

Abstract
We investigated the decoding of millisecond-order timing information in ocular dominance stimulation from the blood oxygen level dependent (BOLD) signal in human functional magnetic resonance imaging (fMRI). In our experiment, ocular dominance columns were activated by monocular visual stimulation with 500- or 100- ms onset differences. We observed that the event-related hemodynamic response (HDR) in the human visual cortex was sensitive to the subtle onset difference. The HDR shapes were related to the stimulus timings in various manners: the timing difference was represented in either the amplitude of positive peak, amplitude of negative peak, delay of peak time, or response duration of HDR. These complex relationships were different across voxels and subjects. To find an informative feature of HDR for discriminating the subtle timing difference of ocular dominance stimulations, we examined various characteristics of HDR including response amplitude, time to peak, full width at half-maximum response, as inputs for decoding analysis. Using a canonical HDR function for estimating the voxel’s response did not yield good decoding scores, suggesting that information may reside in the variability of HDR shapes. Using all the values from the deconvolved HDR also showed low performance, which could be due to an over-fitting problem with the large data dimensionality. When using either positive or negative peak amplitude of the deconvolved HDR, high decoding performance could be achieved for both the 500ms and the 100ms onset differences. The high accuracy even for the 100ms difference, given that the signal was sampled at a TR of 250 ms and 2×2×3-mm voxels, implies a possibility of spatiotemporally hyper-resolution decoding. Furthermore, both down-sampling and smoothing did not affect the decoding accuracies very much. These results suggest a complex spatiotemporal relationship between the multi-voxel pattern of the BOLD response and the population activation of neuronal columns. The demonstrated possibility of decoding a 100-ms difference of stimulations for columnar-level organization with lower resolution imaging data may broaden the scope of application of the BOLD fMRI.
Keywords: Multi-voxel pattern analysis, deconvolved hemodynamic response, hyper-spatiotemporal resolution, complex spatiotemporal filter voxel
1. Introduction
The temporal resolution of functional magnetic resonance imaging (fMRI) using the blood oxygen level dependent (BOLD) signal is restricted not only by sampling rate (Repetition Time [TR] of imaging) but also by the delay of hemodynamic response (HDR) as well as the tortuosity of vasculature. The HDR has a slow temporal profile taking 4–6 seconds to reach the response peak and more than 10 seconds to return to the initial baseline even for a short single event. Blood flow also affects the time course of HDR in a way irrelevant to neural activations, restricting the temporal resolution of the BOLD fMRI.
Despite its slow temporal profile, previous studies have shown that HDR is sensitive to subtle timing difference of stimulus presentations (Grinband et al., 2008; Hernandez et al., 2002; Menon et al., 1998a; Menon and Kim, 1999; Menon et al., 1998b; Ogawa et al., 2000; Robson et al., 1998; Tomatsu et al., 2008). Menon et al. (1998b), for example, found that the onset of the HDR exactly linked to the stimulus onset in the order of one hundred milliseconds. However, in the studies of resolving subsecond timing of HDR (Menon et al., 1998a; Menon and Kim, 1999; Menon et al., 1998b; Ogawa et al., 2000; Robson et al., 1998), an average HDR across multiple voxels was used to evaluate the temporal sensitivity of HDR due to limited signal-to-noise ratio.
Even if the signal-to-noise ratio is high, temporal properties of HDR can fluctuate on a voxel-wise basis depending on the vascular organization; particularly, the peak response time of HDR is known to be delayed at voxels downstream of blood flow near a large vein (de Zwart et al., 2005; Hirano et al., 2011; Lee et al., 1995). High temporal resolution property of BOLD signal, therefore, can be investigated when a stimulus or task can be assumed to elicit homogeneous neural activations in a region large enough for averaging to remove vascular bias and to achieve high signal-to-noise ratio. Otherwise, estimating subsecond information on neural activation from the HDR is very difficult.
In this study, we sought to overcome this limitation by utilizing the multi-voxel pattern analysis (MVPA); we used a ‘decoding’ approach with the MVPA to discriminate the subtle timing difference of visual stimulations. MVPA (Haynes and Rees, 2006; Norman et al., 2006) investigates a pattern activation of multiple voxels. This analysis does not concern a response at each voxel as an independent value but evaluates whether a multivariate pattern of multi-voxel response is sensitive to the difference of stimuli. This analysis can discriminate the columnar-level neural activations (orientation-selective responses in the human visual cortex) from the BOLD signal with 3-mm-sized voxels (Haynes and Rees, 2005; Kamitani and Tong, 2005). While the decoding with MVPA cannot identify the activation of each column within a voxel, it can discriminate the difference of pattern activations across voxels. The objective of the MVPA, therefore, is not to identify the neural activation in each voxel, but to evaluate information encoded in a neuronal population activation reflected in a multi-voxel pattern of HDR (Kriegeskorte and Bandettini, 2007).
The objective of this study is not to estimate timing of neural activation at each voxel with subsecond resolution. Instead, we aimed to discriminate the multi-voxel response patterns corresponding to a subsecond difference of visual stimulations. Even though it is difficult to estimate exact timing of neural activation in each voxel, we may at least be able to discriminate the difference of multi-voxel HDR patterns corresponding to timings of neural activations if they are linked to each other. The classification framework of MVPA is well suited for discriminating small difference because the multivariate analysis used in the MVPA often has higher sensitivity to detect a difference than a univariate analysis.
To examine the possibility of discriminating subsecond differences in columnar-level activation from the BOLD signal, we investigated ocular dominance activation in the human visual cortex. In the experiment, monocular visual stimulation was applied with timing offset of 500ms or 100ms between left and right eye. The decoding analysis was performed with MVPA to examine whether the subtle timing difference of ocular dominance activations could be decoded with high accuracy from the multi-voxel response patterns.
In this study, several hemodynamic response properties hypothetically informative for decoding were investigated. Three types of response models, the canonical HDR model, the canonical HDR with the first- and second-order Volterra expansion (Friston et al., 1998), and the deconvolution with the finite impulse response (FIR) model (Glover, 1999), were examined for extracting voxel-wise responses as input for the decoding analysis. For the deconvolved HDR, four response characteristics, positive peak amplitude, positive or negative peak amplitude, time to peak, and full width at half-maximum (FWHM) response was also examined. In addition, we examined the effects of spatial and temporal resolution of fMRI on the decoding performance.
2. Materials and Methods
2-1. Experimental procedures
Twelve subjects (22–41 years of age, 5 females) participated in the study and gave informed consent according to a protocol approved by the Institutional Review Board at the National Institutes of Health.
The subjects viewed a visual stimulus on the screen by means of a mirror mounted on the head RF coil. The visual stimulus was a radial checkerboard pattern, flashing at 6.7 Hz, back-projected onto a screen in the MRI bore, subtending 16.7° horizontally and 11.0° vertically in visual angle. The stimulus was presented for each eye by closing and opening LCD shutter goggles (PLATO Visual Occlusion Spectacles, Translucent Technologies Inc., Toronto, Canada) placed in front of subject’s eyes. The shutters for each eye were controlled via a laptop to open or close independently. The shutter was opened only when the stimulus was presented and was kept closed otherwise. The response time of the shutter was approximately 4 ms to open and 3 ms to close. For exact timing control, we used a custom experiment system built on a Linux computer with real-time extensions (RTAI; https://www.rtai.org/).
Fig. 1 shows the stimulus conditions applied in the experiment. Left and right monocular stimulations (Lmono and Rmono) were employed to validate that the analysis could discriminate activations of left and right ocular dominance columns. Binocular stimulation was employed to evaluate the possibility of discriminating subtle timing differences of ocular dominance activations. The term, LRbin, represents the conditions when both eyes were stimulated simultaneously. In L-R500 and R-L500, the left eye was stimulated 500 ms before the right eye and vice versa, respectively. To examine the discrimination of timing differences shorter than the sampling rate of BOLD signal, we also applied the conditions with 100-ms onset differences (L-R100 and R-L100). The time courses of these two latter conditions were the same as L-R500 and R-L500 except the onset interval was 100 ms. The 100-ms conditions were applied for six of the subjects.
Figure 1.
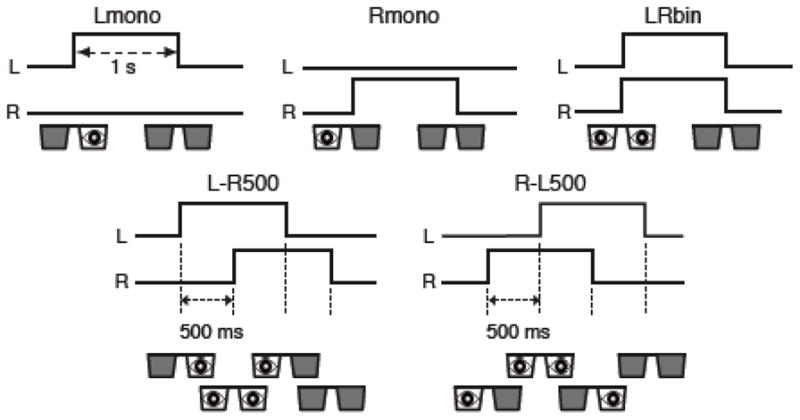
Schematic diagrams of stimulation protocol. Lines in each panel show the time course of the state of left and right LCD shutters (up is open). Visual stimulus was presented while either of the LCD shutter was opened.
A slow event-related design was employed in the experiment with 1-s stimulus duration. The inter-trial interval (ITI) was 16 s (15 s rest) for the six subjects and 12 s (11 s rest) for the other six subjects performing the 100-ms conditions. Four trials for each condition were performed in each run and eight runs were performed in each experimental session. The order of conditions was randomized and counter-balanced across runs; the probabilities of a subsequent condition were equalized for all conditions to avoid confounding effects from the order of conditions. Each functional run included an initial 12-s rest period to allow for MR equilibration.
A fixation task was used to maintain the subjects’ attention on the center of the stimulus. A small white fixation circle at the center of the stimulus was flashed green in random timing while the shutter was opened. Subjects were required to report the green flash by pressing a button. The fixation task was not correlated with the stimulus conditions because it was applied in every trial and the timing of fixation flash was not correlated with the onset difference of the stimulations.
2-2. MRI parameters
All imaging was performed on a 3T Signa MR scanner (GE Healthcare, Milwaukee, WI) with a 16-channel surface-coil array (NOVA Medical Inc., Wilmington, MA). The functional time series were obtained using single-shot gradient-recalled echo planar imaging (EPI) with parallel imaging using the Array Spatial Sensitivity Encoding Technique (ASSET). The imaging parameters were TR = 250 ms, TE = 30 ms, FA = 35°, FOV = 192 × 192 mm, 96 × 96 matrix, 4 slices of 3 mm thickness with 0.3 mm gap, voxel size of 2 × 2 × 3 mm, and ASSET acceleration factor = 2. Oblique Slices were prescribed to cover the primary visual cortex and parallel to the calcarine sulcus. The number of volumes in each run was 1252 for the six subjects and 1396 for the other six subjects performing the 100-ms conditions. Eight runs were performed in each experimental session.
For anatomical alignment, whole brain T1-weighted Magnetization Prepared Rapid Gradient Echo (MPRAGE) images were acquired for each subject with TR = 6 ms, TE = 2.736 ms, FA = 12, voxel size = 1 × 1 × 1 mm, and with ASSET (acceleration factor = 2).
2-3. Image processing
All images were processed using the AFNI processing package (Cox, 1996); http://afni.nimh.nih.gov/). The first 48 volumes before the first trial were excluded from the analysis. After extreme outliers in the time series were replaced with interpolation from neighborhood values using 3dDespike program, the images were corrected for slice-acquisition timing and realigned to the volume nearest to the anatomical scan. Signal values per voxel were scaled to percent signal change relative to the mean signal across the time course of each run. The high-contrast (TR = infinity) first image in the run nearest to the anatomical scan was also aligned with other functional images. Because of its high contrast, this image was used to align anatomical with functional images but not used for time-signal analysis.
To evaluate the effect of sampling rate on the decoding accuracies, we created down-sampled signal time courses. The signal time course was low-pass filtered using a Fourier filter with 1, 0.5, 0.25, and 0.125 Hz cut-off frequencies in each run, and were down sampled with 0.5-, 1-, 2-, and 4-s intervals, respectively. To evaluate the effect of spatial frequency of response patterns on the decoding accuracies, the functional images were smoothed with Gaussian kernels with FWHM = 2, 4, 6, and 8 mm.
Anatomical regions of interest (ROI) were defined in the calcarine gyrus using anatomical labels from the TT_N27_EZ_ML mask, which is based on the macrolabels of the Statistical Parametric Mapping Anatomy Toolbox (Eickhoff et al., 2005) provided with AFNI package. To transfer the anatomical mask to subjects’ functional images, the template brain was transposed onto subjects’ skull-stripped anatomical images, anatomical and functional images were aligned, and the result was resampled to the resolution of the functional images. To compensate for imperfect alignment between the template and subjects’ brains and between anatomical and functional images, the ROIs from the calcarine gyri were edited to exclude ventricle and regions outside of the occipital area.
2-4. Response estimations
The voxel-wise response of the BOLD signal was estimated using general linear model (GLM) analysis. The design matrix of the GLM included six motion parameters (roll, pitch, yaw, and shifts in tree directions), low frequency components modeled by the third order polynomial for each run, and response models for each stimulus condition.
For the response model, we examined three types of HDR models. The first one was the canonical HDR function that was a mixture of two gamma functions used in the SPM (http://www.fil.ion.ucl.ac.uk/spm/). While this model is commonly used in an fMRI analysis, it cannot capture the variability of HDR shapes across conditions and voxels. If the decoding information is represented in this variability, we would not be able to utilize this information with the canonical HDR model. In the second model, to include the variability of hemodynamic response, we added the first- and second-order derivatives of the canonical HDR (Friston et al., 1998) as additional regressors. The inclusion of these derivatives enables the HDR model to fit more variable shapes than using only the canonical one (Henson et al., 2002). In the third model, to fully include the variability of response shapes into the decoding analysis, we deconvolved an event-related HDR for each condition in each voxel using the FIR model (Glover, 1999). For this model, the response for each condition at each time point was modeled by a delta function. The modeled time points were restricted within an interval of single trial (16 s or 12 s) to avoid co-linearity between regressors.
We used a t value of the model fit as the response estimate for all models because the t value is more stable and often gives better decoding performances than the beta value (Misaki et al., 2010). For each stimulus condition, one value was taken with the canonical HDR model, three values were taken with the canonical HDR with derivatives model, and sixty four (for ITI = 16 s) or forty eight (for ITI = 12 s) values were taken with the FIR model in each voxel. The GLM analysis was performed for each run independently to obtain multiple independent response data, which was used for the cross-validation in the decoding analysis described below.
2-5. Evaluating sensitivity of event-related responses to the stimulus conditions
To investigate whether the HDR shape is sensitive to the stimulus timing differences, one-way analysis of variance (ANOVA) was performed for the FIR-deconvolved response with the stimulus condition as an independent variable. Because the number of time points of the event-related response is larger than the number of samples, the response time points cannot be used as the independent variable. Instead, the ANOVA was performed in each time point independently and the F values of all time points were summed up in each voxel. Although this measure has no statistical meaning, it can indicate the degree of the difference in response shapes between stimulus conditions. This measure was not used for any statistical testing but used only for finding representative voxels with large difference in response shape.
2-6. Decoding analysis
The support vector machine (SVM) classification analysis was applied for the response values within the ROI of the calcarine region. The LIBLINEAR library was used with L2-regularized L2-loss support vector classification (Fan et al., 2008), and C parameter was fixed to 1. Seven contrasts were tested in this study; Lmono:Rmono, L-R500:R-L500, L-R500:LRbin, R-L500:LRbin, L-R100:R-L100, L-R100:LRbin, and R-L100:LRbin.
Decoding performances were evaluated using the leave-one-run-out cross-validation (Bishop, 2007; Misaki et al., 2010; Mitchell, 1997); responses in seven runs were used to train the classifiers, and the remaining run was used to test performance. The average test accuracy across cross-validation folds was evaluated for each subject. Note that the response estimation was performed within each run independently, so that the classifier was tested with a fully independent data for the training. In addition, the region of interest was defined anatomically independent of functional response, which ensures that the test score is free from a circular analysis (Kriegeskorte et al., 2009).
Significance of mean decoding accuracy across subjects was examined by the one-sample t test. The effects of down-sampling and spatial smoothing on the decoding accuracies were examined with the Friedman test (Demšar, 2006).
2-7. Dimensionality reduction with the recursive feature elimination
For the FIR-deconvolved response estimate, we also applied recursive feature elimination (RFE) (De Martino et al., 2008) for dimensionality reduction. While the FIR deconvolution can capture the variability of HDR shapes, its dimensionality was very large and included noisy variables. This large dimensionality with noisy variables can cause an over-fitting problem; the classifier is adapted to a specific noise in the training data and cannot be generalized to the test data. Dimensionality reduction with RFE could reduce the impact of this problem.
In the RFE, weight values of SVM were used to select the informative features for classification. SVM was applied for all the variables at first, and the variables whose absolute weights were small were eliminated. Then the SVM was applied to the reduced dimensionality data again. This procedure was repeated to search for the variable set giving the best classification performance.
RFE was applied only for the training dataset with the second-level cross-validation; six runs were used to train the classifier and one run was used to evaluate the performance. Average weight values across the second-level cross-validation folds were used to choose the eliminated variables; 10 % of remaining variables were eliminated at each step. The best-performing variable set in the second-level cross-validation was used as the optimal set to train the classifier in the first-level cross-validation (seven training runs were used). The test performance was evaluated by the test dataset with a reduced dimensionality. Note that the test dataset therefore was not used for the variable selection.
2-8. A priori feature selection
Even with the RFE, we might not be able to improve the decoding performance since feature selection is a difficult problem with a small sample size (Chu et al., 2012). In addition to the application of RFE, therefore, we extracted four response features from the FIR-deconvolved response for testing their decoding performances (Fig. 2): 1. The positive peak amplitude, 2. The positive or negative peak amplitude, 3. The time to peak (TTP), and 4. The full width at half-maximum response (FWHM).
Figure 2.
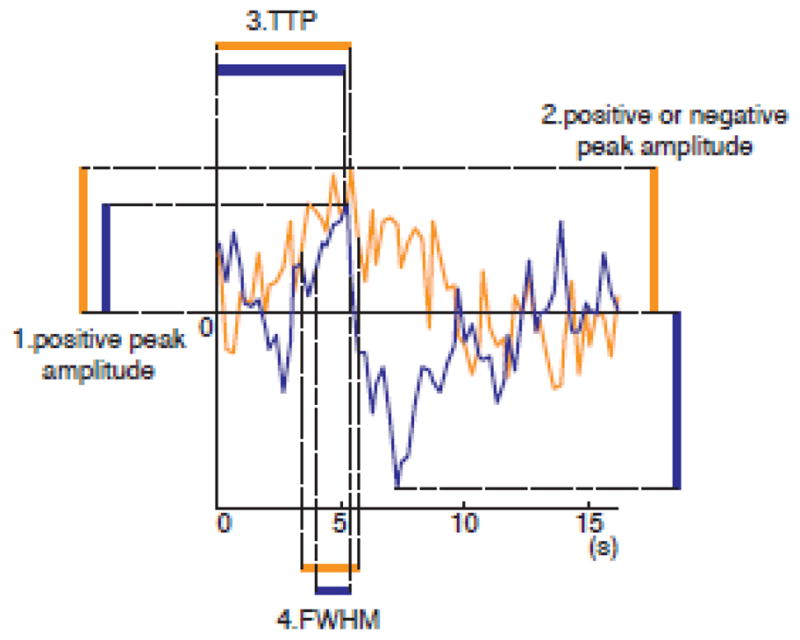
Schematic diagram of response characteristics of event-related HDR. Two lines (orange and blue) show the time course of event-related responses for two different conditions in one voxel. 1. The positive peak amplitude was defined as the response at the maximum amplitude point of the event-related response. 2. The positive or negative peak amplitude was defined as the response at absolute maximum point, which is positive value for the first condition (orange line), and the negative value for the second (blue line) condition. 3. The time-to-peak (TTP) was defined as the duration until the response reaches the positive peak point from the onset of the condition. 4. The full-width of half maximum (FWHM) response was defined as the duration of the response in which response was higher than the half maximum amplitude.
The first, the positive peak amplitude, was the value of the deconvolved event-related response at the peak time point. The time point of positive peak was determined from the average of the deconvolved responses across training runs for each stimulus condition in each voxel. While we used the same time point as the peak time in all runs, the response values were taken from the responses of each run so that the values were variable across runs.
The second, the positive or negative peak amplitude, was the response value at the point of absolute maximum. In Fig. 2, for example, the absolute maximum is the same as the positive peak for the response of the first condition (orange line), whereas the negative peak is the absolute maximum for the second condition (blue line). In this case, response of this voxel was the positive value for the first condition and the negative value for the second condition. Note that we used only one point of the response (not the difference between the two points of positive and negative peak) as an HDR characteristic.
Whether positive or negative peak is the absolute maximum depends on the baseline (zero level) of the response. Here, we used the average of the fitted response time courses for all conditions within an individual run as the baseline for each voxel. The positive or negative peak time was determined from the average response across training runs for each stimulus condition in each voxel. We hypothesized that the inclusion of negative response might help differentiate the HDR characteristics across stimulus conditions.
The third and fourth were the TTP and the FWHM of the FIR-deconvolved response. TTP was evaluated as the time to a positive peak point in each run. FWHM was the span (unit of TR) of responses whose amplitude was higher than the half of the maximum response.
3. Results
3-1. Event-related response differences across the stimulus conditions
Fig. 3 shows the event-related responses at voxels with large accumulated F values for one representative subject and the maps of accumulated F values. The values in the event-related response plots were the estimates of the FIR model (t value) averaged across runs. Thin dotted lines show the range of one standard error of the means across runs. For evaluating the accumulated F value, ANOVA was performed for the main effect of Lmono and Rmono in Fig. 3A, LRbin, L-R500, and R-L500 in Fig. 3B, and LRbin, L-R100, and R-L100 in Fig. 3C. The selected voxels had the largest F values within the ROI and were at least 8 mm apart from each other to display the variety of HDR shapes. The same plots for the other subjects are shown in Fig. S1 in the supplementary material.
Figure 3.

Maps of accumulated F values across all time points of event-related response for the main effect of Lmono and Rmono (A), LRbin, L-R500, and R-L500 (B), and LRbin, L-R500, and R-L500 (C). Event-related responses at voxels with largest accumulated F values were shown in the lower rows in each panel. The selected voxels were at least 8 mm apart from each other to display the variety of HDR shapes. The solid lines show the mean response estimates across runs and the thin dotted lines show the standard error of mean across runs. The digits on the map indicate the positions of the voxels selected to show their event-related responses.
The event-related response shapes were variable across stimulus conditions, voxels, and subjects. The timing difference of the stimulation was not necessarily seen as a corresponding phase shift or prolonged response duration of HDR. At voxel 5 in Fig. 3B, for example, a 500-ms onset difference of ocular dominance activation was observed as a difference of peak amplitudes; LRbin had lower amplitude than L-R500 and R-L500. At voxel 6 in Fig. 3B, the difference can be seen in response amplitude, durations, and TTP; LRbin had lower amplitude and shorter FWHM than L-R500 and R-L500, and L-R 500 and R-L500 had different TTP and FWHM. The difference also can be seen in the size of undershoot as in the voxel 10 for the 100-ms onset difference and in the voxels 3 and 4 for the difference of monocular stimulations.
To investigate whether these differences of HDR could be utilized to discriminate stimulus conditions in the MVPA, we performed a decoding in the next analysis.
3-2. Decoding with canonical HDR, canonical HDR with derivatives, and FIR response estimates
Fig. 4 shows the mean decoding accuracies across subjects and their standard errors of mean for the response estimates of the canonical HDR, the canonical HDR with derivatives, and the deconvolved HDR with FIR model. For these decoding, all the voxels in the ROI were used as input for the analysis. The figure also shows the results of RFE for the FIR-deconvolved response (FIR with RFE). Fig. 4A shows the average results of all 12 subjects. The results of the subject groups with different ITIs (16s and 12s) were averaged in this figure because no systematic difference between the groups was observed. Fig. 4B shows the average results of the six subjects who performed the conditions of 100-ms onset difference.
Figure 4.

Mean decoding accuracies and their standard errors across twelve subjects (A) and across six subjects (B) for the response estimates with the canonical HDR model and Finite Impulse Response (FIR) models. The results of the Recursive Feature Elimination (RFE) for the FIR estimated responses are also shown. No result was significantly higher than the chance level (50 %) at p < 0.05 with one-sample t test.
The decoding accuracies for the canonical HDR and the FIR were not significantly different from the chance level (50 %) in all contrasts. Even when the RFE was used for feature selection, the decoding accuracies were still as low as the chance level. The decoding accuracy for the canonical HDR with derivatives was significantly higher than the chance level (p < .05) only at the contrast of L-R500:LRbin and R-L500:LRbin.
3-3. Decoding with a priori feature selection
Fig. 5 shows the mean decoding accuracies across subjects for the extracted response features from the FIR-deconvolved HDR. Statistically significant performance was found with the positive peak amplitude at the contrasts of Lmono:Rmono, L-R500:LRbin, and R-L500:LRbin. TTP and FWHM had statistically significant performance only at the contrast of L-R100:R-L100 and R-L500:LRbin respectively.
Figure 5.

Mean decoding accuracies and their standard errors across twelve subjects (A) and across six subjects (B) for the extracted features of hemodynamic response shape. The features were the positive peak amplitude (Peak (pos)), positive or negative peak amplitude (Peak (pos/neg)), time to peak (TTP), and full-width at half-maximum of response (FWHM). These response characteristics were extracted from deconvolved HDR. Decoding accuracies for positive or negative peak amplitude from the fitted response of the canonical HDR with derivatives were also shown (HDR+Deriv. fitted Peak (pos/neg)). Asterisk (*) and double asterisk (**) indicate that the accuracy is significantly higher than the chance level (50 %) by p < 0.05 and p < 0.01 respectively with one-sample t test.
In contrast to unstable performances of the above-mentioned response features, the use of the positive or negative peak amplitude yielded extremely high and significant decoding accuracies for all contrasts. With this response value, even the 100 ms onset difference of ocular dominance activation could be reliably decoded, even though the temporal sampling interval of the BOLD signal was only 250 ms.
To investigate whether the positive or negative peak amplitude measure can work also for the fitted response of the canonical HDR with derivatives, we extracted the positive or negative peak amplitude from the fitted response of this model. The results are shown as ‘HDR+Deriv. fitted Peak (pos/neg)’ in Fig. 5. While its decoding performance was lowere than using the deconvolved response, their accuracies were significantly high for all the decoding contrasts.
3-4. The effects of spatial and temporal sampling frequencies on the decoding
To further investigate the effects of spatial and temporal frequencies of functional imaging on decoding performance, we applied the same decoding analysis to the temporally down-sampled and spatially smoothed datasets. Because robust decoding performance was found only with the positive or negative peak amplitude, the effects were evaluated only for this response measure.
Fig. 6 and 7 shows the effects of temporal down-sampling and spatial smoothing respectively on the decoding accuracies with the positive or negative peak amplitude of the deconvolved HDR. No significant effects of down-sampling and spatial smoothing were found by the Friedman test (Demšar, 2006).
Figure 6.
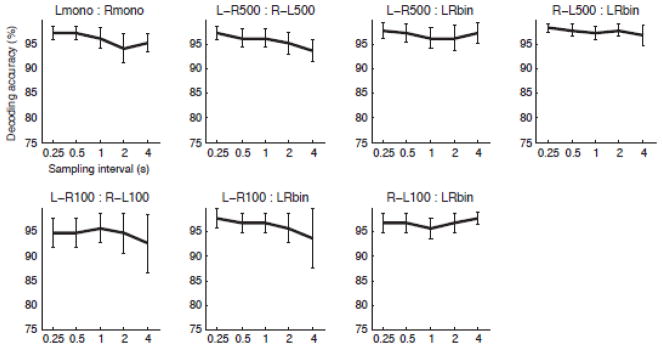
The effect of down sampling on decoding accuracies with the positive or negative peak amplitude of HDR. Mean accuracies and their standard error across twelve subjects (upper row) or across six subjects (lower row) are shown. Double asterisk (**) indicates the effect of down sampling is significant by p < 0.01 with the Friedman test.
Figure 7.
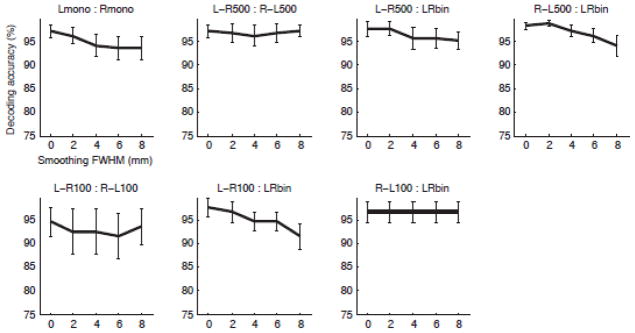
The effect of spatial smoothing on the decoding accuracies with the positive or negative peak amplitude of HDR. Conventions are the same as in Figure 5.
3-5. Informative response shapes for decoding
Fig. 8 shows the event-related responses for the voxels with the largest absolute SVM weight from one representative subject (the equivalent figures for the other subjects are shown in Fig. S2 in the supplementary material). Large absolute SVM weight means high responsibility for the decoding so that the responses in these voxels are thought to mostly contribute to the successful decoding. The horizontal dashed-lines in the response plots indicate the positive or negative peak values used as inputs for the decoding.
Figure 8.

Maps of the weight of support vector machine classification for Lmono:Rmono (A), L-R500:R-L500 (B), L-R500:LRbin (C), and R-L500:LRbin (D) for one representative subject (Subject 12 of Fig. S2 in the supplementary material). Event-related responses at voxels with largest absolute weight values were shown in the lower rows in each panel. The selected voxels were at least 8 mm apart from each other to display the variety of HDR shapes. The solid lines show the mean response estimates across runs and the thin dotted lines show the standard error of mean across runs. The digits on the map indicate the positions of the voxels selected to show their event-related responses. The horizontal dotted lines in the event-related response plot are the positive or negative peak value used for the decoding.
Most of the voxels with the largest absolute SVM weight had a positive peak value for one condition and a negative peak value for the other. While the event-related responses for different conditions were similar with each other, a small difference at peak point was enhanced by choosing the positive or negative peak values as the representative value. Voxel 5 in Fig. 8, for example, had similar positive peak amplitudes for L-R500 and R-L500, while the undershoot amplitudes are different from each other. In this voxel, the positive peak was the absolute maximum in R-L500, while the negative peak at undershoot was the absolute maximum in L-R500 condition. This flip of sign for the picked response values enhanced the contrast of response values, in turn, allowing for the high decoding accuracies.
4. Discussion
4-1. Decoding timing difference of ocular dominance stimulations
The HDR in the human visual cortex can reveal subtle timing differences of ocular dominance column stimulation. The relationships between the stimulus condition and response shape, while consistent within voxels, were highly complex and different across voxels and subjects, so that it was difficult to estimate an absolute timing of neural activation from the observed hemodynamic responses at each voxel. However, the HDR shape was robustly linked to neural activation, allowing the use of the event-related HDR features to discriminate a difference of onset timings in neural activations.
Decoding for the multi-voxel responses estimated with the canonical HDR model and the FIR-deconvolved HDR, did not yield high decoding accuracies. The low performance of the canonical HDR is likely due to an inability in capturing the differences in HDR shapes across voxels that could be informative for discriminating the conditions. The deficient performance of the FIR-deconvolved responses could be due to its large dimensionality with many noisy time points causing an over-fitting problem in a multivariate classification analysis. The RFE with FIR did not improve the decoding performance. This result indicates the difficulty of extracting useful information for decoding with a statistical feature selection method from a limited number of samples (Chu et al., 2012).
The canonical HDR with two derivatives had better decoding performance than using only the canonical HDR and the FIR-deconvolved responses. This model had more flexibility to fit the variable HDR while keeping data dimensionality small. While significant performance of this model was restricted in a few decoding contrasts, the result suggests that variability in the HDR shape had information for decoding. In fact, the observations in Fig. 3 indicate that there is usable information in the differences of HDR shapes to decode the timing difference of ocular dominance activations.
To find an informative feature of HDR for decoding the timing difference of ocular dominance stimulations, four response characteristics of HDR were tested; positive peak amplitude, positive or negative peak amplitude, TTP, and FWHM. In result, we found the positive or negative peak amplitude yielded very high decoding accuracies. The observation of the event-related HDR (Fig. 3 and Fig. S1 in the supplementary material) suggests that the positive peak amplitude, TTP, and FWHM could also be informative for discriminating the stimulus conditions. However, decoding scores for these response features did not yield as high accuracies as the positive or negative peak amplitude. The lower performances for the TTP and FWHM might imply the difficulty of using a timing property of HDR as a reliable measure, because it could fluctuate considerably unless averaging across voxels and runs. For the peak amplitude estimation, an average HDR across training runs was used to estimate the peak time and the same time point was used for all runs to obtain the amplitude estimates. This enables us to robustly estimate the informative time point.
While the amplitude measures yielded better decoding scores, using only the positive peak was not sufficient to achieve a robust decoding performance. Including the negative peak amplitude was needed to achieve significantly high decoding accuracies. The plots of informative HDR for decoding (Fig. 8) revealed that taking negative peak as a response characteristic enhanced the contrast of responses. In most informative voxels, event-related response time courses between conditions were very similar, but selecting the positive or negative peak amplitude could effectively magnify a small difference between responses, resulting in very high performance of decoding.
Although the negative response of the BOLD signal does not always reflect the magnitude of neural activation (Pasley et al., 2007; Schridde et al., 2008; Seiyama et al., 2004), using the negative value enhanced contrasting different HDR shapes, contributing to the better decoding performances.
4-2. Complex spatiotemporal relationships between stimulus timing and HDR
One of the interesting findings in this study was that we could decode the 100-ms onset differences of ocular dominance activations even though the temporal sampling rate of the BOLD signal was 250 ms and the sampling size of functional imaging (2 × 2 × 3 mm) was larger than the width of ocular dominance columns (< 0.7 mm; Adams et al. (2007)). Further examination of the effect of sampling frequencies on the decoding performances revealed that temporal down-sampling and spatial smoothing did not reduce the decoding accuracies.
No effect of temporal down sampling was expected from the slow temporal profile of the hemodynamic response (Robson et al., 1998). Significant decoding accuracies with peak positive/negative amplitude for the fitted response of HDR and derivatives model also indicate that a low temporal frequency model is sufficient to capture the characteristic of hemodynamic response shape. Using a model-based regressor might enable us to apply the current analysis to the rapid event-related design experiments if the spatiotemporal BOLD response still has information when multiple responses are overlapped in time.
What is interesting here is that such slow response still has information for discriminating millisecond stimulus timings. While this possibility has been shown in the previous studies (Grinband et al., 2008; Hernandez et al., 2002; Menon et al., 1998a; Menon and Kim, 1999; Menon et al., 1998b; Ogawa et al., 2000; Robson et al., 1998; Tomatsu et al., 2008), the current result is the first to demonstrate that the multivoxel response pattern of hemodynamic responses has information even if the sampling rate is much slower than the events for decoding.
Spatial smoothing also did not affect the decoding performance. This fact might raise a question that the source of decoding information is not columnar responses but biased spatial distribution of ocular dominance columns. It has been shown that left- and right-eye dominance columns are not equally distributed in the region of peripheral (> 15°) visual field (Adams et al., 2007); right-eye column is denser than left-eye column in the left hemisphere and vice versa in the right hemisphere. The map of ocular dominance contrast (Fig. S3 in the supplementary material), however, did not show such pattern. In addition, the absolute weight size of SVM classifier was not correlated with the size of ocular dominance response contrast except in the decoding of Lmono:Rmono (Table S1 in the supplementary material). These indicate that the high accuracies of timing decoding were not due to a biased distribution of ocular dominance responses.
The previous study (Op de Beeck, 2010) has also shown that spatial smoothing did not affect accuracy of decoding columnar-level responses. This fact, however, does not necessarily imply that the decoding information is not from column-size responses. Indeed some studies (Gardner, 2010; Kriegeskorte et al., 2010; Shmuel et al., 2010) suggested that columnar-size neural responses can be represented as a low spatial frequency pattern of the BOLD signal due to spread of blood flow. Actually, the fundamental mechanism allowing hyper-spatial-resolution decoding (discriminating columnar-level activations with large-sized voxels) is still controversial and various possible models have been proposed (Chaimow et al., 2011; Freeman et al., 2011; Gardner, 2010; Kamitani and Sawahata, 2010; Kriegeskorte et al., 2010; Op de Beeck, 2010; Shmuel et al., 2010; Swisher et al., 2010).
We observed that the temporal difference of stimulus presentation was reflected in various HDR shapes. The response for the monocular stimulations (Lmono and Rmono) also implies a complex relationship between the neural activation and the HDR. While the two monocular stimulations did not have a temporal difference, we observed different response time courses for these conditions (Fig. 3A). These results suggest that there could be a complex spatiotemporal relationship between neural activation and multi-voxel pattern of HDR. The complex relationship between the neural activation and the BOLD signal has been suggested by Kriegeskorte et al. (2010) as the complex spatiotemporal filter model. This model considers that HDR at each voxel reflects not only the neural activations within the voxel, but also is affected by HDRs in surrounding voxels due to the spread of blood flow and thus oxygenation. Inhomogeneous flow speed, direction, as well as oxygen extraction rate across voxels would result in a variety of HDR shapes across voxels. This means that even when a neural activation within a voxel is the same, its HDR could be variable depending on the neural activations in surrounding voxels. While this variability is nuisance noise for evaluating activation in each voxel independently, we suggest that it is informative for decoding a population activation pattern using the MVPA.
As shown in the simulation of Kriegeskorte et al. (2010), the contrast of columnar-level neural activations could be enhanced by a complex spatiotemporal interaction across HDRs of multiple voxels. The difference of spatial patterns of neural activations could also be represented as a different time courses of HDR because the different spatial activations could elicit different flow patterns of BOLD signal in a local region. This notion is consistent with the observation in the current experiment that the monocular stimulations without timing difference elicited different time courses of HDR (Fig. 3A).
In addition, based on this model, the timing difference of neural activations could be represented as a difference of peak response amplitude of HDR. As shown in the previous studies (Grinband et al., 2008; Hernandez et al., 2002; Menon et al., 1998a; Menon and Kim, 1999; Menon et al., 1998b; Ogawa et al., 2000; Robson et al., 1998), HDR is sensitive to subsecond timing difference of neural activations. The timing difference of HDR at each voxel could change the spatiotemporal flow pattern of BOLD signal in a local region, resulting in an amplitude difference of HDR in multiple voxels due to complex spatiotemporal interactions across voxels.
4-3. Limitations of the analysis
Our results demonstrated a hyper-resolution spatiotemporal decoding; activations in ocular dominance columns (< 0.7 mm) with 100-ms onset difference could be discriminated from the BOLD signal with 250 ms TR and 2 × 2 × 3 mm voxels. This result, however, does not indicate that we could detect absolute timing of neural activations with high spatiotemporal resolution from the BOLD signal. What we demonstrated here was the ability to detect a difference in patterns of neuronal population activation with subtle timing difference, and not to identify the timing of neural activation in each column; the onset timing of neural activations or stimulations could not be reconstructed.
Uncertainty of what neural activation contributed to decoding is also the limitation. We assumed that monocular visual stimulation elicits activation of ocular dominance columns with the corresponding timing. However, unknown neural activation that is not linked to stimulus timings might exist. In the current analysis, it is difficult to examine such confounding effect, because the analysis cannot identify the neural activations corresponding to the stimulus conditions.
Furthermore, the current decoding analysis did not necessarily utilize the magnitude of neural activation in each voxel. High decoding performance was achieved with the positive or negative peak amplitude, which does not necessarily reflect the magnitude of neural activation in each voxel. The current multi-voxel pattern analysis, instead, utilized the byproduct of neuronal population activation seen in the multi-voxel pattern of HDR, possibly resulting from complex spatiotemporal interactions between HDRs across multiple voxels.
While there is uncertainty about the interpretation of the relationships between the utilized signal and neural activations, the discrimination of the multi-voxel pattern related to the stimulus condition is sufficiently beneficial for functional neuroimaging studies. Even if we could identify a neural activation, it does not necessarily imply its function by itself. The function of neural activation has to be evaluated from its relationship to a stimulus or task. Finding the relationship between the multi-voxel response pattern and stimulus condition can imply the function of neural activation.
5. Conclusion and future directions
With BOLD fMRI, it is possible to discriminate 100-ms onset difference of ocular dominance stimulations even when the spatial and temporal resolutions of the BOLD measurement were less than the decoded information. With the positive or negative peak amplitude of the deconvolved event-related response, MVPA can extract information of neuronal population activation resided in the variable HDR shapes in multiple voxels.
While keeping in mind the limitations of the current analysis method, this result is still promising in BOLD functional neuroimaging. Such analysis can be employed to investigate whether a certain region has information about a subtle timing difference of stimulations as well as to investigate information resided in a spatiotemporal pattern of neuronal population activation.
There are many animal studies indicating that timing of neural activation encodes information about a stimulus that cannot be seen in the firing rate (Arabzadeh et al., 2006; Bair, 1999; deCharms and Merzenich, 1996; Matsumoto et al., 2005; Montemurro et al., 2008; Optican and Richmond, 1987; Reich et al., 2001; Singer, 1999; Sugase et al., 1999; Vaadia et al., 1995; Wyss et al., 2003). Such information, however, is usually encoded in a millisecond-order difference across single neurons, so that it had been thought impossible to decode with BOLD fMRI. The current results, however, suggest that such a short timing difference of small-sized neural activations might be represented as the detectable BOLD signal changes in a multi-voxel response pattern of variable HDR. While it is still unclear how high frequency change of neural activation can be represented in the multi-voxel spatiotemporal pattern of HDR, the current results demonstrate the possibility to investigate neural activations of high spatiotemporal frequency with BOLD signal.
We have demonstrated with our analysis that BOLD signal has more useful information than previously thought. MVPA with a deconvolved HDR enables us to utilize this unused information to broaden the scope of application of the BOLD fMRI.
Supplementary Material
Highlights.
Millisecond onset differences of ocular dominance stimulations were decoded in fMRI.
Hemodynamic response (HDR) was sensitive to 100-ms timing difference of stimuli.
HDR shapes corresponded to stimulus timings in complex ways.
Multi-voxel pattern of peak amplitudes of HDR yielded high decoding scores.
100ms onset difference of ocular dominance responses can be decoded from BOLD signal
Acknowledgments
This study was supported by the Intramural Research Program of the National Institutes of Health, National Institute of Mental Health (NIMH). This study utilized the high performance computational capabilities of the Biowulf Linux cluster at the National Institutes of Health, Bethesda, MD (http://biowulf.nih.gov).
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- Adams DL, Sincich LC, Horton JC. Complete pattern of ocular dominance columns in human primary visual cortex. J Neurosci. 2007;27:10391–10403. doi: 10.1523/JNEUROSCI.2923-07.2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Arabzadeh E, Panzeri S, Diamond ME. Deciphering the spike train of a sensory neuron: counts and temporal patterns in the rat whisker pathway. J Neurosci. 2006;26:9216–9226. doi: 10.1523/JNEUROSCI.1491-06.2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bair W. Spike timing in the mammalian visual system. Curr Opin Neurobiol. 1999;9:447–453. doi: 10.1016/S0959-4388(99)80067-1. [DOI] [PubMed] [Google Scholar]
- Bishop CM. Pattern Recognition and Machine Learning. Springer; New York: 2007. [Google Scholar]
- Chaimow D, Yacoub E, Ugurbil K, Shmuel A. Modeling and analysis of mechanisms underlying fMRI-based decoding of information conveyed in cortical columns. NeuroImage. 2011;56:627–642. doi: 10.1016/j.neuroimage.2010.09.037. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chu C, Hsu AL, Chou KH, Bandettini P, Lin C. Does feature selection improve classification accuracy? Impact of sample size and feature selection on classification using anatomical magnetic resonance images. NeuroImage. 2012;60:59–70. doi: 10.1016/j.neuroimage.2011.11.066. [DOI] [PubMed] [Google Scholar]
- Cox RW. AFNI: software for analysis and visualization of functional magnetic resonance neuroimages. Comput Biomed Res. 1996;29:162–173. doi: 10.1006/cbmr.1996.0014. [DOI] [PubMed] [Google Scholar]
- De Martino F, Valente G, Staeren N, Ashburner J, Goebel R, Formisano E. Combining multivariate voxel selection and support vector machines for mapping and classification of fMRI spatial patterns. NeuroImage. 2008;43:44–58. doi: 10.1016/j.neuroimage.2008.06.037. [DOI] [PubMed] [Google Scholar]
- de Zwart JA, Silva AC, van Gelderen P, Kellman P, Fukunaga M, Chu RX, Koretsky AP, Frank JA, Duyn JH. Temporal dynamics of the BOLD fMRI impulse response. NeuroImage. 2005;24:667–677. doi: 10.1016/j.neuroimage.2004.09.013. [DOI] [PubMed] [Google Scholar]
- deCharms RC, Merzenich MM. Primary cortical representation of sounds by the coordination of action-potential timing. Nature. 1996;381:610–613. doi: 10.1038/381610a0. [DOI] [PubMed] [Google Scholar]
- Demšar J. Statistical Comparisons of Classifiers over Multiple Data Sets. Journal of Machine Learning Research. 2006;7:1–30. [Google Scholar]
- Eickhoff SB, Stephan KE, Mohlberg H, Grefkes C, Fink GR, Amunts K, Zilles K. A new SPM toolbox for combining probabilistic cytoarchitectonic maps and functional imaging data. NeuroImage. 2005;25:1325–1335. doi: 10.1016/j.neuroimage.2004.12.034. [DOI] [PubMed] [Google Scholar]
- Fan RE, Chang KW, Hsieh CJ, Wang XR, Lin CJ. LIBLINEAR: A library for large linear classification. Journal of Machine Learning Research. 2008;9:1871–1874. [Google Scholar]
- Freeman J, Brouwer GJ, Heeger DJ, Merriam EP. Orientation decoding depends on maps, not columns. J Neurosci. 2011;31:4792–4804. doi: 10.1523/JNEUROSCI.5160-10.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Friston KJ, Josephs O, Rees G, Turner R. Nonlinear event-related responses in fMRI. Magn Reson Med. 1998;39:41–52. doi: 10.1002/mrm.1910390109. [DOI] [PubMed] [Google Scholar]
- Gardner JL. Is cortical vasculature functionally organized? NeuroImage. 2010;49:1953–1956. doi: 10.1016/j.neuroimage.2009.07.004. [DOI] [PubMed] [Google Scholar]
- Glover GH. Deconvolution of impulse response in event-related BOLD fMRI. NeuroImage. 1999;9:416–429. doi: 10.1006/nimg.1998.0419. [DOI] [PubMed] [Google Scholar]
- Grinband J, Wager TD, Lindquist M, Ferrera VP, Hirsch J. Detection of time-varying signals in event-related fMRI designs. NeuroImage. 2008;43:509–520. doi: 10.1016/j.neuroimage.2008.07.065. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Haynes JD, Rees G. Predicting the orientation of invisible stimuli from activity in human primary visual cortex. Nature Neuroscience. 2005;8:686–691. doi: 10.1038/nn1445. [DOI] [PubMed] [Google Scholar]
- Haynes JD, Rees G. Decoding mental states from brain activity in humans. Nature Reviews Neuroscience. 2006;7:523–534. doi: 10.1038/nrn1931. [DOI] [PubMed] [Google Scholar]
- Henson RNA, Price CJ, Rugg MD, Turner R, Friston KJ. Detecting latency differences in event-related BOLD responses: application to words versus nonwords and initial versus repeated face presentations. NeuroImage. 2002;15:83–97. doi: 10.1006/nimg.2001.0940. [DOI] [PubMed] [Google Scholar]
- Hernandez L, Badre D, Noll D, Jonides J. Temporal sensitivity of event-related fMRI. NeuroImage. 2002;17:1018–1026. [PubMed] [Google Scholar]
- Hirano Y, Stefanovic B, Silva AC. Spatiotemporal evolution of the functional magnetic resonance imaging response to ultrashort stimuli. Journal of Neuroscience. 2011;31:1440–1447. doi: 10.1523/JNEUROSCI.3986-10.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kamitani Y, Sawahata Y. Spatial smoothing hurts localization but not information: Pitfalls for brain mappers. NeuroImage. 2010;49:1949–1952. doi: 10.1016/j.neuroimage.2009.06.040. [DOI] [PubMed] [Google Scholar]
- Kamitani Y, Tong F. Decoding the visual and subjective contents of the human brain. Nat Neurosci. 2005;8:679–685. doi: 10.1038/nn1444. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kriegeskorte N, Bandettini P. Analyzing for information, not activation, to exploit high-resolution fMRI. NeuroImage. 2007;38:649–662. doi: 10.1016/j.neuroimage.2007.02.022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kriegeskorte N, Cusack R, Bandettini P. How does an fMRI voxel sample the neuronal activity pattern: Compact-kernel or complex spatiotemporal filter? NeuroImage. 2010;49:1965–1976. doi: 10.1016/j.neuroimage.2009.09.059. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kriegeskorte N, Simmons WK, Bellgowan PS, Baker CI. Circular analysis in systems neuroscience: the dangers of double dipping. Nat Neurosci. 2009;12:535–540. doi: 10.1038/nn.2303. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lee AT, Glover GH, Meyer CH. Discrimination of large venous vessels in time-course spiral blood- oxygen-level-dependent magnetic-resonance functional neuroimaging. Magnetic Resonance in Medicine. 1995;33:745–754. doi: 10.1002/mrm.1910330602. [DOI] [PubMed] [Google Scholar]
- Matsumoto N, Okada M, Sugase-Miyamoto Y, Yamane S, Kawano K. Population dynamics of face-responsive neurons in the inferior temporal cortex. Cerebral Cortex. 2005;15:1103–1112. doi: 10.1093/cercor/bhh209. [DOI] [PubMed] [Google Scholar]
- Menon RS, Gati JS, Goodyear BG, Luknowsky DC, Thomas CG. Spatial and temporal resolution of functional magnetic resonance imaging. Biochemistry and cell biology. 1998a;76:560–571. doi: 10.1139/bcb-76-2-3-560. [DOI] [PubMed] [Google Scholar]
- Menon RS, Kim SG. Spatial and temporal limits in cognitive neuroimaging with fMRI. Trends Cogn Sci. 1999;3:207–216. doi: 10.1016/s1364-6613(99)01329-7. [DOI] [PubMed] [Google Scholar]
- Menon RS, Luknowsky DC, Gati JS. Mental chronometry using latency-resolved functional MRI. Proceedings of the National Academy of Sciences of the United States of America. 1998b;95:10902–10907. doi: 10.1073/pnas.95.18.10902. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Misaki M, Kim Y, Bandettini PA, Kriegeskorte N. Comparison of multivariate classifiers and response normalizations for pattern-information fMRI. NeuroImage. 2010;53:103–118. doi: 10.1016/j.neuroimage.2010.05.051. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mitchell T. Machine Learning. McGraw Hill; New York: 1997. [Google Scholar]
- Montemurro MA, Rasch MJ, Murayama Y, Logothetis NK, Panzeri S. Phase-of-firing coding of natural visual stimuli in primary visual cortex. Curr Biol. 2008;18:375–380. doi: 10.1016/j.cub.2008.02.023. [DOI] [PubMed] [Google Scholar]
- Norman KA, Polyn SM, Detre GJ, Haxby JV. Beyond mind-reading: multi-voxel pattern analysis of fMRI data. Trends Cogn Sci. 2006;10:424–430. doi: 10.1016/j.tics.2006.07.005. [DOI] [PubMed] [Google Scholar]
- Ogawa S, Lee TM, Stepnoski R, Chen W, Zhu XH, Ugurbil K. An approach to probe some neural systems interaction by functional MRI at neural time scale down to milliseconds. Proceedings of the National Academy of Sciences of the United States of America. 2000;97:11026–11031. doi: 10.1073/pnas.97.20.11026. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Op de Beeck HP. Against hyperacuity in brain reading: Spatial smoothing does not hurt multivariate fMRI analyses? NeuroImage. 2010;49:1943–1948. doi: 10.1016/j.neuroimage.2009.02.047. [DOI] [PubMed] [Google Scholar]
- Optican LM, Richmond BJ. Temporal encoding of two-dimensional patterns by single units in primate inferior temporal cortex. III. Information theoretic analysis. J Neurophysiol. 1987;57:162–178. doi: 10.1152/jn.1987.57.1.162. [DOI] [PubMed] [Google Scholar]
- Pasley BN, Inglis BA, Freeman RD. Analysis of oxygen metabolism implies a neural origin for the negative BOLD response in human visual cortex. NeuroImage. 2007;36:269–276. doi: 10.1016/j.neuroimage.2006.09.015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Reich DS, Mechler F, Victor JD. Temporal coding of contrast in primary visual cortex: when, what, and why. J Neurophysiol. 2001;85:1039–1050. doi: 10.1152/jn.2001.85.3.1039. [DOI] [PubMed] [Google Scholar]
- Robson MD, Dorosz JL, Gore JC. Measurements of the Temporal fMRI Response of the Human Auditory Cortex to Trains of Tones. NeuroImage. 1998;7:185–198. doi: 10.1006/nimg.1998.0322. [DOI] [PubMed] [Google Scholar]
- Schridde U, Khubchandani M, Motelow JE, Sanganahalli BG, Hyder F, Blumenfeld H. Negative BOLD with large increases in neuronal activity. Cerebral Cortex. 2008;18:1814–1827. doi: 10.1093/cercor/bhm208. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Seiyama A, Seki J, Tanabe HC, Sase I, Takatsuki A, Miyauchi S, Eda H, Hayashi S, Imaruoka T, Iwakura T, Yanagida T. Circulatory basis of fMRI signals: Relationship between changes in the hemodynamic parameters and BOLD signal intensity. NeuroImage. 2004;21:1204–1214. doi: 10.1016/j.neuroimage.2003.12.002. [DOI] [PubMed] [Google Scholar]
- Shmuel A, Chaimow D, Raddatz G, Ugurbil K, Yacoub E. Mechanisms underlying decoding at 7 T: Ocular dominance columns, broad structures, and macroscopic blood vessels in V1 convey information on the stimulated eye. NeuroImage. 2010;49:1957–1964. doi: 10.1016/j.neuroimage.2009.08.040. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Singer W. Time as coding space? Curr Opin Neurobiol. 1999;9:189–194. doi: 10.1016/s0959-4388(99)80026-9. [DOI] [PubMed] [Google Scholar]
- Sugase Y, Yamane S, Ueno S, Kawano K. Global and fine information coded by single neurons in the temporal visual cortex. Nature. 1999;400:869–873. doi: 10.1038/23703. [DOI] [PubMed] [Google Scholar]
- Swisher JD, Gatenby JC, Gore JC, Wolfe BA, Moon CH, Kim SG, Tong F. Multiscale pattern analysis of orientation-selective activity in the primary visual cortex. Journal of Neuroscience. 2010;30:325–330. doi: 10.1523/JNEUROSCI.4811-09.2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tomatsu S, Someya Y, Sung YW, Ogawa S, Kakei S. Temporal feature of BOLD responses varies with temporal patterns of movement. Neuroscience Research. 2008;62:160–167. doi: 10.1016/j.neures.2008.08.003. [DOI] [PubMed] [Google Scholar]
- Vaadia E, Haalman I, Abeles M, Bergman H, Prut Y, Slovin H, Aertsen A. Dynamics of neuronal interactions in monkey cortex in relation to behavioural events. Nature. 1995;373:515–518. doi: 10.1038/373515a0. [DOI] [PubMed] [Google Scholar]
- Wyss R, Konig P, Verschure PF. Invariant representations of visual patterns in a temporal population code. Proc Natl Acad Sci U S A. 2003;100:324–329. doi: 10.1073/pnas.0136977100. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.