
Figure 2.

Identifying different modes of protein–DNA binding. A total of m models having 1 through m modes are learned from the input data. DNA sequences are shown in gray, the indicator vector 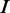 on the left of each sequence marks the mode to which it contributes. The motif logos displayed at the bottom correspond to the p300-bound sequences in HL1 cardiomyocytes (14). In the final step, the method reports three optimal partitions, which can be compared with motifs from literature.
on the left of each sequence marks the mode to which it contributes. The motif logos displayed at the bottom correspond to the p300-bound sequences in HL1 cardiomyocytes (14). In the final step, the method reports three optimal partitions, which can be compared with motifs from literature.