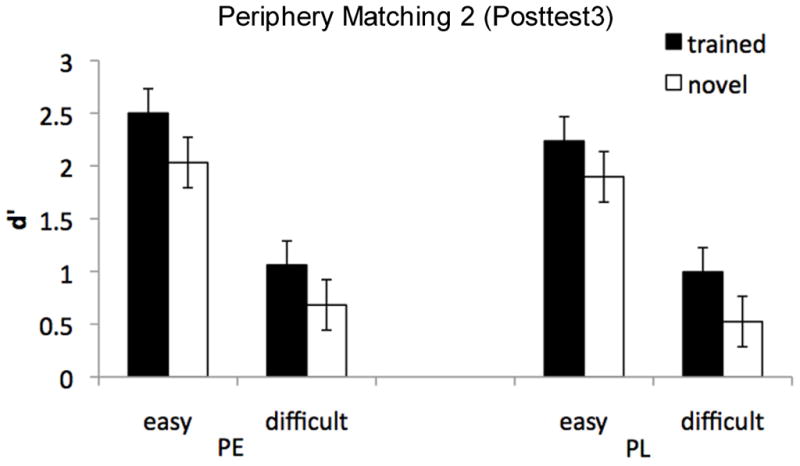
Performance for the second periphery matching task during posttest 3.
Discussion
The role of training experience
Given matched training stimuli, visual fields, training duration and testing tasks, different training experience led our PE and PL groups to show training effects similar to those typically obtained in each field of study. That is, we found improvements in shape matching for the trained exemplars for the PE group and orientation- and category-specific improvements in visual search for the PL group (Gauthier et al., 1998; Sigman et al., 2000; 2005). Both types of training resulted in learning effects that sustained for at least 6 months, but with different patterns of specificity. Our results highlight the important role of training experience in determining the pattern of behavioral learning, and the advantage of manipulating training experience, since in the context of standard PE or PL studies, subjects would not have been given a chance to demonstrate that their learning transfers onto other tasks.
Task-irrelevant perceptual expertise (TIPE)
To some extent perceptual expertise in fine-level shape discrimination can be acquired in a task-irrelevant manner, as demonstrated by the improved shape discrimination performance following PL training. The PL group was at least as capable as the directly trained PE group in shape discrimination, regardless of whether the testing task was relatively easy or required very fine-level shape judgment. TIPE appears to be as effective as the individuation training in PE. This needs to be qualified: PE training is not typically done in the periphery and our results highlight how difficult it is to learn to individuate subtly different shapes under these conditions. Given the difficulty of the parafoveal PE training and short training duration, it is likely that our PE training had not yet induced perceptual expertise at a level that compares with performance typically obtained when training is foveal, but had moved subjects along the trajectory of becoming perceptual experts (Gauthier et al., 1997; 1998; Wong et al., 2009a; 2009b). Our results do not allow us to determine whether parafoveal PE training can eventually reach levels similar to those obtained in foveal training with the objects we used here. But what is clear, and perhaps most surprising, is that under our training conditions, direct individuation training did not give the PE group an advantage on shape discrimination. This is a very different picture from what is typically obtained in foveal training where individuation generally produces an advantage over other training tasks (Tanaka et al., 2005; Scott et al., 2006; McGugin et al., in press; Wong et al., 2009a; Folstein, Gauthier & Palmeri, submitted).
It is also possible that parafoveal presentation actually facilitated TIPE (relative to foveal conditions), in addition to limiting PE. In the literature, task-irrelevant PL is often obtained with stimuli presented outside of the fovea (e.g. random-dot patterns in parafoveal region; Watanabe, 2001), while most of the prior PE studies presented shapes in the fovea (Gauthier et al., 1997; 1998; Tanaka et al., 2005; Scott et al., 2006; McGugin et al., in press; Wong et al., 2009). Therefore, it is possible that TIPE was found here because of parafoveal presentation. Fine-level shape information is harder to process in visual periphery than the fovea. It is possible that the subtle shape differences presented in visual periphery are not salient enough to reach awareness during the visual search training. Hence, even though the fine-level shape information is task-irrelevant, it escapes from active information filtering and is encoded during the training, a mechanism that may be similar to those proposed for TIPL (Tsushima et al., 2006).
Our results shed new light on PE studies where no learning occurred in non-individuation tasks (Tanaka et al., 2005; Scott et al., 2006; McGugin et al., in press; Wong et al., 2009a). Perhaps, the processing of fine-level shape information was not improved under these conditions not because the relevant information was not attended, but that the relevant shape information was actively filtered out, similar to the case of TIPL (Tsushima et al., 2006).
Learning specificity in PE and PL
Although the literature often suggests that PE generalizes while PL is highly specific in learning, the degree of learning specificity for PE and PL had not been compared directly. Here, using the same testing tasks, we found little evidence of transfer in PE but a complex pattern of transfer in PL. For PE, we did not observe evidence for transfer across shapes or visual field, and the duration threshold measure was not sensitive enough to assess if learning transferred across exemplars and orientation. However, PL transfers completely to novel exemplars in the trained category but is specific to the trained orientation and shapes. While it is possible that with additional PE training or more sensitive post-tests we might have obtained more PE transfer, the evidence does not support the idea that PE generalizes but PL is specific. Instead, PL seems to be more general, consistent with the suggestion that generalization is common in PL (Liu, 2000; see also Jeter et al., 2009; Ahissar & Hochstein, 1997; Xiao et al., 2008; Baeck & Op de Beeck, 2010).
When does learning generalize, and when is it specific to the trained stimuli? In our study, PL transferred completely to the novel exemplars in the trained category, in contrast to prior PL findings that PL is specific to the trained stimuli (e.g. Fiorentini & Berardi, 1980; Sigman et al., 2000). How can we resolve this apparent conflict?
One way to address this question is by considering the multidimensional psychological space occupied by the trained and testing stimuli (Nosofsky, 1986; 1987). Stimuli can be thought as points in a multidimensional space composed of relevant dimensions on which the stimuli vary (e.g. orientation, color, contrast, etc.). After visual training, highly discriminable representations of the trained stimuli are stored in the multidimensional space (see review by Palmeri, Wong & Gauthier, 2004). Novel objects can activate each of these stored representations to different degrees based on their perceptual similarity.
Under this framework, learning transfers to novel objects if these novel stimuli occupy a region that is close to the trained part of the psychological space. For example, when the testing objects are highly similar to the trained objects (e.g. the novel exemplars are highly similar to the trained exemplars for our PL), the stored representations can easily be extrapolated for the novel objects, leading to complete transfer of learning (Palmeri, Wong & Gauthier, 2004). However, when objects are further away from the trained part of the multidimensional space, generalization of the behavioral improvement gradually diminishes and finally disappears when testing objects completely fall outside the trained space.
This can explain why prior studies typically observe limited transfer of learning. Training stimuli for most PL studies occupy a very narrow part of a certain dimension, such as one or two degrees of visual angle of gratings, or one specific position in the visual field. However, stimuli used for generalization tests usually fall outside the trained part of the space (e.g. Fiorentini & Berardi, 1980, 1981; Karni & Sagi, 1991). For example, when training stimuli were at one orientation but testing stimuli were at the orthogonal orientation, no learning transfer was observed simply because the testing stimuli have completely fallen outside of the trained space (e.g. Fiorentini & Berardi, 1980). This account is supported by prior PL findings that orientation discrimination learning transferred completely to stimulus rotated in 30° but not in 90° (Fiorentini & Berardi, 1981), and that learning completely transferred when the testing orientation was ±1–2° from the trained orientation, partially transferred for ±5–10°, and no transfer for ±22.5° or more (Fahle, 2002).
Conclusion
In seeking to provide a comprehensive theory of visual learning (OP de Beeck & Baker, 2010; Gilbert et al., 2001; Sasaki et al., 2010; Roelfsema et al., 2010; Bukach et al., 2007), one limitation lies with the empirical body of evidence, in that most studies cluster in small areas within the multi-dimensional space of all possible factors that may influence learning. For instance, many studies use a single shape in parafoveal detection tasks while others use many complex shapes in foveal individuation learning. This makes it difficult to extract general principles of learning or unconfound the critical role of different aspects of a given training. This situation also encourages the segregation of work into disconnected bodies of research, such as that between PL and PE. Our study is an effort to explore the space between these traditional clusters of studies and reveals both differences and similarities between PL and PE. Specifically, by keeping the stimuli and area of the visual field constant, we demonstrated that training task matters, yielding different results in each group, and that PE and PL are more similar than expected when subjects are allowed to demonstrate transfer of learning to the other task. While TIPL had been demonstrated before under different conditions, we provide evidence that under PL training conditions and perhaps uniquely under parafoveal presentation, a task-irrelevant improvement in shape discrimination (TIPE) can be observed.
Acknowledgments
This work was supported by NIH grants 1 F32 EY019445-01, 2 RO1 EYO13441-06A2 and P30-EY008126 as well as by the Temporal Dynamics of Learning Center, NSF grant SBE-0542013.
References
- Ahissar M, Hochstein S. Task difficulty and the specificity of perceptual learning. Nature. 1997;387(6631):401–406. doi: 10.1038/387401a0. [DOI] [PubMed] [Google Scholar]
- Ball K, Sekuler R. Direction-specific improvement in motion discrimination. Vision Res. 1987;27(6):953–965. doi: 10.1016/0042-6989(87)90011-3. [DOI] [PubMed] [Google Scholar]
- Brainard DH. The psychophysics toolbox. Spatial Vision. 1997;10:433–436. [PubMed] [Google Scholar]
- Bukach CM, Gauthier I, Tarr MJ. Beyond faces and modularity: the power of an expertise framework. Trends Cogn Sci. 2006;10(4):159–166. doi: 10.1016/j.tics.2006.02.004. [DOI] [PubMed] [Google Scholar]
- Fahle M. Specificity of learning curvature, orientation, and vernier discriminations. Vision Res. 1997;37(14):1885–1895. doi: 10.1016/s0042-6989(96)00308-2. [DOI] [PubMed] [Google Scholar]
- Fahle M. Learning to perceive features below the foveal photoreceptor spacing. In: Fahle M, Poggio T, editors. Perceptual Learning. Massachusetts: MIT Press; 2002. [Google Scholar]
- Fahle M, Edelman S, Poggio T. Fast perceptual learning in hyperacuity. Vision Res. 1995;35(21):3003–3013. doi: 10.1016/0042-6989(95)00044-z. [DOI] [PubMed] [Google Scholar]
- Fiorentini A, Berardi N. Perceptual learning specific for orientation and spatial frequency. Nature. 1980;287(5777):43–44. doi: 10.1038/287043a0. [DOI] [PubMed] [Google Scholar]
- Fritz CO, Morris PE, Richler JJ. Effect size estimates: Current use, calculations, and interpretation. J Exp Psychol Gen. 2011 doi: 10.1037/a0024338. [DOI] [PubMed] [Google Scholar]
- Gauthier I, Tarr MJ. Becoming a “Greeble” expert: exploring mechanisms for face recognition. Vision Research. 1997;37(12):1673–1682. doi: 10.1016/s0042-6989(96)00286-6. [DOI] [PubMed] [Google Scholar]
- Gauthier I, Tarr MJ, Anderson AW, Skudlarski P, Gore JC. Activation of the middle fusiform ‘face area’ increases with expertise in recognizing novel objects. Nature Neuroscience. 1999;2(6):568–573. doi: 10.1038/9224. [DOI] [PubMed] [Google Scholar]
- Gauthier I, Williams P, Tarr MJ, Tanaka J. Training “Greeble” experts: A framework for studying expert object recognition processes. Vision Research. 1998;38(15/16):2401–2428. doi: 10.1016/s0042-6989(97)00442-2. [DOI] [PubMed] [Google Scholar]
- Gilbert GD, Sigman M, Crist RE. The neural basis of perceptual learning. Neuron. 2001;31:681–697. doi: 10.1016/s0896-6273(01)00424-x. [DOI] [PubMed] [Google Scholar]
- Jeter PE, Dosher BA, Petrov A, Lu Z-L. Task precision at transfer determines specificity of perceptual learning. Journal of Vision. 2009;9(3):1, 1–13. doi: 10.1167/9.3.1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Karni A, Sagi D. Where practice makes perfect in texture discrimination: evidence for primary visual cortex plasticity. Proceedings of National Academy of Sciences of the United States of America. 1991;88:4966–4970. doi: 10.1073/pnas.88.11.4966. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu Z, Weinshall D. Mechanisms of generalization in perceptual learning. Vision Res. 2000;40(1):97–109. doi: 10.1016/s0042-6989(99)00140-6. [DOI] [PubMed] [Google Scholar]
- Nosofsky RM. Attention, similarity and the identification-categorization relationship. Journal of Experimental Psychology: General. 1986;115(1):39–57. doi: 10.1037//0096-3445.115.1.39. [DOI] [PubMed] [Google Scholar]
- Nosofsky RM. Attention and learning processes in the identification and categorization of integral stimuli. Journal of Experimental Psychology: Learning, Memory and Cognition. 1987;13(1):87–108. doi: 10.1037//0278-7393.13.1.87. [DOI] [PubMed] [Google Scholar]
- McGugin RW, Tanaka JW, Lebrecht S, Tarr MJ, Gauthier I. Race-specific perceptual discrimination improvement following short individuation training with faces. Cognitive Science. 2011;35(2):330–347. doi: 10.1111/j.1551-6709.2010.01148.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Moore CD, Cohen MX, Ranganath C. Neural mechanisms of expert skills in visual working memory. J Neurosci. 2006;26(43):11187–11196. doi: 10.1523/JNEUROSCI.1873-06.2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Op de Beeck HP, Baker C. The neural basis of visual object learning. Trends in Cognitive Sciences. 2010;14(1):22–30. doi: 10.1016/j.tics.2009.11.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Palmeri TJ, Wong AC-N, Gauthier I. Computational approaches to the development of perceptual expertise. Trends in Cognitive Sciences. 2004;8(8):378–386. doi: 10.1016/j.tics.2004.06.001. [DOI] [PubMed] [Google Scholar]
- Pelli DG. The video toolbox software for visual psychophysics: transforming numbers into movies. Spatial Vision. 1997;10:437–442. [PubMed] [Google Scholar]
- Roelfsema PR, van Ooyen A, Watanabe T. Perceptual learning rules based on reinforcers and attention. Trends in Cognitive Sciences. 2010;14(2):64–71. doi: 10.1016/j.tics.2009.11.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rossion B, Kung CC, Tarr MJ. Visual expertise with nonface objects leads to competition with the early perceptual processing of faces in the human occipitotemporal cortex. Proceedings of the National Academy of Sciences of the United States of America. 2004;101:14521–14526. doi: 10.1073/pnas.0405613101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sasaki Y, Nanez JE, Watanabe T. Advances in visual perceptual learning and plasticity. Nature Reviews Neuroscience. 2010;11:53–60. doi: 10.1038/nrn2737. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Scott LS, Tanaka JW, Sheinberg DL, Curran T. A reevaluation of the electrophysiological correlates of expert object processing. Journal of Cognitive Neuroscience. 2006;18:1453–1465. doi: 10.1162/jocn.2006.18.9.1453. [DOI] [PubMed] [Google Scholar]
- Seitz AR, Watanabe T. The phenomenon of task-irrelevant perceptual learning. Vision Research. 2009;49:2604–2610. doi: 10.1016/j.visres.2009.08.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sigman M, Gilbert CD. Learning to find a shape. Nat Neurosci. 2000;3(3):264–269. doi: 10.1038/72979. [DOI] [PubMed] [Google Scholar]
- Sigman M, Pan H, Yang Y, Stern E, Silbersweig D, Gilbert CD. Top-down reorganization of activity in the visual pathway after learning a shape identification task. Neuron. 2005;46(5):823–835. doi: 10.1016/j.neuron.2005.05.014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smithson M. Confidence intervals. Thousand Oaks, CA: Sage; 2003. [Google Scholar]
- Tanaka JW, Curran T, Sheinberg D. The training and transfer of real-world perceptual expertise. Psychological Science. 2005;16(2):145–151. doi: 10.1111/j.0956-7976.2005.00795.x. [DOI] [PubMed] [Google Scholar]
- Tsushima Y, Sasaki Y, Watanebe T. Greater Disruption Due to Failure of Inhibitory Control on an Ambiguous Distractor. Science. 2006;314:1786–1788. doi: 10.1126/science.1133197. [DOI] [PubMed] [Google Scholar]
- Watanabe T, Nanez JE, Sasaki Y. Perceptual learning without perception. Nature. 2001;413(6858):844–848. doi: 10.1038/35101601. [DOI] [PubMed] [Google Scholar]
- Wong ACN, Palmeri T, Gauthier I. Conditions for face-like expertise with objects: Becoming a Ziggerin expert - but which type? Psychological Science. 2009a;20(9):1108–1117. doi: 10.1111/j.1467-9280.2009.02430.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wong ACN, Palmeri T, Rogers BP, Gore JC, Gauthier I. Beyond shape: How you learn about objects affects how they are represented in visual cortex. PLoS One. 2009b;4(12):e8405. doi: 10.1371/journal.pone.0008405. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xiao LQ, Zhang JY, Wong R, Klein SA, Levi DM, Yu C. Complete transfer of perceptual learning across retinal locations enabled by double training. Current Biology. 2008;18:1922–1926. doi: 10.1016/j.cub.2008.10.030. [DOI] [PMC free article] [PubMed] [Google Scholar]