
Figure 1.
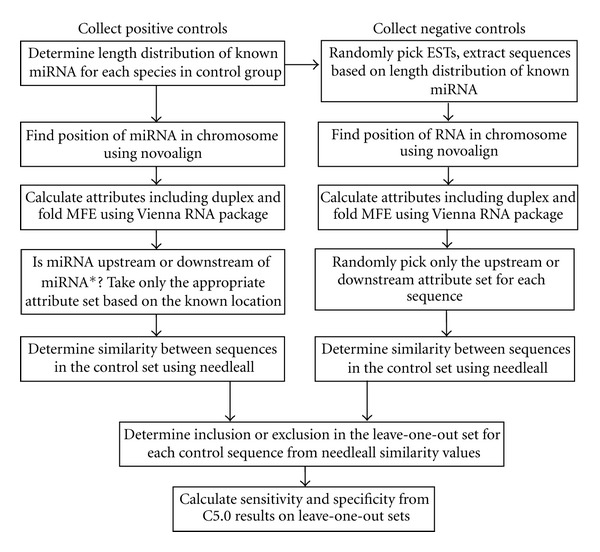
Data processing flow chart for collection of controls, training, and statistical validation. Known miRNAs from miRBase are used as positive controls. Negative controls are randomly picked short segments from ESTs based on the quantity and length distribution of known miRNAs from each plant species in the test set. All controls are aligned to their respective genome. Alignment location allows collection of attributes. For positive controls, the alignment position also allows the location of the miRNA in relation to upstream or downstream of miRNA* to be determined within the precursor. Only attributes from the correct location are valid for training positive controls. Upstream or downstream attributes are equally valid for negative controls, therefore only one is selected at random. Positive controls were aligned using needleall to determine the similarity between all miRNAs. Negative controls were also aligned. The similarity values from the alignment were used to determine if other highly similar sequences should also be excluded when the one in the leave-one-out set was excluded from training. Each sequence in a leave-one-out set was tested for correct classification by the model just trained using controls in the inclusion set. Counts of correct and incorrect classification were used to calculate sensitivity and specificity.