

Abstract
New advances in nano sciences open the door for scientists to study biological processes on a microscopic molecule-by-molecule basis. Recent single-molecule biophysical experiments on enzyme systems, in particular, reveal that enzyme molecules behave fundamentally differently from what classical model predicts. A stochastic network model was previously proposed to explain the experimental discovery. This paper conducts detailed theoretical and data analyses of the stochastic network model, focusing on the correlation structure of the successive reaction times of a single enzyme molecule. We investigate the correlation of experimental fluorescence intensity and the correlation of enzymatic reaction times, and examine the role of substrate concentration in enzymatic reactions. Our study shows that the stochastic network model is capable of explaining the experimental data in depth.
Key words and phrases: Autocorrelation, continuous time Markov chain, fluorescence intensity, Michaelis-Menten model, stochastic network model, single-molecule experiment, turnover time
1 Introduction
In a chemical reaction, the number of molecules involved can drastically vary from millions of moles — a forest devastated by a fire — to only a few — reactions in a living cell. While most conventional chemical experiments were designed for a large ensemble in which only average could be observed, chemistry textbooks tend to explain what really happens in a reaction on a molecule-by-molecule basis. This extrapolation certainly requires the homogeneity assumption: each molecule behaves in the same way, so average also represents individual behavior. To verify this assumption, the kinetic of a single molecule must be directly observed, which requires rather sophisticated technology not available until the 1990s. Since then, the development of nanotechnology has enabled scientists to track and manipulate molecules one by one. A new age of single-molecule experiments began (Nie and Zare 1997; Xie and Trautman 1998; Xie and Lu 1999; Tamarat et al. 2000; Weiss 2000; Moerner 2002; Flomenbom et al. 2005; Kou, Xie and Liu 2005b; Kou 2009).
Such experiments offer greatly amplified view of single-molecular dynamics over considerably long time periods from seconds to hours, a time scale that far exceeds what can be achieved by computer based molecular dynamic simulation (even with a super computer, molecular dynamic simulation cannot reach beyond milliseconds). The single-molecule experiments also provide detailed information on the intermediate transition steps of a biological process not available in traditional experiments. Not surprisingly, these experiments reveal the stochastic nature of nanoscale particles long masked by ensemble averages: rather than remain rigid, those particles undergo dramatic conformation change driven by external thermal motion. Future development in this area will provide us a deeper understanding of biological processes (such as molecular motors, Asbury, Fehr and Block, 2003) and accelerate new technology development (such as single-molecule gene sequencing, Pushkarev, Neff, and Quake, 2009).
Among bio-molecules, enzymes play an important role: by lowering the energy barrier between the reactant and product, they ensure that many life essential processes can be effectively carried out in a living cell. An aspiration of bioengineers is to artificially design and produce new and efficient enzymes for specific use. Studying and understanding the mechanism of existing enzymes, therefore, remains one of the central topics in life science. According to the classical literature, the kinetic of an enzyme is described by the Michaelis-Menten mechanism (Atkins and de Paula, 2002): an enzyme molecule E could bind with a reactant molecule S, which is referred to as a substrate in the chemistry literature (hence the symbol S), to form a complex ES. The complex can either dissociate to enzyme and substrate molecules or undergo a catalytic process to release the product P. The enzyme then returns to the original state E to start another catalytic circle. This process is typically diagrammed as
| (1.1) |
where [S] is the substrate concentration (E0 is the release state of the enzyme), k1 is the association rate per unit substrate concentration, k−1 and k2 are, respectively, the dissociation and catalytic rate, and δ is the returning rate. All the transitions are memoryless in the Michaelis-Menten scheme, so the whole process can be modeled as a continuous-time Markov chain consisting of three states E, ES and E0 for an enzyme molecule.
A recent single-molecule experiment (English et al. 2006) conducted by the Xie group at Harvard University (Department of Chemistry and Chemical Biology) studied the enzyme β-galactosidase (β-gal), which catalyzes the breakdown of the sugar lactose and is essential in the human body (Jacobson et al. 1994, Dorland 2003). In the experiment a single β-gal molecule is immobilized (by linking to a bead bound on a glass coverslip) and immersed in buffer solution of the substrate molecules. This setup allows β-gal’s enzymatic action to be continuously monitored under a fluorescence microscope. To detect the individual turnovers, i.e., the enzyme’s switching from the E state to the E0 state, careful design and special treatment were carried out (such as the use of photogenic substrate resorun-β-D-galactopyranoside) so that once the experimental system was placed under a laser beam the reaction product and only the reaction product was fluorescent. This setting ensures that as the β-gal enzyme catalyzes substrate molecules one after another, strong fluorescence signal is emitted and detected only when a product is released, i.e., only when the reaction reaches the E0 + P stage in (1.1). Recording the fluorescence intensity over time thus enables the experimental determination of individual turnovers. A sample fluorescence intensity trajectory from this experiment is shown in Figure 1. High spikes in the trajectory are the results of intense photon burst at the E0 + P state, while low readings correspond to the E or ES state. The time lag between two adjacent high fluorescence spikes is the enzymatic turnover time, i.e., the time to complete a catalytic circle.
Figure 1.
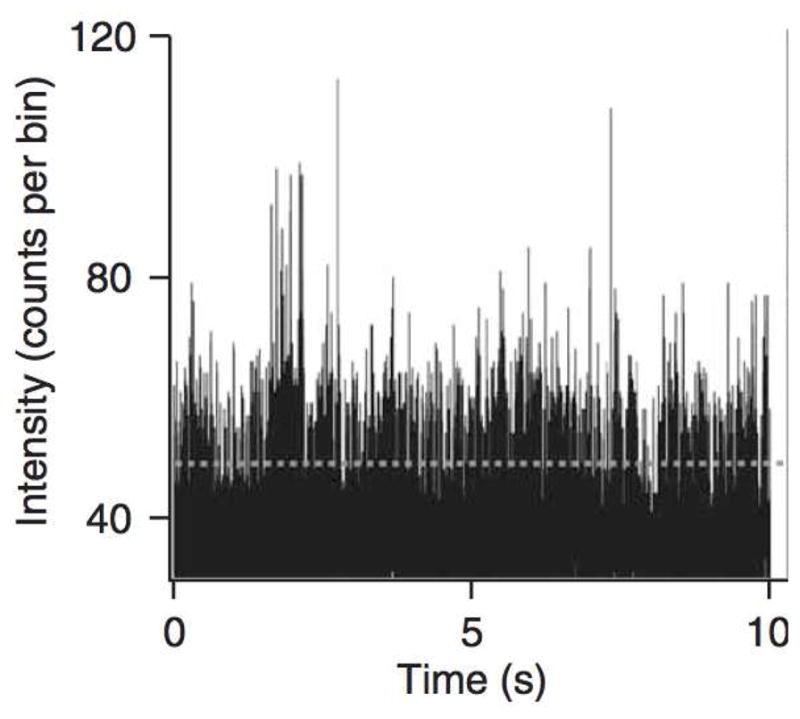
Fluorescence intensity reading from one experiment (the substrate concentration is 100 micro-molar). Each fluorescence intensity spike is caused by the release of a reaction product.
Examining the experimental data, including the distribution and autocorrelation of the turnover times as well as the fluorescence intensity autocorrelation, researchers were surprised that the experimental data showed a considerable departure from the Michaelis-Menten mechanism. Section 2 describes the experimental findings in detail. Figure 2 illustrates the discrepancy between the experimental data and the Michaelis-Menten model in terms of the autocorrelations. The left two panels show the experimentally observed fluorescence intensity autocorrelation and turnover time autocorrelation under different substrate concentrations [S]. The right two panels show the corresponding autocorrelation patterns predicted by the Michaelis-Menten model. Comparing the bottom two panels, we note that under the classical Michaelis-Menten model the turnover time autocorrelation should be zero (hence the horizontal line at the bottom-right panel), which clearly contradicts the experimental result on the left. From the top two panels we note that under the Michaelis-Menten model the fluorescence intensity autocorrelation should decay exponentially and should decay faster with larger substrate concentration, but the experiemental result shows the opposite: the intensity autocorrelations decay slower with larger substrate concentration, and they do not decay exponentially.
Figure 2.

Left column: Experimentally observed fluorescence intensity and turnover time autocorrelations under different substrate concentrations [S] (20, 100 and 380 micromolar). Right column: The autocorrelations predicted by the classical Michaelis-Menten model. Under the Michaelis-Menten model, the turnover time autocorrelation should be zero and the intensity autocorrelations should decay exponentially and decay faster under larger concentration. All contradict the experimental findings.
To explain the experimental puzzle, a new stochastic network model was introduced (Kou et al. 2005a, Kou 2008b), and it was shown that the stochastic network model well explained the experimental distribution of the turnover times. The autocorrelation of successive turnover times and the correlation of experimental fluorescence intensity, however, were not investigated in the previous articles.
This paper further explores the stochastic network model, concentrating on the correlation structure of the turnover times and that of the fluorescence intensity. The rest of the paper is organized as follows. Section 2 reviews the preceding work, including the experiment observation and the new stochastic network model. Section 3 analytically calculates the turnover time autocorrelation and the fluorescence intensity autocorrelation based on the stochastic network model. These analytical results give an explanation of the multi-exponentially decay pattern of the autocorrelation functions. Section 4 discusses how to fit the experiment data within the framework of the stochastic network model. The paper ends in Section 5 with a summary and some concluding remarks.
2 Modeling enzymatic reaction
2.1 The classical model and its challenge
Under the classical Michaelis-Menten model (1.1), an enzyme molecule behaves as a three-state continuous-time Markov chain with the generating matrix (infinitesimal generator)
We can readily draw two properties from this continuous-time Markov chain model.
Proposition 2.1
The density function of the turnover time, the time that it takes the enzyme to complete one catalytic cycle (i.e., to go from state E to state E0), is
where and q = (k1[S] + k2 + k−1)/2.
Proposition 2.2
The successive turnover times have no correlation.
The first proposition implies that the density of turnover time is almost an exponential, since the term e−(q−p)t easily dominates the term e−(q+p)t for most values of t; see Kou (2008b) for a proof. The second proposition is a consequence of the Markov property: each turnover time, which is a first passage time, is independently and identically distributed.
The third property concerns the autocorrelation of the fluorescence intensity. As we have seen in Figure 1, the experimentally recorded fluorescence intensity consists of high spikes and low readings. The high peaks correspond to the release of the fluorescent product (when the enzyme is at the state E0), whereas the low readings come from the background noise. We can thus think of the fluorescence intensity reading as a record of an on-off system: E0 being the on state, E and ES being the off states.
Proposition 2.3
The autocorrelation function of the fluorescence intensity is proportional to exp(−t(k−1 + k2 + k1[S])).
The proof of the proposition will be given in Corollary 3.11. This proposition says that under the Michaelis-Menten model the intensity autocorrelation decays exponentially and faster with larger substrate concentration [S].
The results from single-molecule experiment on β-gal (English et al. 2006) contradict all three properties of the Michaelis-Menten model:
The empirical distribution of the turnover time does not exhibit exponential decay; see Kou (2008b) for detailed explanation.
The experimental turnover time autocorrelations are far from zero, as seen in Figure 2.
The experimental intensity autocorrelations decay neither exponentially nor faster under larger concentration. See Figure 2.
2.2 A stochastic network model
We believe these contradictions are rooted in the molecule’s dynamic conformational fluctuation. An enzyme molecule is not rigid: it experiences constant changes and fluctuations in its three-dimensional shape and configuration due to the entropic and atomic forces at the nano scale (Kou and Xie, 2004; Kou 2008a). Although for a large ensemble of molecules, the (nanoscale) conformational fluctuation is buried in the macroscopic population average, for a single molecule the conformational fluctuation can be much more pronounced: different conformations could have different chemical properties, resulting in time-varying performance of the enzyme, which can be studied in the single-molecule experiment. The following stochastic network model (Kou et al. 2005a) was developed with this idea:
| (2.1) |
This is still a Markov chain model but with 3n states instead of three. The enzyme still exists as a free enzyme E, an enzyme-substrate complex ES, or a returning enzyme E0, but it can take n different conformations indexed by subscripts in each stage. At each transition, the enzyme can either change its conformation within the same stage (such as Ei → Ej or ESi → ESj) or carry out one chemical step, i.e., move between the stages (such as Ei → ESi, ESi → Ei or ). Since only the product P is fluorescent in the experiment, in model (2.1) any states is an on-state, and the others are off-states. Consequently, the turnover time is the traverse time between any two on-states and .
To fully specify the model, we need to stipulate the transition rates. For i ≠ j, we use αij, βij and γij to denote, respectively, the transition rates of Ei → Ej, ESi → ESj, and . k1i[S], k−1i, k2i and δi are, respectively, the transition rates of Ei → ESi, ESi → Ei, and . Define QAA, QBB and QCC to be square matrices:
where αii = −Σj ≠ i αij, βii = −Σj ≠ i βij and γii = −Σj ≠ i γij. They correspond to transitions among the Ei states, among the ESi states, and among the states, respectively. Define diagonal matrices
| (2.2) |
They correspond to transitions between the different stages. The generating matrix of model (2.1) is then
| (2.3) |
Under this new model, the distribution of the turnover time, the correlation of turnover times and the correlation of the fluorescence intensity can be analyzed and compared with experimental data. This paper studies the autocorrelation of turnover time and the autocorrelation of fluorescence intensity.
3 Autocorrelation of turnover time and of fluorescence intensity
3.1 Dynamic equilibrium and stationary distribution
In the chemistry literature, the term “equilibrium” often refers to the state in which all the macroscopic quantities of a system are time-independent. For the microscopic system studied in single-molecule experiments, macroscopic quantities, however, are meaningless, and microscopic parameters never cease to fluctuate. Nonetheless, for a micro-system, one can talk about dynamic equilibrium in the sense that the distribution of the state quantities become time-independent, i.e., they reach the stationary distribution. The single-molecule enzyme experiment that we consider here falls into this category, since the enzymatic reactions happen quite fast. We cite the following lemma (Lemma 3.1 of Kou, 2008b), which gives the stationary distribution of the Markov chain (2.1):
Lemma 3.1
Let X(t) be the process evolving according to (2.1). Suppose all the parameters k1i, k−1i, k2i, δi, αij, βij, and γij are positive. Then X(t) is ergodic. Let the row vectors πA = (π (E1), π (E2), …, π(En)), πB = (π (ES1), …, π (ESn)), and denote the stationary distribution of the entire network. Up to a normalizing constant, they are determined by
where the matrices
Under the stochastic network model (2.1), a turnover event can start from any state Ei and end in any . It follows that the overall distribution of all the turnover times is characterized by a mixture distribution with the weights given by the stationary probability of a turnover event’s starting from Ei. The following lemma, based on Lemma 3.4 of Kou (2008b), provides the stationary probability.
Lemma 3.2
Let w be a row vector, w = (w(E1), w(E2), · · · w(En)), where w(Ei) denotes the stationary probability of a turnover event’s starting from state Ei. Then up to a normalizing constant, w is the nonzero solution of
| (3.1) |
3.2 Autocorrelation of turnover time
Expectation of turnover time
The enzyme turnover event occurs one after another. Each can start from any Ei and end in any . The next turnover may start from Ek (k ≠ j) when the system exits the E0 stage from . To calculate the correlation between turnover times, it is necessary to find out the probabilities of all these combinations and the expected turnover times. We introduce the following notations.
Let TEi and TESi denote the first passage time of reaching the set { } from Ei and ESi, respectively. Let and be the probability that a turnover event, starting respectively from Ei and ESi, ends in . Let denote the probability that, after the previous turnover ends in , a new turnover event starts from Ej. Finally, let and be the first passage time of reaching the state from Ei and ESi respectively.
For the values of E(TEi) and E(TESi), we cite the following lemma (Corollary 3.3 of Kou, 2008b).
Lemma 3.3
Let the vectors μA = (E(TE1), E(TE2), …, E(TEn))T and μB = (E(TES1), …, E(TESn))T denote the mean first passage times. Then they are given by
| (3.2) |
where the matrices N and R are given by
For the probabilities and , we have the following lemma:
Lemma 3.4
Let PAC, PBC and PCA be probability matrices and . Then they are given by
| (3.3) |
For the expectation of and , we have
Lemma 3.5
Let and be two n × n matrices. Then they are given by
We defer the proofs of Lemmas 3.4 and 3.5 to the Appendix.
Correlation of the turnover times
Let Ti denote the ith turnover time. The next theorem, based on Lemmas 3.1 to 3.5, obtains the autocorrelation of the successive turnover times. We defer its proof to the Appendix.
Theorem 3.6
The covariance between the first turnover and the mth turnover (m > 1) is given by
where .
The matrix PACPCA is the product of two transition-probability matrices, so it is a stochastic matrix. Given that all the states in the stochastic network model communicate with each other, PACPCA is also irreducible, and all its entries are positive. According to the Perron-Frobenius theorem (Horn and Johnson, 1985), such matrix has eigenvalue one with simplicity one, and the absolute values of the other eigenvalues are strictly less than one. We therefore obtain the following corollary of Theorem 3.6.
Corollary 3.7
Suppose that PACPCA is diagonalizable:
where the diagonal matrix λ = diag(1, γ2, · · ·, γn) consists of the eigenvalues of PACPCA with |λi| < 1; the columns, 1, ϕ2, · · ·, ϕn, of matrix U are the corresponding right eigenvectors; and the rows, w, ψ2, · · ·, ψn, of U−1 are the corresponding left eigenvectors. Then we have
| (3.4) |
where .
Although the matrix PACPCA may have complex eigenvalues, these complex eigenvalues and corresponding eigenvectors always appear as conjugate pairs so that the imaginary parts in equation (3.4) cancel each other. As a result, we could treat all λi and σi as if they were real numbers.
Theorem 3.6, along with Corollary 3.7, provides an explanation of why the correlation of turnover times is not zero. At first sight, it seems to contradict the memoryless property of a Markov chain. What actually happens is that the state must be explicitly specified for the memoryless property to hold (i.e., one needs to exactly specify whether an enzyme is at state E1 or E2), whereas in the single-molecule experiment we only know whether the system is in an ‘on’ or ‘off’ state (for example, one only knows that the enzyme is in one of the on-states ). When there are multiple states, this aggregation effect leads to incomplete information that prevents the independence between successive turnovers; consequently, each turnover time carries some information about its reaction path, which is correlated with the reaction path of the next turnover, resulting in the correlation between successive turnover times.
Corollary 3.7 also states that since |λi| < 1, the autocorrelation is a mixture of exponential decays. Thus, depending on the relative scales of the eigenvalues, the actually decay might be single-exponential when one eigenvalue dominates the others or multi-exponential when several major eigenvalues jointly contribute to the decay.
Fast Enzyme Reset
In most enzymatic reactions, including the one we study, the enzyme returns very quickly to restart a new cycle once the product is released (Segel 1975). Those enzymes are called fast-cycle-reset enzymes. To model this fact, we let δi (i = 1, 2 · · ·, n), the transition rate from to Ei, go to infinity. Then any enzyme in state will always return to state Ei instantly, and the related transition probability matrix PCA, defined in equation (3.3), becomes the identity matrix.
3.3 Autocorrelation of fluorescence intensity
Correlation of intensity as a function of time
In the single-enzyme experiments, the raw data are the time traces of fluorescence intensity, as shown in Figure 1. The time lag between two adjacent high fluorescence spikes gives the enzymatic turnover time. The fluorescence intensity reading, however, is subject to detection error: the error caused by the limited time resolution Δt of the detector. Starting from time 0, the detector will only record intensity data at multiples of Δt: 0, Δt, 2Δt, …, kΔt, …. The intensity reading at time kΔt is actually the total number of photons received during the period of ((k − 1) Δt, kΔt). Thus, the detection errors of turnover time is roughly Δt. When the successive reactions occur slowly, the average turnover time is much longer than Δt, and the error is negligible. But when the reactions happen very frequently, the average turnover time becomes comparable to Δt, and this error cannot be ignored. In fact, when the substrate concentration is high enough, the enzyme will reach the ‘on’ states so frequently that most of the intensity readings are very high, making it impossible to reliably determine the individual turnover times. Under this situation, it is necessary to directly study the behavior of the raw intensity reading.
There are two main sources of the photons generated in the experiment: the weak but perpetual background noise and the strong but short-lived burst. The number of photons received from two different sources can be modeled as two independent Poisson processes with different rates. We can use the following equation to represent I(t), the intensity recorded at time t,
| (3.5) |
where Nt(s) and represent the total number of photons received due to the burst and background noise, respectively, within a length s sub-interval of (t − Δt, t); Ton(t) is the total time that the enzyme system spends at the ‘on’ states (any ) within the time interval (t − Δt, t). Nt(s) and are independent Poisson processes with rates ν and ν0 respectively. With this representation, we have the following theorem, whose proof is deferred to the Appendix.
Theorem 3.8
The covariance of the fluorescence intensity is
| (3.6) |
where μi are the non-zero eigenvalues of the generating matrix Q defined in equation (2.3), and Ci are constants only depending on Q.
Since −Q is a semi-stable matrix (Horn and Johnson 1985), it follows that the real parts of all μk (k > 1) are negative. For a real matrix, the complex eigenvalues along with their eigenvectors always appear in conjugate pairs; thus, the imaginary parts cancel each other in (3.6) and only the real parts are left. Therefore, we known according to Theorem 3.8 that the covariance of intensity will decay multi-exponentially.
Fast enzyme reset and intensity autocorrelation
A fast-cycle-reset enzyme jumps from state to Ei with little delay. A short burst of photons is released during the enzyme’s short stay at . For fast-cycle-reset enzymes, the behavior of the whole system can be well approximated by an alternative system, where only states Ei and ESi (i ∈ 1, 2, · · ·, n) exist: the transition rates among the E’s, among the ES’s, and from Ei to ESi are exactly the same as in the original system, but the transition rate from ESi to Ei is changed from k−1i to k−1i + k2i, since once a transition of occurs, the enzyme quickly moves to Ei. We can thus think of lumping and Ei together to form the alternative system, which has generating matrix
| (3.7) |
K is also a negative semi-stable matrix with 2n eigenvalues, one of which is zero. The following theorem details how well the eigenvalues of K approximate those of Q.
Theorem 3.9
Assume QCA = δdiag{q1, · · ·, qn}, where q1, · · ·, qn are fixed constants, while δ is large. Let κi (i = 2, 3, · · ·, 2n) denote the non-zero eigenvalues of K, then for each κi, there exists an eigenvalue μi of Q such that
The rest n eigenvalues of Q satisfy
The proof is deferred to the Appendix. This theorem says that for fast-cycle-reset enzymes with large δ, the first 2n − 1 non-zero eigenvalues of Q can be approximated by the eigenvalues of K, while the other n eigenvalues μ2n+1, …, μ3n of Q are of the same order of δ. Since all the eigenvalues have negative real parts, according to equation (3.6), the terms associated with μ2n+1, …, μ3n decay much faster so their contribution can be ignored. Thus, we have the following results for the intensity autocorrelation.
Corollary 3.10
For fast-cycle-reset enzymes (δ → ∞),
where κi are the non-zero eigenvalues of matrix K defined in equation (3.7).
Corollary 3.11
For the classic Michaelis-Menten model, where n = 1,
The only non-zero eigenvalue is −(k−1 + k2 + k1[S]). We thus have, for fast-cycle-reset enzymes,
4 From theory to data
We have shown in the preceding sections that the autocorrelation of turnover times and the correlation of intensity follow
Before applying these equations to fit the experimental data, the following problems must be addressed. First, we know so far that the decay patterns must be multi-exponential, but we do not yet know how the eigenvalues are related to the rate constants (k1i, k−1i, k2i, etc.) and the substrate concentration [S], which is the only adjustable parameter in the experiment. Second, we do not know the expressions of the coefficients (σi and Ci). Third, we do not know the number of distinct conformations n. We only know that it must be large: each enzyme consists of hundreds of vibrating atoms, and as a whole, it expands and rotates in the 3-dimensional space within the constraint of chemical bonds. We next address these questions before fitting the experimental data.
4.1 Eigenvalues as functions of rate constants and substrate concentration
In the enzyme experiments, the transition rates are intrinsic properties of the enzyme and the enzyme-substrate complex; they are not subject to experimental control. The only variable subject to experimental control is the concentration of the substrate molecules [S]. The higher the concentration, the more likely that the enzyme molecule could bind with a substrate molecule to form a complex. This is why the association rate k1i[S] (the rate of Ei → ESi) is proportional to the concentration. The experiments were repeated under different concentrations, resulting in different decay patterns of the autocorrelation functions as in Figure 2. A successful theory should be able to explain the relationship between concentration and autocorrelation decay pattern.
The concentration only affect the transition rates between Ei and ESi, which are denoted by QAB in equation (2.2). Define Q̃AB = diag{k1i, k2i, · · ·, kni}, which is independent of [S]; then QAB = [S]Q̃AB.
Four scenarios for simplication
To delineate the relationship between [S] and the autocorrelation decay pattern, we next simplify the generating matrices. Below are four scenarios that we will consider. Each of the scenarios guarantees the classical Michaelis-Menten equation, a hyperbolic relationship between the reaction rate and the substrate concentration,
| (4.1) |
which was observed in both the traditional and single-molecule enzyme experiments (see Kou et al. 2005a, English et al. 2006, and Kou 2008b for detailed discussion). Each scenario has its own biochemical implications.
Scenario 1. There are no or negligible transitions among the Ei states, that is αij → 0 for i ≠ j.
-
Scenario 2. There are no or negligible transitions among the ESi states, that is βij → 0 for i ≠ j.
Scenarios 1 and 2 correspond to the so-called slow fluctuating enzymes (whose conformation fluctuates slowly over time).
Scenario 3. The transitions among the Ei states are much faster than the others; that is, QAA = τQ̃AA and the scale τ ≫ 1 is much larger than other transition rates.
-
Scenario 4. The transitions among the ESi states are much faster than the others; that is, QBB = τQ̃BB and the scale τ ≫ 1 is much larger than other transition rates.
Scenarios 3 and 4 correspond to the so-called fast fluctuating enzymes (whose conformations fluctuate fast).
Remark
In the previous work (Kou 2008b), there are two other scenarios, which can also give rise to the hyperbolic relationship (4.1): primitive enzymes, whose dissociate rate is much larger than their catalytic rate (Albery and Knowles 1976; Min et al. 2006; Min et al. 2005a), and conformational-equilibrium enzymes, whose energy-barrier difference between dissociation and catalysis is invariant across conformations (Min et al. 2006). But our analysis based on those two scenarios does not lead to any meaningful conclusion, so we omit them here.
The effect of concentration on turnover time autocorrelation
Based on the four scenarios, we have the following theorem for autocorrelation of turnover times.
Theorem 4.1
For enzymes with fast cycle reset, the transition probability matrix governing the autocorrelation of turnover times is
Its eigenvalues λi, under the four different scenarios, satisfy:
Scenario 1. λi do not depend on [S], the substrate concentration. Thus, the autocorrelation decay should be similar for all concentrations.
-
Scenario 2. λi depend on [S] hyperbolically. More precisely, if we use λi([S]) (i = 1, 2, …, n) to emphasize the dependence of the eigenvalues on [S], we have
Thus the autocorrelation decay should be slower under larger concentration.
Scenario 3 or Scenario 4. The non-one eigenvalues are of order τ−1, so the autocorrelation should decay extremely fast for all concentrations.
This theorem tells us that for fast fluctuation enzymes (Scenario 3 or 4), the turnover time correlation tends to be zero. Intuitively, this is because the fast fluctuation enzymes prefer conformation fluctuation rather than going through the binding-association-catalytic path that leads to the product, so in a single turnover event, the enzyme undergoes intensive conformation changes, which effectively blurs the information on the reaction path carried by the turnover time, resulting in zero correlation. Under Scenario 1, the autocorrelation decay pattern does not vary when the concentration changes. This is because when the enzyme does not fluctuate, it goes from Ei to ESi directly, and the change of concentration consequently does not alter the distribution of reaction path. Thus, the correlation between turnover times does not depend on the concentration.
The result from Scenario 1, 3 or 4 contradicts the experimental finding: correlation exists between the turnover time and is stronger under higher concentration (see Figure 2). Only Scenario 2 fully agrees with the experiments, suggesting that the enzyme-substrate complex (ESi) does not fluctuate much. This is supported by recent single-molecule experimental findings (Lu et al. 1998; Yang et al. 2003; Min et al. 2005b), where slow conformational fluctuation in the enzyme-substrate complexes were observed.
The effect of concentration on fluorescence intensity autocorrelation
We now consider the intensity autocorrelation under each of the four scenarios. We write QAA = Iα + Jα, where Iα = diag{α11, · · ·, αnn}, and QBB = Iβ + Jβ, where Iβ = diag{β11, · · ·, βnn}. For Scenarios 1 and 2, we assume that both the enzyme and the enzyme-substrate complex fluctuate slowly: αij and βij (i ≠ j) are negligible but the sums αii = −Σj ≠ i αij and βii = −Σj ≠ i βij are not. Furthermore, we assume that in Scenario 1 the enzyme fluctuation is much slower than the enzyme-substrate complex fluctuation (so QAA = 0 and QBB = Iβ in Scenario 1), and in Scenario 2 the enzyme-substrate complex fluctuation is much slower (so QBB = 0 and QAA = Iα Scenario 2).
Theorem 4.2
For enzymes with fast cycle reset, the matrix governing the intensity autocorrelation is K. Its eigenvalues and the autocorrelation decay, under the four different scenarios, satisfy:
- Scenario 1 (QAA = 0 and QBB = Iβ). The autocorrelation decay is slower under lower concentration, and the dominating eigenvalues are given by
- Scenario 2 (QBB = 0 and QAA = Iα). The autocorrelation decay is faster under lower concentration, and the dominating eigenvalues are given by
Scenario 3.The autocorrelation decay does not depend on the concentration.
Scenario 4. The autocorrelation decay is slower under lower concentration.
The proof of the theorem is given in the Appendix. Our results of the dependence of turnover time autocorrelation and fluorescence intensity autocorrelation on the substrate concentration show that in order to have slower decay under higher substrate concentration (as seen in Figure 2), fluctuation of both the enzyme and the enzyme-substrate complex cannot be fast; furthermore, the fluctuation of the enzyme-substrate complex needs to be slower than the fluctuation of the enzyme.
In summary, each of the four scenarios yields different autocorrelation pattern, but only the one under Scenario 2 matches the experimental finding. Therefore, we will focus on Scenario 2 from now on.
4.2 Continuous limit
To simplify the coefficients σi and Ci and to address the number of distinct conformations n, we adopt the idea in the previous work (Kou et al. 2005a, Kou 2008b) by utilizing a continuous limit. First, we let n → ∞ and in this way model the transition rates as continuous variables with certain distributions. Consequently, we treat the eigenvalues also as continuous variables. Second, we assume that all the coefficients (σi and Ci) are proportional to the probability weight of the conjugate eigenvalues. This assumption is partly based on the fact that all the observed experimental correlation are positive. With these two assumptions, the covariance can be represented by
where f and g are the corresponding distribution functions.
λ and κ are functions of the transition rates. Since the transition rates are always positive, a natural choice is to model the transition rates as either constants or following Gamma distributions. In the previous work (Kou, 2008b) on the stochastic network model, the association rate k1 and dissociation rate k−1 are modeled as constants while the catalytic rate k2 follows a Gamma distribution Γ(a, b). We adopt them in our fitting.
We know from Section 4.1 that Scenario 2 matches the experimental finding, so we take QBB = 0 and QAA = Iα. Then the eigenvalue λ (based on Theorem 4.1 and its proof in the Appendix) is given by
| (4.2) |
and the eigenvalue κ (based on Theorem 4.2) is
| (4.3) |
where α* stands for a generic −αii (since we are taking the continuous version). For the distribution of α* (i.e., the distribution of −αii), we note that first, its support should be the positive real line, and second, −αii = Σj ≠ i αij is a sum of many random variables αij from a common distribution, so we expect that the distribution of α* should be infinitely divisible. These two considerations lead us to assume a Gamma distribution Γ(aα, bα) for α*.
4.3 Data fitting
The data available to us include the intensity correlation under three concentrations: [S] = 380, 100 and 20 μM (micro molar), and turnover time autocorrelation under two concentrations [S] = 100 and 20 μM. We calculated eigenvalues based on equations (4.2) and (4.3), where k1 and k−1 are constants, α* and k2 follow distributions Γ(aα, bα) and Γ(a, b), respectively. The parameters of interests are k1, k−1, a, b, aαand bα. The best fits are found through minimizing the square distance between the theoretical and observed values. The parameters are estimated as: k1 = 1.785 × 103(μM)−1s−1, k−1 = 6.170 × 103s−1, a = 13.49, b = 2.279s−1, aα = 0.6489, and bα = 1.461 × 103s−1 (s stands for second). Figures 3 shows the fitting of the autocorrelation functions and the distributions of the eigenvalues.
Figure 3.

Left: Data fitting to the intensity and turnover time autocorrelations based on equations (4.2) and (4.3). Right: The corresponding distributions of the eigenvalues λ and κ.
Figure 3 shows that our model gives a good fit to the turnover time autocorrelation and an adequate fit to the fluorescence intensity autocorrelation, capturing the main trend in the intensity autocorrelation. The distributions of the eigenvalues in the right panels clearly indicate that higher substrate concentration corresponds to larger eigenvalues, which are then responsible for the slower decay of the autocorrelations.
Our model thus offers an adequate explanation of the observed decay patterns of the autocorrelation functions. The stochastic network model tells us why the decay must be multi-exponential. It further explains why the decay is slower under higher substrate concentration. Our consideration of the different scenarios also provides insight on the enzyme’s conformational fluctuation: slow fluctuation, particularly of the enzyme-substrate complex, gives rise to the experimentally observed autocorrelation decay pattern.
5 Discussion
In this article we explored the stochastic network model previously developed to account for the empirical puzzles arising from recent single-molecule enzyme experiments. We conducted a detailed study of the autocorrelation function of the turnover time and of the fluorescence intensity and investigate the effect of substrate concentration on the correlations.
Our analytical results show that (a) the stochastic network model gives multi-exponential autocorrelation decay of both the turnover times and the fluorescence intensity, agreeing with the experimental observation; (b) under suitable conditions, the autocorrelation decays more slowly with higher concentration, also agreeing with the experimental result; (c) the slower autocorrelation decay under higher concentration implies that the fluctuation of the enzyme-substrate complex should be slow, corroborating the conclusion from other single-molecule experiments (Lu et al. 1998; Yang et al. 2003; Min et al. 2005b). In addition to providing a theoretical underpinning of the experimental observations, the numerical result from the model fits well with the experimental autocorrelation as seen in Section 4.
Some problems remain open for future investigation:
When we discussed the dependence of intensity autocorrelation on substrate concentration in Section 4.1, we approximated the fluctuation transition matrix with its diagonal entries. This simple approximation provides useful insight into the decay pattern under different concentration. A better approximation that goes beyond the diagonal entries is desirable. It might lead to a better fitting to the experimental data.
We used Gamma distribution to model the transition rates. This is purely statistical. Can it be derived from a physical angle? If so, the connection not only will lead to better estimation, but also provides new insight into the underlying mechanism of enzyme’s conformation fluctuation.
We used the continuous limit n → ∞ to do the data fitting so that the number of parameters reduces from more than 3n to a manageable six. Obtaining the standard error for the estimates is open for future investigation. The main difficulties are the lack of tractable tools to approximate the standard error of the autocorrelation estimates and the challenge to carry out a Monte Carlo estimate (n needs to be quite large for an ad hoc Monte Carlo simulation, but such an n will bring back a large number of unspecified parameters).
Single-molecule biophysics, like many newly emerging fields, is interdisciplinary. It lies at the intersection of biology, chemistry and physics. Owing to the stochastic nature of the nano world, single-molecule biophysics also presents statisticians with new problems and new challenges. The stochastic model for single-enzyme reaction represents only one such case among many interesting opportunities. We hope this articles would generate further interests in solving biophysical problems with modern statistical methods; and we believe that the knowledge and tools gained in this process will in turn advance the development of statistics and probability.
Acknowledgments
The authors thank the Xie group at the Department of Chemistry and Chemical Biology of Harvard University for sharing the experimental data. This research was supported in part by the NSF grant DMS-0449204 and the NIH/NIGMS grant R01GM090202.
Appendix: Proofs
PROOF of Lemma 3.4
Using the first-step analysis, we have
where
Only the diagonal elements of G are negative, and its row sums are either 0 or negative. Thus, −G is a stable matrix (Horn and Johnson, 1985), which always has a inverse. Thus, we have:
For , similarly, we have
PROOF of Lemma 3.5
For , when the first-step analysis is applied, the first-step probability should be conditioned on the exit state , i.e. . Thus, we have the following equation
Similar expression can be derived for . Together we have
PROOF of Theorem 3.6
cov(T1, Tm) = E(T1Tm) − E(T1)E(Tm). The first term E(T1Tm) can be expressed as
that is, the system starts the first turnover event from Ei, ends it in , then starts the second from Ek, repeats this procedure for m − 2 times, and finally starts the last turnover from El. Note that . Thus, using the matrices defined in Lemmas 3.1 to 3.5, we have
Applying the results of Lemmas 3.4 and 3.5 and the facts that and , we can finally arrange the covariance as
PROOF of Corollary 3.7
We only need to prove that 1 and w are, respectively, the right and left eigenvectors of PACPCA associated with the eigenvalue 1. The first is a direct consequence of the fact that PACPCA is a stochastic matrix. The second can be verified by observing that through equation (3.1).
PROOF of Theorem 3.8
In equation (3.5), the second term represents the independent white noise during period (t − Δt, t). Thus,
Let be the set of all possible states. Let Xt be the process evolving according to (2.1). Let πi be the equilibrium probability of state i and Pij(s) be the transition probability from state i to state j after time s. We have
The probability transition matrix [Pij(t)]3n×3n is the matrix exponential of the generating matrix (2.1): [Pij(t)]3n×3n = exp(Qt). Zero is an eigenvalue of Q with right eigenvector 1 and left eigenvector π, the stationary distribution. Assume Q is diagonalizable. Let μi, i = 2, 3 · · ·, 3n, denote the other eigenvalues, and ξi and be the corresponding right and left eigenvectors. We have
Therefore, we can rewrite
To prove Theorem 3.9, we need the following two useful lemmas on the eigenvalues of a matrix.
Lemma A.1
(Theorems 6.1.1 and 6.4.1 of Horn and Johnson (1985)) Let A = [aij] ∈ Mn, where Mn is the set of all complex matrices. Let α ∈ [0, 1] be given and define and as the deleted row and column sums of A, respectively,
Then, (1) all the eigenvalues of A are located in the union of n discs
| (A.1) |
(2) Furthermore, if a union of k of these n discs forms a connected region that is disjoint from all the remaining n − k discs, then there are precisely k eigenvalues of A in this region.
Lemma A.2
(p 63–67, Wilkinson (1965)) Let A and B be matrices with elements satisfying |aij| < 1, |bij| < 1. If λ1 is a simple eigenvalue (i.e., an eigenvalue with multiplicity 1) of A, then for matrix A + εB, where ε is sufficiently small, there will be a eigenvalue λ1(ε) of A + εB such that
Furthermore, if we know that one eigenvector of A associated with λ1 is x1, then there is an eigenvector x1(ε) of A + εB associated with λ1(ε) such that
Note that since dividing a matrix by a constant only changes the eigenvalues with the same proportion, the condition that the entries of A and B are bounded by 1 can be relaxed to that the entries of A and B are bounded by a finite positive number.
PROOF of Theorem 3.9
According to Lemma A.1, all the eigenvalues of Q must lie in the union of discs centered at Qii with radii defined by (A.1). If we take α = 1/2 in (A.1), then the first n discs corresponding to the diagonal entries of QAA − QAB have centers O(1) and radii O(δ1/2); the second n discs corresponding to the diagonal entries of QBB − QBC − QBA have centers O(1) and radii O(1); the third n discs corresponding to the diagonal entries of QCC − QCA have centers O(δ) and radii O(δ1/2). Thus, for δ large enough, the union of the first 2n discs does not overlap with the union of the last n discs, so we know from Lemma A.1 that Q has 2n eigenvalues with order O(δ1/2) in the union of the first 2n discs and n other eigenvalues with order O(δ) in the union of the last n discs.
For the n eigenvalues with order O(δ), consider the following two matrices
We have . Zero is an eigenvalue of Y with multiplicity 2n, and the other n eigenvalues of Y are −q1, −q2, …, −qn. For large δ, according to Lemma A.2, there exists n eigenvalues of that satisfy
that is,
Now for the 2n − 1 non-zero eigenvalues of Q with order O(δ1/2), they are the solutions of
For large δ, the matrix QCC − QCA − μiIn is invertible, since it is strictly diagonal dominated. We can decompose the determinant as
where
Therefore, μi, i = 2, …, 2n, is also the eigenvalue of the matrix
with
We note that In +QBC(QCC − QCA − μiIn)−1QCA = (W − In)−1 W, where . Since QCA is of the order O(δ) and μi is of the order O(δ1/2), the entries of W are of the order O(δ−1/2), so are the entries of S. Applying Lemma A.2 to K+ S tells us that for each μi there must be a eigenvalue κi of K, which has the property that
PROOF of Theorem 4.1
We know from Lemma 3.1 that
Scenario 1. When QAA = 0, M = (QBB − QBC)−1, so the eigenvalues and eigenvectors of −MQBC have nothing to do with [S].
- Scenario 2. When QBB = 0, . Thus, if −MQBC has eigenvalue λi(1) when [S] = 1, then for general [S], −MQBC has eigenvalue
-
Scenario 3. We write QAA = τQ̃AA, where τ is large. Then −MQBC isSuppose the eigenvalues of are 0, . Then according to Lemma A.2, the eigenvalues of areThus, the eigenvalues of −MQBC are
namely, all the none-one eigenvalues of −MQBC are of order τ−1.
Scenario 4. Using identical method as in Scenario 3, we can show that all the none-one eigenvalues of −MQBC are of order τ−1.
PROOF of Theorem 4.2
The matrix K can be written as
We thus know from Lemma A.2 that the eigenvalues of K can be approximated by the eigenvalues of T. If |Iα − QAB − κIn| is invertable, then
we know that any eigenvalue κ of T must make the second determinant on the right hand side zero. This determinant only involves diagonal matrices, so we have
| (A.2) |
If |Iα − QAB − κIn| is not invertible, then there is at least one j so that κ = αjj − k1j[S]. But it can be verified that in order to make κ an eigenvalue of T, there must exit another i ≠ j such that (A.2) holds for this κ. Therefore, any eigenvalue must be a root of (A.2).
(A.2) has two negative roots for each i, but we only need to consider the root closer to 0, since it dominates the decay.
-
Scenario 1. αii = 0. The root is
which is monotone decreasing in [S].
-
Scenario 2. βii = 0. The root is
which is monotone increasing in [S].
Scenario 3. QAA = τQ̃AA, where τ is large. Following the same method as we used in the proof of Theorem 3.9, we can show that n eigenvalues of K are of the order O(τ) and they will not contribute much to the correlation. The other eigenvalues governing the decay pattern can be approximated by the eigenvalues of QBB − QBA − QBC, which do not depend on the concentration [S].
Scenario 4. QBB = τQ̃BB, where τ is large. Using the same method as in the proof of Theorem 3.9, we can show that the dominating eigenvalues of K can be approximately by the eigenvalues of QAA − QAB. Since we know that QAA ≈ Iα, the eigenvalues of QAA − QAB is approximately αii − [S]k1i, which is monotone decreasing in [S].
References
- 1.Albery WJ, Knowles JR. Free-energy profile for the reaction catalyzed by triosephosphate isomerase. Biochemistry. 1976;15:5627–5631. doi: 10.1021/bi00670a031. [DOI] [PubMed] [Google Scholar]
- 2.Asbury C, Fehr A, Block SM. Kinesin moves by an asymmetric hand-over-hand mechanism. Science. 2003;302:2130–2134. doi: 10.1126/science.1092985. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Atkins P, de Paula J. Physical Chemistry. 7. W. H. Freeman; New York: 2002. [Google Scholar]
- 4.Dorland WA. Dorland’s Illustrated Medical Dictionary. 30. W. B. Sauders; Philadelphia: 2003. [Google Scholar]
- 5.English B, Min W, van Oijen AM, Lee KT, Luo G, Sun H, Cherayil BJ, Kou SC, Xie XS. Ever-fluctuating single enzyme molecules: Michaelis-Menten equation revisited. Nature Chem Biol. 2006;2:87–94. doi: 10.1038/nchembio759. [DOI] [PubMed] [Google Scholar]
- 6.Flomembom O, et al. Stretched exponential decay and correlations in the catalytic activity of fluctuating single lipase molecules. Proc Natl Acad Sci. 2005;102:2368–2372. doi: 10.1073/pnas.0409039102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Horn R, Johnson C. Matrix analysis. Cambridge University Press; Cambridge: 1985. [Google Scholar]
- 8.Jacobson RH, Zhang XJ, DuBose RF, Matthews BW. Three-dimensional structure of β-galactosidase from e. coli. Nature. 1994;369:761–766. doi: 10.1038/369761a0. [DOI] [PubMed] [Google Scholar]
- 9.Kou SC. Stochastic modeling in nanoscale biophysics: subdiffusion within proteins. Annals of Applied Statistics. 2008a;2:501–535. [Google Scholar]
- 10.Kou SC. Stochastic networks in nanoscale biophysics: modeling enzymatic reaction of a single protein. J Amer Statist Assoc. 2008b;103:961–975. [Google Scholar]
- 11.Kou SC. A selective view of stochastic inference and modeling problems in nanoscale biophysics. Science in China, A. 2009;52:1181–1211. [Google Scholar]
- 12.Kou SC, Cherayil B, Min W, English B, Xie XS. Single-molecule Michaelis-Menten equations. J Phys Chem, B. 2005a;109:19068–19081. doi: 10.1021/jp051490q. [DOI] [PubMed] [Google Scholar]
- 13.Kou SC, Xie XS. Generalized Langevin equation with fractional Gaussian noise: subdiffusion within a single protein molecule. Phys Rev Lett. 2004;93:180603(1)–180603(4). doi: 10.1103/PhysRevLett.93.180603. [DOI] [PubMed] [Google Scholar]
- 14.Kou SC, Xie XS, Liu JS. Bayesian analysis of single-molecule experimental data (with discussion) J Roy Statist Soc, C. 2005b;54:469–506. [Google Scholar]
- 15.Lu HP, Xun L, Xie XS. Single-molecule enzymatic dynamics. Science. 1998;282:1877–1882. doi: 10.1126/science.282.5395.1877. [DOI] [PubMed] [Google Scholar]
- 16.Min W, English B, Luo G, Cherayil B, Kou SC, Xie XS. Fluctuating enzymes: lessons from single-molecule studies. Acc Chem Res. 2005a;38:923–931. doi: 10.1021/ar040133f. [DOI] [PubMed] [Google Scholar]
- 17.Min W, Luo G, Cherayil B, Kou SC, Xie XS. Observation of a power law memory kernel for fluctuations within a single protein molecule. Phys Rev Lett. 2005b;94:198302(1)–198302(4). doi: 10.1103/PhysRevLett.94.198302. [DOI] [PubMed] [Google Scholar]
- 18.Min W, Gopich IV, English B, Kou SC, Xie XS, Szabo A. When does the Michaelis-Menten equation hold for fluctuating enzymes? J Phys Chem, B. 2006;110:20093–20097. doi: 10.1021/jp065187g. [DOI] [PubMed] [Google Scholar]
- 19.Moerner W. A dozen years of single-molecule spectroscopy in physics, chemistry, and biophysics. J Phys Chem, B. 2002;106:910–927. [Google Scholar]
- 20.Nie S, Zare R. Optical detection of single molecules. Ann Rev Biophys Biomol Struct. 1997;26:567–596. doi: 10.1146/annurev.biophys.26.1.567. [DOI] [PubMed] [Google Scholar]
- 21.Pushkarev D, Neff N, Quake S. Single-molecule sequencing of an individual human genome. Nature Biotechnology. 2009;27:847–852. doi: 10.1038/nbt.1561. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Segel IH. Enzyme Kinetics: Behavior and Analysis of Rapid Equilibrium and Steady-State Enzyme Systems. Wiley; New York: 1975. [Google Scholar]
- 23.Tamarat P, Maali A, Lounis B, Orrit M. Ten years of single-molecule spectroscopy. J Phys Chem, A. 2000;104:1–16. doi: 10.1021/jp992505l. [DOI] [PubMed] [Google Scholar]
- 24.Weiss S. Measuring conformational dynamics of biomolecules by single molecule fluorescence spectroscopy. Nature Struct Biol. 2000;7:724–729. doi: 10.1038/78941. [DOI] [PubMed] [Google Scholar]
- 25.Wilkinson J. Monographs on numerical analysis. Clarendon Press; Oxford: 1965. The algebraic eigenvalue problem. [Google Scholar]
- 26.Xie XS, Lu HP. Single-molecule enzymology. J Bio Chem. 1999;274:15967–15970. doi: 10.1074/jbc.274.23.15967. [DOI] [PubMed] [Google Scholar]
- 27.Xie XS, Trautman JK. Optical studies of single molecules at room temperature. Ann Rev Phys Chem. 1998;49:441–480. doi: 10.1146/annurev.physchem.49.1.441. [DOI] [PubMed] [Google Scholar]
- 28.Yang H, Luo G, Karnchanaphanurach P, Louise TM, Rech I, Cova S, Xun L, Xie XS. Protein conformational dynamics probed by single-molecule electron transfer. Science. 2003;302:262–266. doi: 10.1126/science.1086911. [DOI] [PubMed] [Google Scholar]